【股票爬虫教程】我用100行Python代码,爬了雪球网5000只股票,还发现一个网站bug!
一、爬取目标
您好,我是@马哥python说,今天继续分享爬虫案例。
爬取网站:雪球网的沪深股市行情数据
具体菜单:雪球网 > 行情中心 > 沪深股市 > 沪深一览
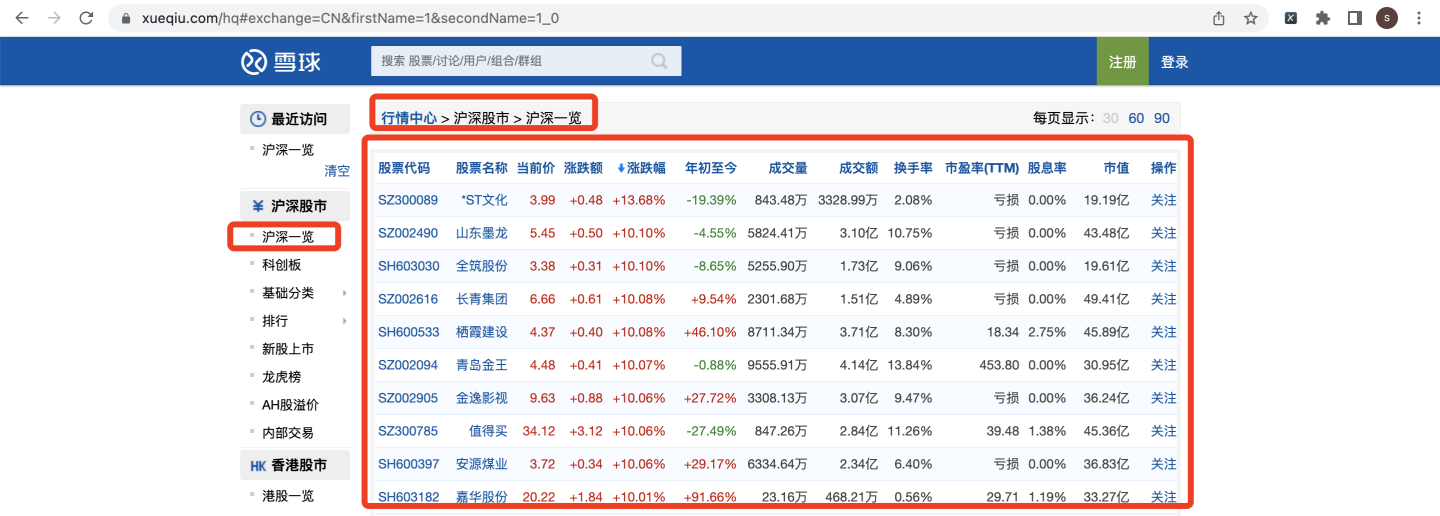
爬取字段,含:
股票代码,股票名称,当前价,涨跌额,涨跌幅,年初至今,成交量,成交额,换手率,市盈率,股息率,市值。
二、分析网页
在网页中,我们注意到,默认每页显示30条:
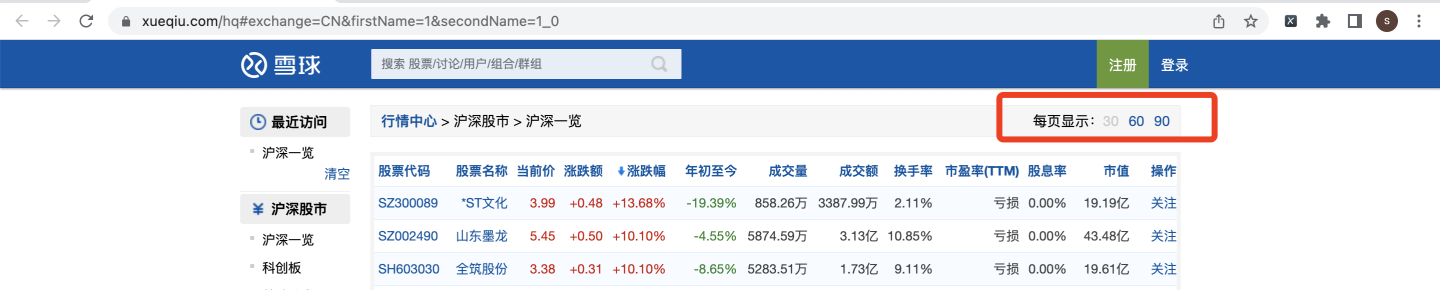
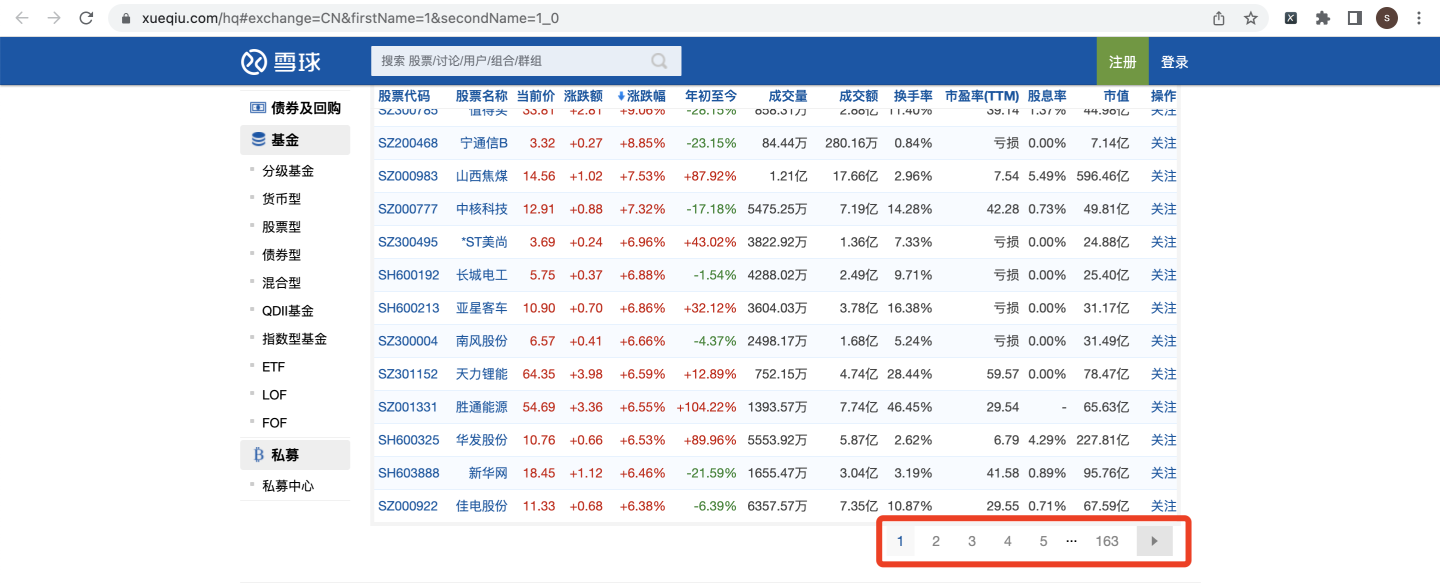
一共163页:
如果切换到每页90条,总页数就会变成55页:
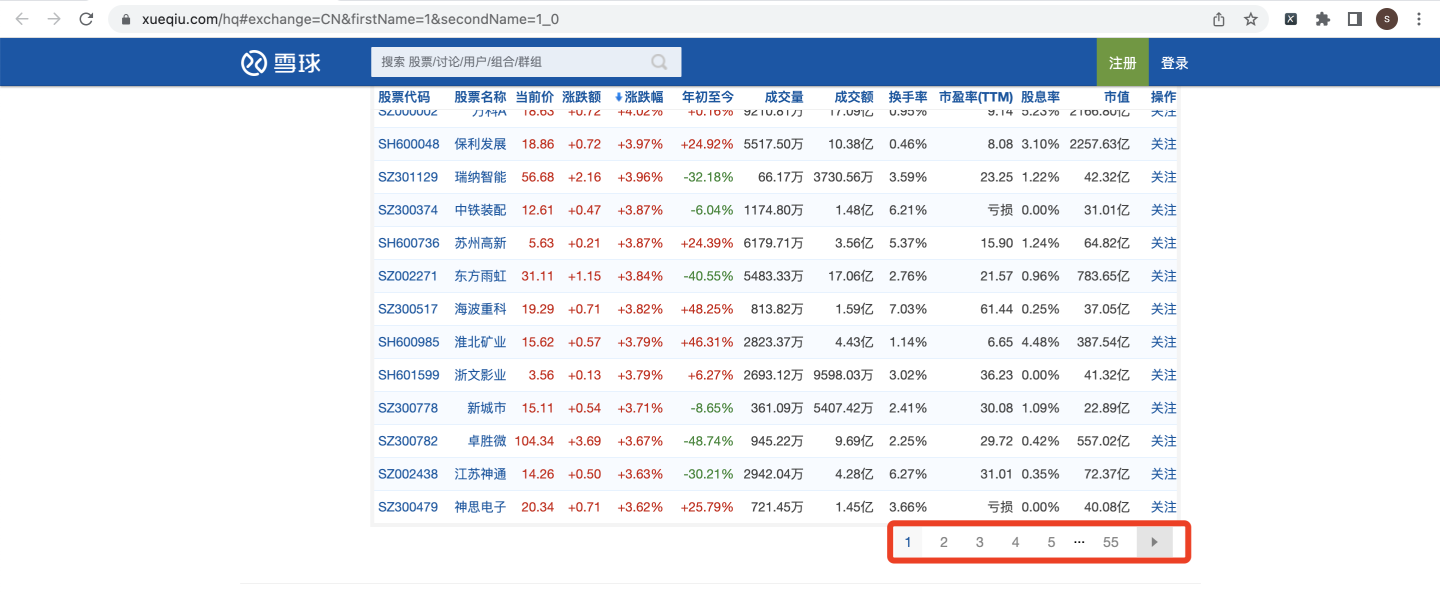
基于尽量少的向页面发送请求,防止反爬的考虑,选择每页90条。
下面,开始分析网页接口。
按F12,打开chrome浏览器的开发者模式,重新刷新网页,并翻页3次,发现3个网页请求:
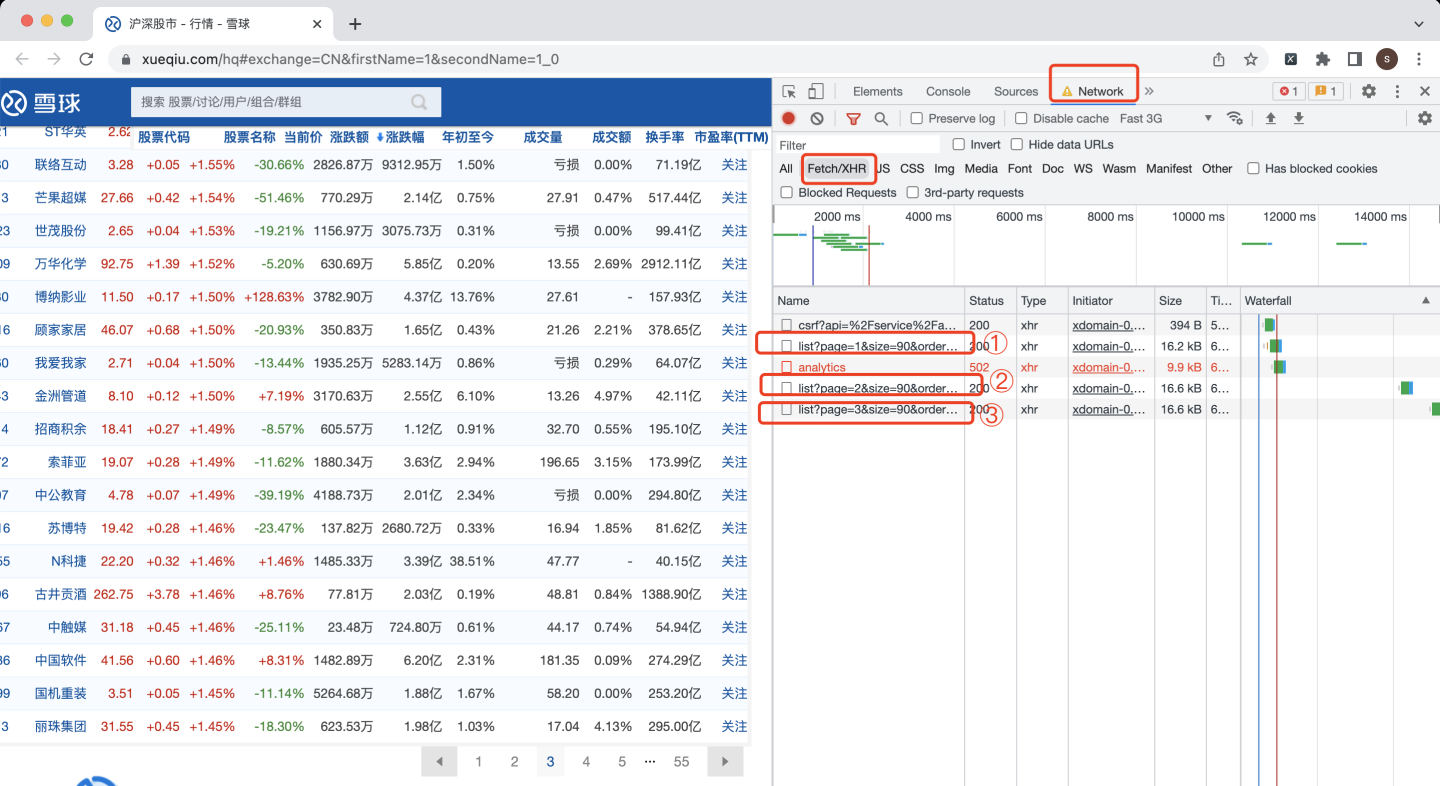
由此推测,这就是目标股票数据。
为了验证此猜测,打开预览页面,展开json数据,找到第0只股票:
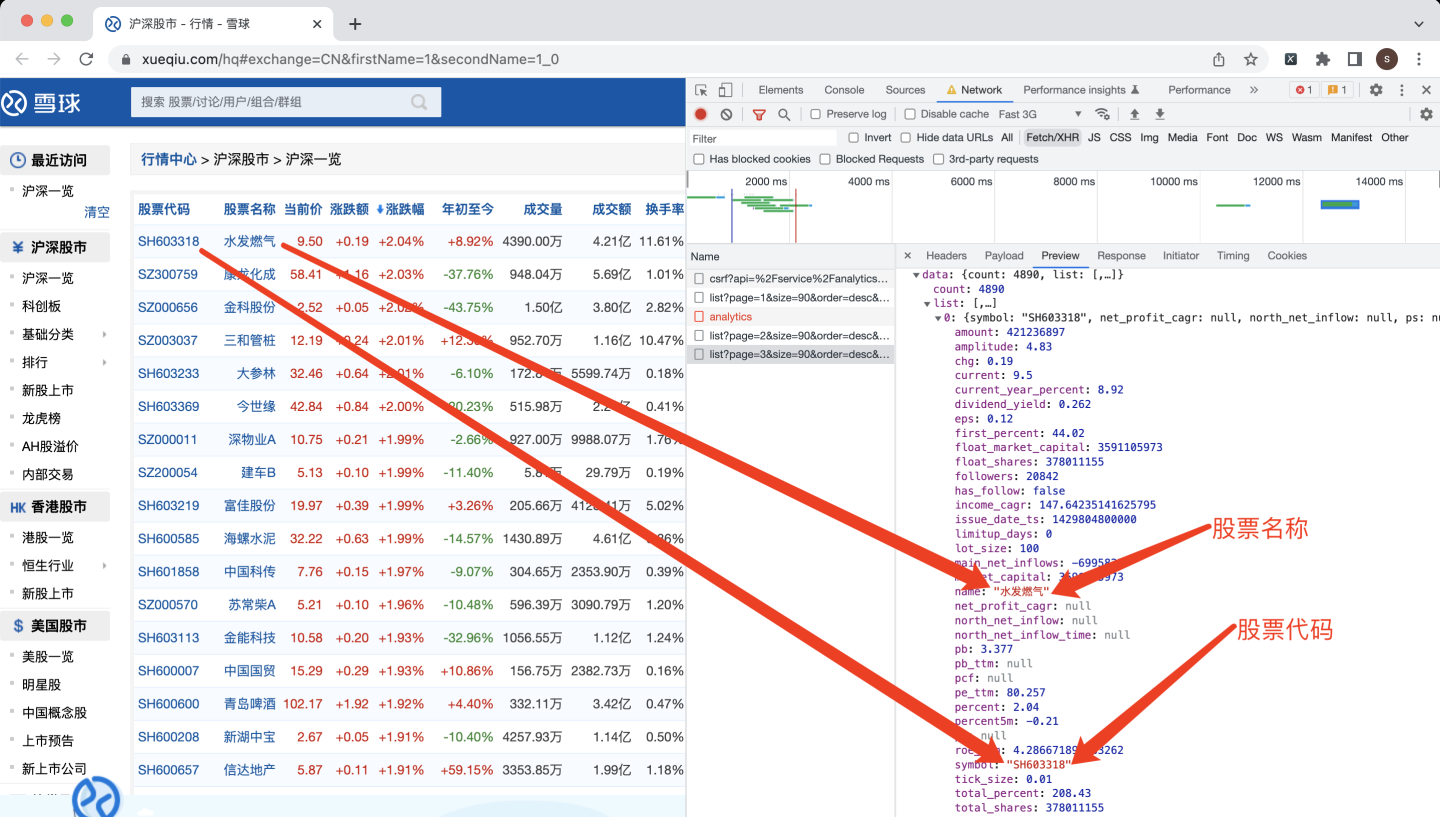
经过和页面对比,发现数据一致。
下面继续看网页请求参数:
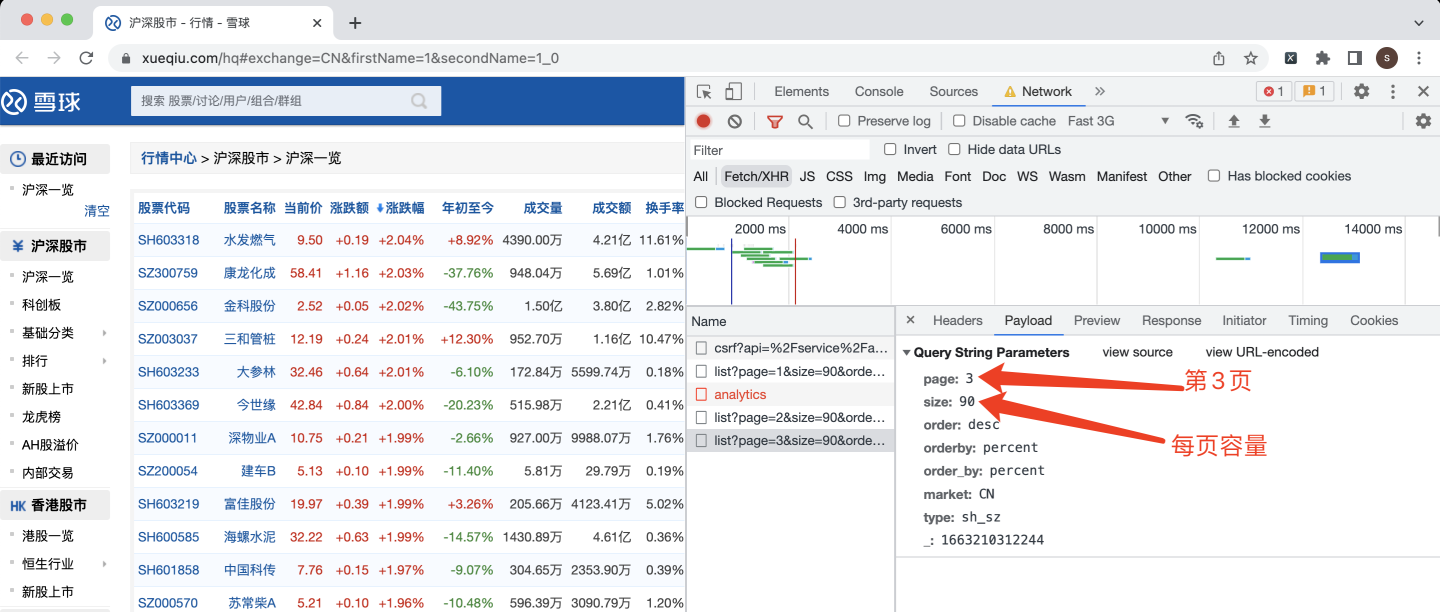
这里每页容量是90条数据,大胆猜测一下,如果每页容量指定为5000,只爬取1页,是不是更省事儿。
虽然大胆猜测,但要小心求证,毕竟一名合格的接口开发者不会这么做。
一般情况下,如果发现用户请求大于每页容量,会返回一个exceed max size或者invalid request之类的error给用户,但我们不妨试试。。
下面开始开发爬虫代码:
三、爬虫代码
首先,定义一个请求头,直接从开发者模式里copy过来:
# 定义字符串请求头
header1 = """
Accept: */*
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7
cache-control: no-cache
Connection: keep-alive
Cookie: 换成自己的
Host: xueqiu.com
Referer: https://xueqiu.com/hq
sec-ch-ua: "Google Chrome";v="105", "Not)A;Brand";v="8", "Chromium";v="105"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36
X-Requested-With: XMLHttpRequest
"""
通过copy_headers_dict转换成dict格式:
# 转换成dict格式请求头
header2 = copy_headers_dict(header1)
如此方便!
下面开始发送请求,如上所讲,大胆尝试请求第1页,页容量5000条:
# 请求地址
url = "https://xueqiu.com/service/v5/stock/screener/quote/list?page=1&size=5000&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz&_=1663203107799"
# 发送请求
resp = requests.get(url, headers=header2)
查看响应码及响应数据,真的请求到了!
估计过不了多久,雪球网的程序员小哥哥该被领导请去喝茶了~
下面开始解析json数据:
# 解析json数据
json_data = resp.json()
data_list = json_data['data']['list']
先定义一些空列表用于存储数据:
# 定义空列表用于存储数据
symbol_list = [] # 股票代码
name_list = [] # 股票名称
current_list = [] # 当前价
chg_list = [] # 涨跌额
percent_list = [] # 涨跌幅
current_year_percent_list = [] # 年初至今
volume_list = [] # 成交量
amount_list = [] # 成交额
turnover_rate_list = [] # 换手率
pe_ttm_list = [] # 市盈率
dividend_yield_list = [] # 股息率
market_capital_list = [] # 市值
其实,接口里还有更多字段,这里我只爬取了网页上有的字段。
把解析好的字段数据append到空列表中,以股票代码和股票名称为例:
for data in data_list:
symbol_list.append(data['symbol'])
name_list.append(data['name'])
print('已爬取第{}只股票,股票代码:{},股票名称:{}'.format(count, data['symbol'], data['name']))
其他字段同理,不再演示。
最后,把列表数据存入DataFrame数据中:
df = pd.DataFrame(
{
'股票代码': symbol_list,
'股票名称': name_list,
'当前价': current_list,
'涨跌额': chg_list,
'涨跌幅': percent_list,
'年初至今': current_year_percent_list,
'成交量': volume_list,
'成交额': amount_list,
'换手率': turnover_rate_list,
'市盈率': pe_ttm_list,
'股息率': dividend_yield_list,
'市值': market_capital_list,
}
)
最后,用to_csv把最终数据落地成csv文件,大功告成!
四、同步视频
演示视频:
https://www.bilibili.com/video/BV1H24y1Z7BP
五、get完整源码
附完整源码:公众号"老男孩的平凡之路"后台回复"爬雪球"即可获取。
我是 马哥python说,感谢阅读!
【股票爬虫教程】我用100行Python代码,爬了雪球网5000只股票,还发现一个网站bug!的更多相关文章
- 20行Python代码爬取王者荣耀全英雄皮肤
引言王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. 准备工作 ...
- 哪吒票房超复联4,100行python代码抓取豆瓣短评,看看网友怎么说
<哪吒之魔童降世>这部国产动画巅峰之作,上映快一个月时间,票房口碑双丰收. 迄今已有超一亿人次观看,票房达到42.39亿元,超过复联4,跻身中国票房纪录第三名,仅次于<战狼2> ...
- 100行Python代码实现一款高精度免费OCR工具
近期Github开源了一款基于Python开发.名为 Textshot 的截图工具,刚开源不到半个月已经500+Star. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语 ...
- 一个 11 行 Python 代码实现的神经网络
一个 11 行 Python 代码实现的神经网络 2015/12/02 · 实践项目 · 15 评论· 神经网络 分享到:18 本文由 伯乐在线 - 耶鲁怕冷 翻译,Namco 校稿.未经许可,禁止转 ...
- 200行Python代码实现2048
200行Python代码实现2048 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面 ...
- 10行Python代码计算汽车数量
当你还是个孩子坐车旅行的时候,你玩过数经过的汽车的数目的游戏吗? 在这篇文章中,我将教你如何使用10行Python代码构建自己的汽车计数程序. 以下是环境及相应的版本库: Python版本 3.6.9 ...
- 200行PYTHON代码实现贪吃蛇
200行Python代码实现贪吃蛇 话不多说,最后会给出全部的代码,也可以从这里Fork,正文开始: 目前实现的功能列表: 贪吃蛇的控制,通过上下左右方向键: 触碰到边缘.墙壁.自身则游戏结束: 接触 ...
- 40多行python代码开发一个区块链。
40多行python代码开发一个区块链?可信吗?我们将通过Python 2动手开发实现一个迷你区块链来帮你真正理解区块链技术的核心原理.python开发区块链的源代码保存在Github. 尽管有人认为 ...
- 15行python代码,帮你理解令牌桶算法
本文转载自: http://www.tuicool.com/articles/aEBNRnU 在网络中传输数据时,为了防止网络拥塞,需限制流出网络的流量,使流量以比较均匀的速度向外发送,令牌桶算法 ...
- 30行Python代码实现人脸检测
参考OpenCV自带的例子,30行Python代码实现人脸检测,不得不说,Python这个语言的优势太明显了,几乎把所有复杂的细节都屏蔽了,虽然效率较差,不过在调用OpenCV的模块时,因为模块都是C ...
随机推荐
- KingbaseES 避免表的重写与数据类型二进制兼容
一.关于KingbaseES变更表结构表的重写: 1.修改表结构可能会导致表进行重写(表OID发生变化). 2.修改表结构带有索引或者字段类型长度或者精度操作时,会触发索引重建. 3.不修改列内容且旧 ...
- KingbaseES V8R6 集群运维案例 -- 自动故障转移失败处理
KingbaseES V8R6版本 数据库自动故障转移失败(Automatic Database Failover Fails) 适用于: KingbaseES V8R6 版本. repmgr配置信息 ...
- Windows配置Git本地仓库
git版本控制常用命令 1.配置身份信息 git config --global user.name "ycw.42624" # 名称 git config --global us ...
- WPF中动画教程(DoubleAnimation的基本使用)
实现效果 今天以一个交互式小球的例子跟大家分享一下wpf动画中DoubleAnimation的基本使用.该小球会移动到我们鼠标左键或右键点击的地方. 该示例的实现效果如下所示: 页面设计 xaml如下 ...
- js推送网页到扩展屏上--谷歌浏览器
平时我们推送网页.打开窗口都是用的 window.open,但是谷歌却不支持这种方法,也不是不支持,是可以打开窗口,但是无法将窗口移动到扩展屏上. 后面经过百度,发现了一个支持谷歌推送网页到扩展屏的方 ...
- Python删除文件、文件夹----os
使用 os 删除文件 import os '''删除文件 语法: os.unlink(path) 示例: 删除 b 文件夹中的 12.txt ''' os.unlink('b/12.txt') ...
- HarmonyOS音频开发指导:使用OpenSL ES开发音频播放功能
OpenSL ES全称为Open Sound Library for Embedded Systems,是一个嵌入式.跨平台.免费的音频处理库.为嵌入式移动多媒体设备上的应用开发者提供标准化.高性 ...
- 第十篇:异步IO、消息队列
一.协程 二.异步IO_Gevent 三.协程异步IO操作 四.事件驱动模型 五.IO多路复用 六.异步IO理论 一.回顾 线程 vs 进程 线程:CPU最小调度单位,内存共享: 线程同时修改同一份数 ...
- 最全能的AI换脸软件,FaceFusion下载介绍(可直播)
FaceFusion是一款多功能的AI换脸软件,它不仅能图片.视频换脸,还可以直播换脸,换脸效果真实.自然 与大多数换脸软件不同的是,FaceFusion不仅支持N卡处理程序(Azure),还额外提供 ...
- 用存储过程和 JAVA 写报表数据源有什么弊端?
我们在报表开发中经常会使用存储过程准备数据,存储过程支持分步计算,可以实现非常复杂的计算逻辑,为报表开发带来便利.所以,报表开发中这样的存储过程并不少见: 3008 行,141KB 的存储过程,会给报 ...