kafka 为什么能那么快?高效读写数据,原来是这样做到的
1. 利用 Partition 实现并行处理
我们都知道 Kafka 是一个 Pub-Sub 的消息系统,无论是发布还是订阅,都要指定 Topic。
Topic 只是一个逻辑的概念。每个 Topic 都包含一个或多个 Partition,不同 Partition 可位于不同节点。
一方面,由于不同 Partition 可位于不同机器,因此可以充分利用集群优势,实现机器间的并行处理。另一方面,由于 Partition 在物理上对应一个文件夹,即使多个 Partition 位于同一个节点,也可通过配置让同一节点上的不同 Partition 置于不同的磁盘上,从而实现磁盘间的并行处理,充分发挥多磁盘的优势。
能并行处理,速度肯定会有提升,多个工人肯定比一个工人干的快。
2. 顺序写磁盘
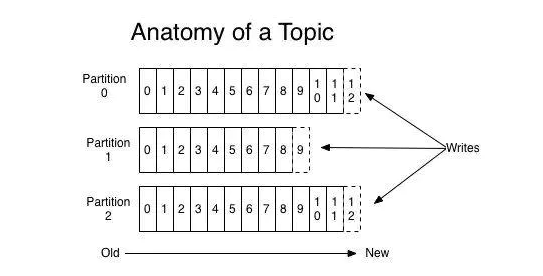
Kafka 中每个分区是一个有序的,不可变的消息序列,新的消息不断追加到 partition 的末尾,这个就是顺序写。
很久很久以前就有人做过基准测试:《每秒写入2百万(在三台廉价机器上)》
由于磁盘有限,不可能保存所有数据,实际上作为消息系统 Kafka 也没必要保存所有数据,需要删除旧的数据。又由于顺序写入的原因,所以 Kafka 采用各种删除策略删除数据的时候,并非通过使用“读 - 写”模式去修改文件,而是将 Partition 分为多个 Segment,每个 Segment 对应一个物理文件,通过删除整个文件的方式去删除 Partition 内的数据。这种方式清除旧数据的方式,也避免了对文件的随机写操作。
3、零拷贝技术
Kafka 中存在大量的网络数据持久化到磁盘(Producer 到 Broker)和磁盘文件通过网络发送(Broker 到 Consumer)的过程。这一过程的性能直接影响 Kafka 的整体吞吐量。
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的权限。
为了避免用户进程直接操作内核,保证内核安全,操作系统将虚拟内存划分为两部分,一部分是内核空间(Kernel-space),一部分是用户空间(User-space)。
传统的 Linux 系统中,标准的 I/O 接口(例如read,write)都是基于数据拷贝操作的,即 I/O 操作会导致数据在内核地址空间的缓冲区和用户地址空间的缓冲区之间进行拷贝,所以标准 I/O 也被称作缓存 I/O。这样做的好处是,如果所请求的数据已经存放在内核的高速缓冲存储器中,那么就可以减少实际的 I/O 操作,但坏处就是数据拷贝的过程,会导致 CPU 开销。
我们把 Kafka 的生产和消费简化成如下两个过程来看[2]:
网络数据持久化到磁盘 (Producer 到 Broker)
磁盘文件通过网络发送(Broker 到 Consumer)
总结
如果,面试官再问我:Kafka为什么这么快?我会这么说:
partition 并行处理
顺序写磁盘,充分利用磁盘特性
利用了现代操作系统分页存储 Page Cache 来利用内存提高 I/O 效率
采用了零拷贝技术
Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入
Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗
kafka 为什么能那么快?高效读写数据,原来是这样做到的的更多相关文章
- Kafka为什么速度那么快?
Kafka为什么速度那么快? Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率. 即使是普通的服务器 ...
- Kafka为什么速度那么快?该怎么回答
Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率.即使是普通的服务器,Kafka也可以轻松支持每秒百 ...
- Kafka速度为什么那么快
记录一下 Kafka速度为什么那么快 Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率. 即使是普通 ...
- Kafka为什么性能这么快?4大核心原因详解
Kafka的性能快这是大厂Java面试经常问的一个话题,下面我就重点讲解Kafka为什么性能这么快的4大核心原因@mikechen 1.页缓存技术 Kafka 是基于操作系统 的页缓存(page ca ...
- .net环境下跨进程、高频率读写数据
一.需求背景 1.最近项目要求高频次地读写数据,数据量也不是很大,多表总共加起来在百万条上下. 单表最大的也在25万左右,历史数据表因为不涉及所以不用考虑, 难点在于这个规模的热点数据,变化非常频繁. ...
- HBase读写数据的详细流程及ROOT表/META表介绍
一.HBase读数据流程 1.Client访问Zookeeper,从ZK获取-ROOT-表的位置信息,通过访问-ROOT-表获取.META.表的位置,然后确定数据所在的HRegion位置: 2.Cli ...
- C# .Net 多进程同步 通信 共享内存 内存映射文件 Memory Mapped 转 VC中进程与进程之间共享内存 .net环境下跨进程、高频率读写数据 使用C#开发Android应用之WebApp 分布式事务之消息补偿解决方案
C# .Net 多进程同步 通信 共享内存 内存映射文件 Memory Mapped 转 节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing). ...
- 通用高效的数据修复方法:Row level repair
导读:随着大数据的进一步发展,NoSQL 数据库系统迅速发展并得到了广泛的应用.其中,Apache Cassandra 是最广泛使用的数据库之一.对于 Cassandra 的优化是大家研究的热点,而 ...
- ES读写数据过程及原理
ES读写数据过程及原理 倒排索引 首先来了解一下什么是倒排索引 倒排索引,就是建立词语与文档的对应关系(词语在什么文档出现,出现了多少次,在什么位置出现) 搜索的时候,根据搜索关键词,直接在索引中找到 ...
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
随机推荐
- Go-操作redis/redigo
目录 Go-操作redis 安装 连接 使用 设置key过期时间 批量获取mget.批量设置mset 列表操作 hash操作 Pipelining(管道) redis发布会订阅模式 事务操作 万能操作 ...
- 8.4 ProcessHeap
ProcessHeap 是Windows进程的默认堆,每个进程都有一个默认的堆,用于在进程地址空间中分配内存空间.默认情况下ProcessHeap由内核进行初始化,该堆中存在一个未公开的属性,它被设置 ...
- hydra 密码爆破工具入门
Hydra(九头蛇海德拉)是希腊神话之中的一个怪兽,以九个头闻名于世,在Kali中hydray(hai der rua) 是默认被安装的,该工具是密码破解的老司机,可以破解各种登录密码,非常怪兽,但是 ...
- ASP.NET Core必备知识之Autofac
使用Autofac替换掉微软的DI 本文的项目为ASP.NET Core3.1,传统三层架构 在这就不过多介绍Autofac,直接上代码 Autofac官网:https://autofac.org/ ...
- 零基础入门学习Java课堂笔记 ——day04
Java数组 1.数组概述 定义:数组是相同类型的有序集合,同一组同一类型的数据可以按照先后次序排列组合在一起,其中一个数据可以称为元素,每个数组元素可以通过一个下表访问它们 2.数组声明创建 dat ...
- TStringList的IndexOfName
IndexOfName这个方法用着很好,记录下,以后留意下 上个例子: procedure TForm1.Button1Click(Sender: TObject); var MyList: TStr ...
- ABC 312
前三题氵 D 给定一个由 (,?,) 组成的字符串.每个 ? 可以设定为任意括号.求有几种设定方法使得整个是合法括号序列. 套路,dp E 给定 \(n\) 个两两不相交的长方体,对每个长方体,求有多 ...
- JavaScript 的灵异事件之一
场景 在做项目的时候需要用到Ajax 做多次的异步处理数据, 三次Ajax:A --ok--> B --ok--> C 在入参数据相同的情况下,做了两论这个操作,但发现没有发送 A 的 A ...
- SpringBoot 2.6 和 JUnit 5 的测试用例注解和排序方式
JUnit5 的测试注解 在JUnit5中, 不再使用 @RunWith 注解, 改为使用 @ExtendWith(SpringExtension.class) @ExtendWith(SpringE ...
- 【Unity3D】UGUI之Toggle
1 Toggle属性面板 在 Hierarchy 窗口右键,选择 UI 列表里的 Toggle 控件,即可创建 Toggle 控件,选中创建的 Toggle 控件,按键盘[T]键,可以调整 Tog ...