2. C++的编译/链接模型
C++的编译/链接模型
- 简单的加工模型
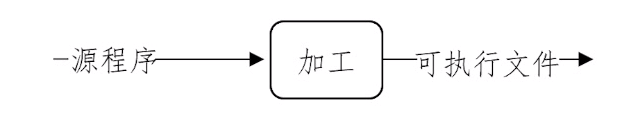
- 问题:无法处理大型程序
- 加工耗时较长
- 即使少量修改,也需要重新加工
- 解决方案:分块处理
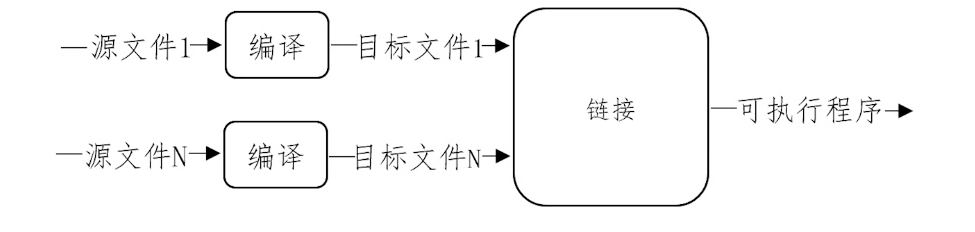
- 好处
- 编译消耗资源,但一次处理输入较少
- 链接程序较多,但处理速度较快
- 便于程序修改升级
- 由“分块处理”衍生出的概念
- 定义 / 声明
- 头文件 / 源文件
- 翻译单元
- 源文件 + 相关头文件(直接 / 间接)- 应忽略的预处理语句
- 一处定义原则:
- 程序级:一般函数
- 翻译单元级:内联函数、类、模板
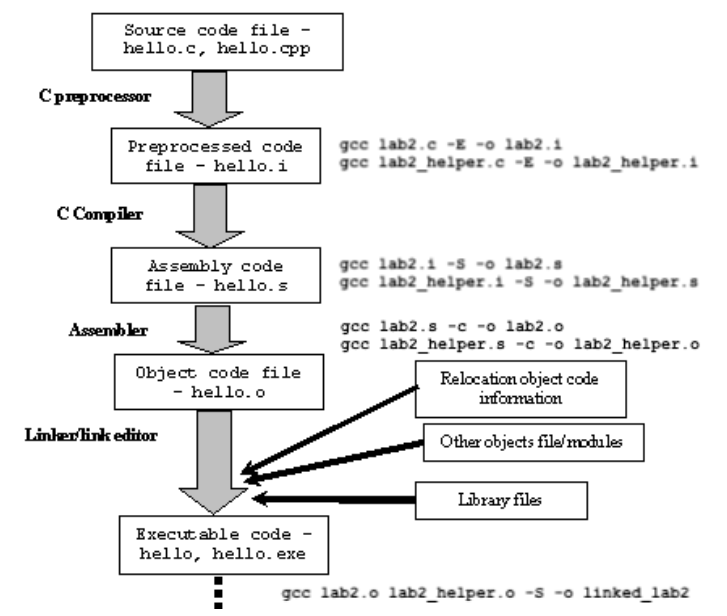
编译过程
预处理 --> 编译 --> 汇编 --> 链接假如我们的源文件名为
hello.cpp#include <iostream> int main(void)
{
std::cout << "Hello world!\n";
return 0;
}
- 预处理,生成预处理文件
hello.ig++ -E hello.c -o hello.i
- 编译,生成汇编文件
hello.sg++ hello.i -S -o hello.s
- 汇编,生成目标文件
hello.og++ hello.s -c -o hello.o
- 链接,将多个目标文件进行链接,生成可执行文件
hellog++ hello.o -s -o hello
然后执行可执行文件:
./hello
执行结果:
Hello world!
预处理
- 将源文件转换为翻译单元的过程
- 防止头文件被循环展开
#ifndef解决方案举一个循环定义的例子,目录结构和源码如下:
.
├── header1.h
├── header2.h
└── main.cpp
header1.h#include "header2.h" int fun();
header2.h#include "header1.h" int fun2();
main.cpp#include "header1.h" int main()
{ }
我们进行编译:
g++ -Wall -g main.cpp -o main
出错,如下:
In file included from header2.h:1,
from header1.h:1,
from header2.h:1,
from header1.h:1,
......
header1.h:1:21: error: #include nested depth 200 exceeds maximum of 200 (use -fmax-include-depth=DEPTH to increase the maximum)
1 | #include "header2.h"
|
如果是智能的编译器,现在会提示“嵌套层数太多”这种提示:
我们对上述代码添加如下语句:
header1.h#ifndef HEADER2
#define HEADER2
#include "header2.h"
int fun();
#endif
header2.h#ifndef HEADER2
#define HEADER2
#include "header1.h"
int fun2();
#endif
然后再进行编译,就不会出问题了。但是如果使用了 clangd 来做提示,它仍旧会出现错误提醒,这时候编译是没有问题的,但我们最好不要这样写代码,在这里也只是举个例子。
该解决方案的不足之处:
- 会写多余的代码;
- 由于宏取名(如
HEADER2)是随意的,如果发生名称冲突,导致程序出错;
#pragma once解决方案该方案更为优秀,原理为对展开进行计数,
progma once即为只允许展开一次,修改后的代码类似这样:header1.h#pragma once #include "header2.h" int fun();
这种处理方式比传统的
ifdef处理方式更好。
编译
将翻译单元转换为相应的汇编语言表示
编译优化
optimize.cppint main()
{
int res = 0;
for (int i = 0; i < 1000; ++i)
{
res += i;
}
return res;
}
上面的这段代码,编译器在编译期间是可以进行优化的,优化等级从O0-O3,另外还有Os, Ofast 等,O0表示没有任何优化,O3表示最高等级优化:
g++ -S -O0 optimize.cpp -o optimize.s
从简单的汇编代码行数中我们也能看出,编译优化后的汇编代码更短,执行效率更高。
更多关于编译优化的资料:
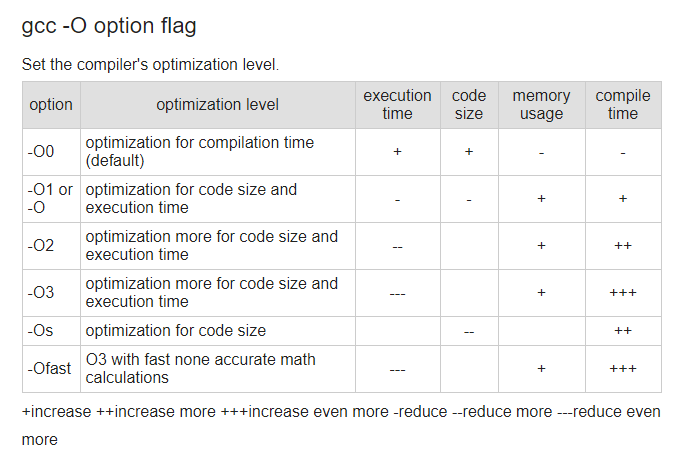
-O0:这个等级(字母“O”后面跟个零)关闭所有优化选项,也是 CFLAGS 或 CXXFLAGS 中没有设置-O等级时的默认等级。这样就不会优化代码,这通常不是我们想要的。-O1:这是最基本的优化等级。编译器会在不花费太多编译时间的同时试图生成更快更小的代码。这些优化是非常基础的,但一般这些任务肯定能顺利完成。-O2:-O1 的进阶。这是推荐的优化等级,除非你有特殊的需求。-O2 会比 -O1 启用多一些标记。设置了 -O2 后,编译器会试图提高代码性能而不会增大体积和大量占用的编译时间。-O3:这是最高最危险的优化等级。用这个选项会延长编译代码的时间,并且在使用gcc4.x的系统里不应全局启用。自从3.x版本以来gcc的行为已经有了极大地改变。在3.x,-O3生成的代码也只是比-O2快一点点而已,而gcc4.x中还未必更快。用-O3来编译所有的软件包将产生更大体积更耗内存的二进制文件,大大增加编译失败的机会或不可预知的程序行为(包括错误)。这样做将得不偿失,记住过犹不及。在gcc 4.x.中使用-O3是不推荐的。-Os:这个等级用来优化代码尺寸。其中启用了-O2中不会增加磁盘空间占用的代码生成选项。这对于磁盘空间极其紧张或者CPU缓存较小的机器非常有用。但也可能产生些许问题,因此软件树中的大部分ebuild都过滤掉这个等级的优化。使用-Os是不推荐的。编译优化的缺点:可能导致单步调试出错,虽然执行速度加快了,但是不利于调试。
增量编译 VS 全量编译
链接
- 合并多个目标文件,关联声明与定义
- 连接(Linkage)种类:内部连接、外部连接、无连接
- 链接常见错误:找不到定义
link_err.cpp#include <iostream> extern int x; // 使用外部定义的x int main(void)
{
std::cout << x << std::endl;
return 0;
} // g++ -Wall -g link_err.cpp define_x.cpp -o link_err
define_x.cppint x = 111;
编译上述代码:
g++ -Wall -g link_err.cpp define_x.cpp -o link_err
可以正常生成可执行文件
link_err但当我们编译的时候,遗忘了
define_x.cpp的时候,就会出现如下错误:g++ -Wall -g link_err.cpp -o link_err
/usr/bin/ld: /tmp/ccp6ekAb.o: warning: relocation against `x' in read-only section `.text'
/usr/bin/ld: /tmp/ccp6ekAb.o: in function `main':
/home/yuzu/deeping_into_cpp/ch1/link_err.cpp:7: undefined reference to `x'
/usr/bin/ld: warning: creating DT_TEXTREL in a PIE
collect2: error: ld returned 1 exit status
其中
/home/yuzu/deeping_into_cpp/ch1/link_err.cpp:7: undefined reference to x说明了问题所在:指向了未定义的引用x。
注意:
- C++ 的编译 / 链接过程是复杂的,预处理、编译与链接都可能出错
- 编译可能产生警告、错误,都要重视
2. C++的编译/链接模型的更多相关文章
- 加快XCode的编译链接速度(200%+)—XCode编译速度慢的解决方案
最近在开发一个大项目的时候遇到一个很头疼的问题,由于项目代码较多,每次都要编译链接1分钟左右,调试的时候很浪费时间,于是研究了一下如何提高编译链接的速度,在这里分享给大家. 提升编译链接的速度主要有以 ...
- C++开始前篇,深入编译链接(3)
一,COMMON块 什么是COMMON块,这是一种机制,早期的Fortran没有动态分配空间的机制,程序员必须事先声明它所需要的临时使用空间的大小.Fortran把这种空间叫做COMMON块,当不同的 ...
- C++开始前篇,深入编译链接
C++开始,为什么要写这个东西,因为按照课堂进度的话,现在的C++已经学到模板以及重载了,有时却仍然因为一些小问题无法解答,原因是忘记了开始时学到的知识,深知不能像猴子掰棒子一样,掰一个扔一个,因此, ...
- VS编译链接时错误(Error Link2005)的解决方法
近期参与的项目中使用了公司另外一个同事提供的一个静态库文件.该静态库文件集成了CUDA, OpenCL两个库,用于做图形加速计算,提高视频解码拼接速度.但是在编译链接项目时,VS爆出如下错误: 1&g ...
- GCC编译器编译链接
在gcc编译器环境下,常见的文件扩展名的含义如下: .c:C源程序,经过预编译后的源程序也为.c文件,它可以通过-E参数输出. .h:头文件 .s:经过编译得到的汇编程序代码,它可以通过-S参数输出. ...
- C语言编译链接
转载请标明: 编译链接是使用高级语言编程所必须的操作,一个源程序只有经过编译.链接操作以后才可以变成计算机可以理解并执行的二进制可执行文件. 编译是指根据用户写的源程序代码,经过词法和语法分析,将高级 ...
- C++常见gcc编译链接错误解决方法
除非明确说明,本文内容仅针对x86/x86_64的Linux开发环境,有朋友说baidu不到,开个贴记录一下(加粗字体是关键词): 用“-Wl,-Bstatic”指定链接静态库,使用“-Wl,-Bdy ...
- linux 编译,链接和加载
1. 序 最近在折腾各种.so,碰到了一些问题,一开始对于很多错误也没有头绪,茫然不知所措.索性化了一天多时间将<<程序员的自我修养—链接.装载与库>>中部分内容略读了一遍 ...
- 【原创】Linux下编译链接中常见问题总结
前言 一直以来对Linux下编译链接产生的问题没有好好重视起来,出现问题就度娘一下,很多时候的确是在搜索帮助下解决了BUG,但由于对原因不求甚解,没有细细研究,结果总是在遇到在BUG时弄得手忙脚乱得. ...
- 在 MacOS 上编译链接 OpenGL 程序
几个星期以前开始折腾在我的MBA上写 OpenGL 小程序.我不太熟悉MacOS上的开发工具比如XCode,所以一开始的想法就是用vim来写程序,然后手工编译链接.网上查了一下,MacOS上的Open ...
随机推荐
- python 源
清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https: ...
- BigDecimal类的基本使用
概述 java在java.math包中提供的API类BigDecimal,用来对超过16位有效位的数进行精确的运算.双精度浮点型变量double可以处理16位有效数.在实际应用中,需要对更大或者更小的 ...
- 设置 ASP.NET Core Web API 中响应数据的格式 AddNewtonsoftJson 使用NewtonsoftJson替换掉默认的System.Text.Json序列化组件
#region 使用NewtonsoftJson替换掉默认的json序列化组件 .AddNewtonsoftJson(options => { 修改属性名称的序列化方式,首字母小写 //opti ...
- Flask-Limit详细说明:接口限流
速率限制通常作为服务的防御措施予以实施.服务需要保护自身以免过度使用(无论是有意还是无意),从而保持服务可用性.在Flask项目开发过程中,遇到了需要对接口进行限制的需求,又不想去造轮子,这时候就需要 ...
- 音视频学习--H264解析渲染
一.H264文件获取 下载一段MP4文件,通过FFMPEG转换成MP4 ffmpeg -i Gravity.mp4 -vcodec h264 out_2.264 二.通过解析H264成帧,然后刷新 这 ...
- 8.14考试总结(NOIP模拟39)[打地鼠·竞赛图·糖果·树]
一举一动,都是承诺,会被另一个人看在眼里,记在心上的. T1 打地鼠 解题思路 数据范围比较小,不需要什么优化. 直接二维前缀和枚举右下角端点就好了. code #include<bits/st ...
- ubuntu server 安装慢 安装卡
无论是桌面版本ubuntu,还是server 版本,都喜欢在安装过程中联网下东西: 默认的软件包镜像地址下载非常慢,你自身的网络再差点,可能会安装好几个小时. 解决方案: 方案1: 安装前拔网线. 方 ...
- SQL SERVER 2012的安装
1.将光盘镜像用虚拟光驱加载(WIN10自带虚拟光驱) 2.双击setup.exe 3.选择"安装"-"全新 SQL Server 独立安装或向现有安装添加功能" ...
- vuex中的数据在页面刷新后数据消失
用sessionstorage 或者 localstorage 存储数据 存储: sessionStorage.setItem( '名', JSON.stringify(值) ) 使用: sessio ...
- 模拟epoll的饥饿场景
说明 一直听说epoll的饥饿场景,但是从未在实际环境中面对过,那么能不能模拟出来呢?实际的情况是怎样呢? 模拟步骤 基于epoll写一个简单的tcp echo server,将每次read返回的字节 ...