强化学习中经典算法 —— reinforce算法 —— (进一步理解, 理论推导出的计算模型和实际应用中的计算模型的区别)
在奖励折扣率为1的情况下,既没有折扣的情况下,reinforce算法理论上可以写为:

但是在有折扣的情况下,reinforce算法理论上可以写为:

以上均为理论模型。
====================================================
根据上面的理论上的算法模型,或者说是伪代码,你是难以使用这个算法的。这个reinforce算法也是十分古怪和气人的,之所以这样说是因为完全根据reinforce的算法描述(伪代码)实际上基本无法写出可以正常运行的代码(能有效的代码,算法结果是不收敛的或者在使用神经网络做拟合函数会出现衰退的问题)。而且另一个古怪和气人的地方是reinforce的算法描述(伪代码)和reinforce算法的理论分析模型也是不同的,reinforce的理论分析一般都是假定有同一个执行策略(动作策略)下生成的大量episodes的数据来对评估网络(评估策略)进行更新的,而在算法描述中往往是一个episode下的每一个step的数据就对策略网络进行一次更新,或者说算法描述中我们是一个策略网络生成一个episode的数据,然后我们把这个episode下每一step的数据都用来更新一次策略网络。
总的说来,就是reinforce的标准算法描述是不可用的,往往在实际中我们使用的reinforce算法的模型,或者说实际上的算法描述(伪代码)是不同的。
===============================================
实际上的 reinforce算法,真正使用的reinforce算法是这样的:伪代码(算法描述):

但是,如果我们严格按照reinforce算法的理论推导,写出的算法模型,伪代码该是如下形式:

根据上面的两个不同具体形式的伪代码,我们可以看出严格按照理论推导得到的reinforce算法模型是需要使用折扣概率下的折扣奖励来做计算的,而实际应用中我们往往直接使用折扣奖励进行规整后的数值来进行计算。也就是说实际应用reinforce算法时我们不仅没有对奖励值取折扣概率下的值,并且还对折扣奖励进行了规整(高斯化)。
那么我们可以不可以对折扣奖励取折扣概率后再进行规整化呢,于是有了下面的算法模型,伪代码:

===========================
根据上面的分析,实际使用reinforce算法时根据对奖励值的处理可以分为以下4种:
1. 更新网络参数时使用的奖励值为 折扣奖励,也就是最原始的奖励值,不加其他处理的形式。
2. 更新网络参数时使用的奖励值为 折扣概率下的折扣奖励。
3. 更新网络参数时使用的奖励值为 将折扣奖励进行规整化后的奖励值 。
4. 更新网络参数时使用的奖励值为 将折扣概率下的折扣奖励进行规整化后的奖励值。
--------------------------
通过gym环境下的实验发现,第一种和第二种形式的reinforce算法直接导致神经网络衰退,也就是说完全随机策略进行交互我们可以得到的episode的长度在29左右,而第一种和第二种形式的reinforce算法所训练得到的策略直接会衰退到对一个episode内的所有step下的状态给出相同的action。
第二种形式下的部分运行结果:(第二种形式下,此时更新一次网络的episodes数为10)
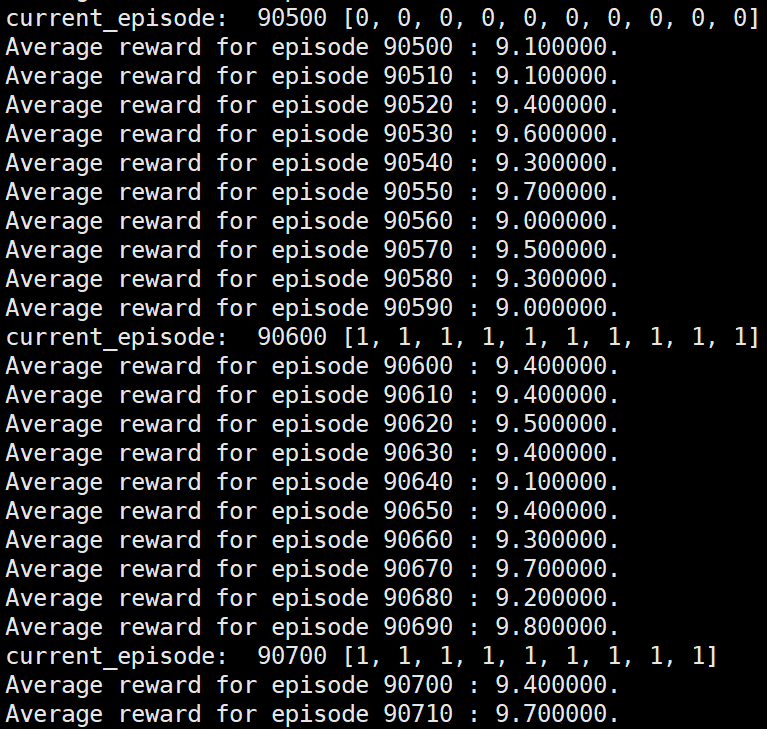
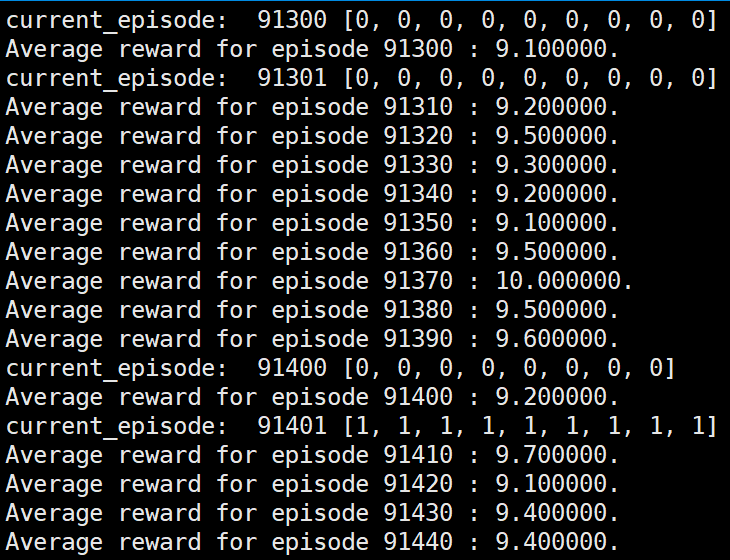
可以看到使用第二种形式的reinforce算法,在运行一段时间后运行效果直接从完全随机的策略衰退为对一个episode下的所有状态给出相同action的表现。
而在以前的博客(https://www.cnblogs.com/devilmaycry812839668/p/14097322.html)中也讨论过即使使用实际应用中最常见的第3种形式的reinforce也会有一定的概率出现衰退问题,不过那时的衰退往往是运行效果优化到了一定程度后才进行衰退的,而第二种形式的reinforce算法是直接在开始的阶段就直接从随机策略衰退到完全无效的策略(对一个episode内的所有state给出完全相同的action)。
第一种形式的reinforce和第二种形式的reinforce相似,都是从随机策略开始后快速的衰退到对一个episode内的所有state给出完全相同的action,从而变成了无效的策略。
第一种,第二种形式的reinforce直接进入衰退,而第三种,第四中形式的reinforce就可以正常运行到要求的效果,这中间的区别就是最后训练时所采用的奖励值的具体形式。
=======================================
个人的小尝试:
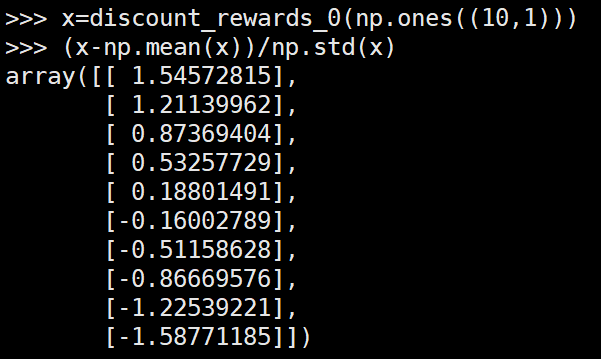
第三种形式的reinforce中最后更新网络的奖励值的例子:
(action全部都是1的情况)
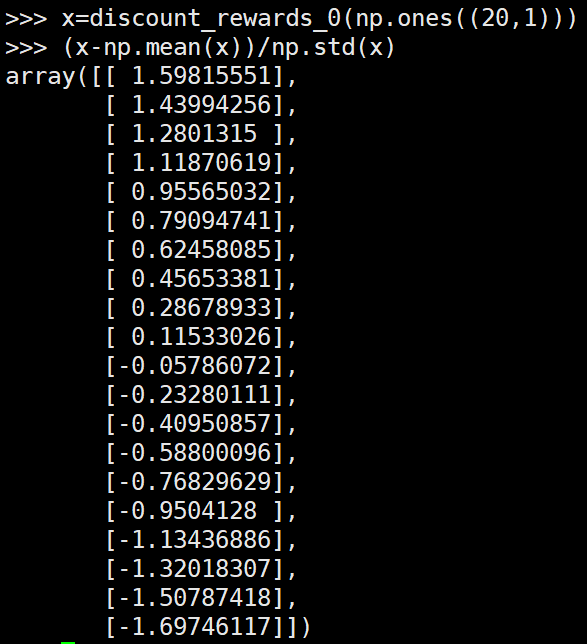
第二种形式的reinforce算法奖励值的例子:
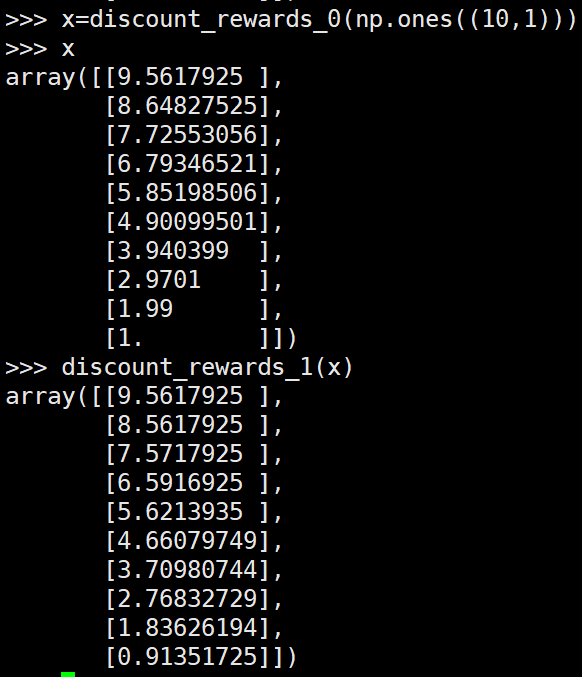
可以看到第一种形式的reinforce和第二种的reinforce最后进行网络更新时的奖励值都是大小在T到0之间,其中T为该episode的长度。而第三种形式的reinforce算法均值为0,方差为1。
观察第二种形式的reinforce和第三种reinforce的区别,更新网络时奖励值的区别,我们将第二种形式的reinforce奖励值的形式进行修改:
此时运行reinforce算法:
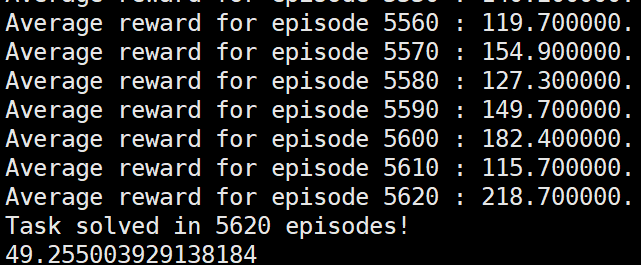
修改后的reinforce算法成功达到要求。
而第三种形式的reinforce运行结果:
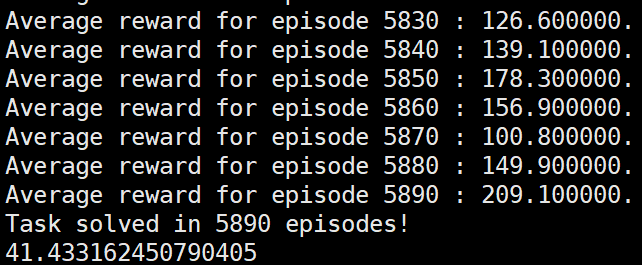
可以看到采用新的奖励值后的reinforce算法可以和第三种形式的reinforce算法性能相当,或者说并没有明显差于第三种形式的reinforce。
再一次修改第二种形式的reinforce的奖励值形式:
发现也是可以达到要求:
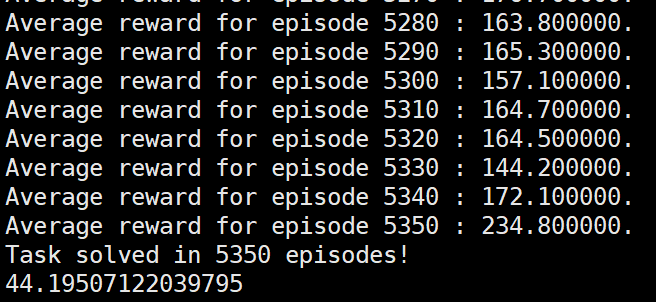
然而当奖励值形式为:

或:

reinforce算法都是无法达到要求的,直接衰退:
于是有了一个大胆的猜测,只要更新网络时的一个episode内的各个step的奖励值均值为0,那么必然可以运行到要求的水平,于是奖励值设置下面的形式:

发现依然成功到达要求:
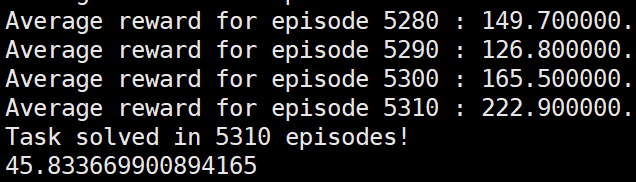
根据上面的实际应用中的reinforce的实际形式(形式3)和理论推导中的(形式2)之间运行效果的不同,我们大胆设想每一次更新网络时reinforce算法要求各奖励值的均值为0才可以成功运行。
==========================================
个人的一点小总结:
有时候理论上各种推导,各种公式,各种理论,然后各种名词堆到一起搞出一个算法,貌似应该可行,而在实际上就并不是很可行,个人感觉这说明理论是有指导作用但是没有绝定性的作用,而且至于靠谱不靠谱,完善不完善最终还是需要实际应用中去看,可能这也是那种 实践是检验真理的唯一途径。可能有时候由于理论的限制等等原因,有些改进的东西无法用完善的理论来解释但是确实可行,而有的时候有些理论感觉很完善其实却还差一些,这时候就需要一些在实践中的改进了。
单纯的从算法角度来看,那就是 reward shap 不仅会提高算法的运算效率,甚至对算法的最终性能(优化结果)也是具有很大的影响的,就像本文中的不同形式的reinforce,如果reward设置的不好往往算法不work。就像实际中的reinforce算法虽然和理论推导的形式有一些不同,但是却能work,而我们最终采用的形式就是那种可以work就用哪种。
文中代码地址:
https://gitee.com/devilmaycry812839668/cart-pole_-policy-network_-reinforce
====================================================
重要说明:
本文代码中出现错误,后已经修复,因此上面的实验结果均为错误。
经过修改后发现mode=0 , mode=1, mode=2, mode=3 均可以收敛取得最终结果。 因此原文中所得到的结论mode=0, mode=1 不能收敛是错误的。
特此更正。
----------------------------------------------
强化学习中经典算法 —— reinforce算法 —— (进一步理解, 理论推导出的计算模型和实际应用中的计算模型的区别)的更多相关文章
- 强化学习策略梯度方法之: REINFORCE 算法(从原理到代码实现)
强化学习策略梯度方法之: REINFORCE 算法 (从原理到代码实现) 2018-04-01 15:15:42 最近在看policy gradient algorithm, 其中一种比较经典的 ...
- 强化学习-MDP(马尔可夫决策过程)算法原理
1. 前言 前面的强化学习基础知识介绍了强化学习中的一些基本元素和整体概念.今天讲解强化学习里面最最基础的MDP(马尔可夫决策过程). 2. MDP定义 MDP是当前强化学习理论推导的基石,通过这套框 ...
- 基于深度强化学习(DQN)的迷宫寻路算法
QLearning方法有着明显的局限性,当状态和动作空间是离散的且维数不高时可使用Q-Table存储每个状态动作的Q值,而当状态和动作时高维连续时,该方法便不太适用.可以将Q-Table的更新问题变成 ...
- 强化学习中REIINFORCE算法和AC算法在算法理论和实际代码设计中的区别
背景就不介绍了,REINFORCE算法和AC算法是强化学习中基于策略这类的基础算法,这两个算法的算法描述(伪代码)参见Sutton的reinforcement introduction(2nd). A ...
- temporal credit assignment in reinforcement learning 【强化学习 经典论文】
Sutton 出版论文的主页: http://incompleteideas.net/publications.html Phd 论文: temporal credit assignment i ...
- 强化学习中的无模型 基于值函数的 Q-Learning 和 Sarsa 学习
强化学习基础: 注: 在强化学习中 奖励函数和状态转移函数都是未知的,之所以有已知模型的强化学习解法是指使用采样估计的方式估计出奖励函数和状态转移函数,然后将强化学习问题转换为可以使用动态规划求解的 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- ICML论文|阿尔法狗CTO讲座: AI如何用新型强化学习玩转围棋扑克游戏
今年8月,Demis Hassabis等人工智能技术先驱们将来到雷锋网“人工智能与机器人创新大会”.在此,我们为大家分享David Silver的论文<不完美信息游戏中的深度强化学习自我对战&g ...
- 李宏毅强化学习完整笔记!开源项目《LeeDeepRL-Notes》发布
Datawhale开源 核心贡献者:王琦.杨逸远.江季 提起李宏毅老师,熟悉强化学习的读者朋友一定不会陌生.很多人选择的强化学习入门学习材料都是李宏毅老师的台大公开课视频. 现在,强化学习爱好者有更完 ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
随机推荐
- 极限科技(INFINI labs)荣获中国信通院大数据“星河”标杆案例
12 月 6 日,由中国信息通信研究院和中国通信标准化协会大数据技术标准推进委员会(CCSA TC601)共同组织的 2023 大数据"星河(Galaxy)"案例评选结果正式公示. ...
- 牛客小白月赛96(待F)
比赛链接:牛客小白月赛96 赛时感受 赛时在前面卡的时间有点长,C题没开longlong wa了n发,D题没考虑负数又wa了n发,然后来写E的时候时间就不长了,匆忙写一次交一发. A 思路 当其中一个 ...
- 支撑阻力指标,庄家成本价是可靠的支撑位(无未来,DLL加密)
本指标依据庄家的成本价设计的,庄家成本价是可靠的支撑位.底层逻辑:庄家是有内幕的, 庄家能在价格低位时抄底,庄家控股时,庄家不会让散户获取低价的筹码,所以当股价到达到支撑位时,会有比较大的反弹.庄家也 ...
- SpringCloud开发之OpenFeign timeout和压缩等问题
在某些时候,我们希望某个同步调用执行更长的时间(异步暂时不考虑),这个时候,首先就是要设置OpenFeign的timeout设定. 下面我们举例来说明,可以如何设定TimeOut参数. 一.环境 脱离 ...
- linux 下新建显示器分辨率
1. 输入cvt 1920 1080 (假设需要添加的分辨率为1920x1080), 获取Mode Line # 1920x1080 59.96 Hz (CVT 2.07M9) hsync: 67.1 ...
- Ubuntu 22.04单机部署K3s
安装docker 从docker官网获取最新的一键安装脚本,安装docker运行环境 curl -fsSL https://get.docker.com -o get-docker.sh sudo s ...
- Quarkus初体验:动态加载和原生部署
在前面的文章<尝试官方的第一个SpringNative 0.11程序>中提到过Quarkus这门技术.这里就简单演示一下它的两个主要功能:Live Coding和Native Build. ...
- ubuntu16 python2 安装M2Crypto报错
正文 pip2 install M2Crypto # 报错: # unable to execute 'swig': No such file or directory # error: comman ...
- Java中的泛型(类、接口、方法)
一.泛型概述 1. 什么是泛型? 泛型,即"参数化类型".一提到参数,最熟悉的就是定义方法时有形参列表,普通方法的形参列表中,每个形参的数据类型是确定的,而变量是一个参数.在调用普 ...
- yb课堂之高并发项目必备利器之分布式缓存和本地缓存 《十九》
什么是缓存? 程序经常要调用的对象存储在内存中,方便其使用时可以快速调用,不必去数据库或者其他持久化设备中查询,主要就是提高性能 DNS.前端缓存.代理服务器缓存Nginx.应用程序缓存(本地缓存.分 ...