ContextSwitch 学习与使用
ContextSwitch 学习与使用
说明
github上面有一个简单的测试系统调用以及上下文切换的工具.
contextswitch.
下载之后直接make就可以进行简单的测试
需要注意的是 部分arm环境没有:
-mno-avx
这个参数, 需要去掉一下.
官方文档以及说明
Little micro-benchmarks to assess the performance overhead of context
switching.
timesyscall: Benchmarks the overhead of a system call.
timectxsw: Benchmarks the overhead of context switching between 2 processes.
timetctxsw: Benchmarks the overhead of context switching between 2 threads.
timectxswws: Benchmarks the overhead of context switching between 2 processes
using a working set of the size specified in argument.
timetctxsw2: Benchmarks the overhead of context switching between 2 threads,
by using a shed_yield() method.
If you do taskset -a 1, all threads should be scheduled on the
same processor, so you are really doing thread context switch.
Then to be sure that you are really doing it, just do:
strace -ff -tt -v taskset -a 1 ./timetctxsw2
Now why sched_yield() is enough for testing ? Because, it place
the current thread at the end of the ready queue. So the next
ready thread will be scheduled.
I also added sched_setscheduler(SCHED_FIFO) to get the best
performances.
From: https://github.com/tsuna/contextswitch
脚本说明
runbench() {
$* ./timesyscall
$* ./timectxsw
$* ./timetctxsw
$* ./timetctxsw2
}
每一组测试内的内容分别为:
1. 系统调用的时间.
2. 2个进程之间的上下文切换的时间.
3. 同一进程内的连个线程切换的时间.
4. shed_yield() method 方法的切换时间 (不太了解)
一共分为三组
第一组不进行设置
第二组绑定CPU但是在两个核心上
第三组绑定到同一个CPU核心上面.
测试结果说明
在我所有的测试环境内:
1. AMD 9T34 无可争议的排第一
2. 相同硬件不同操作系统的差异比较大, 如果比较必须使用相同的操作系统来进行.
3. 国产里面与SPECJVM和SPECCPU的结果完全一样.飞腾<海光<鲲鹏<阿里倚天
阿里倚天无可争议的王者.
4. 十年前的CPU的确不如现在新的CPU. 必须更新换代,性能更好,速度更快.
5. CPU绑核非常有用途,需要进行优化.
6. 协程,轻量级线程是未来. 只有这样性能才会好.
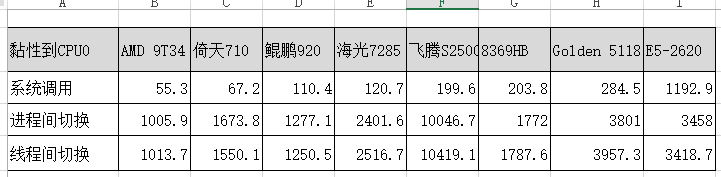
结果图表-1
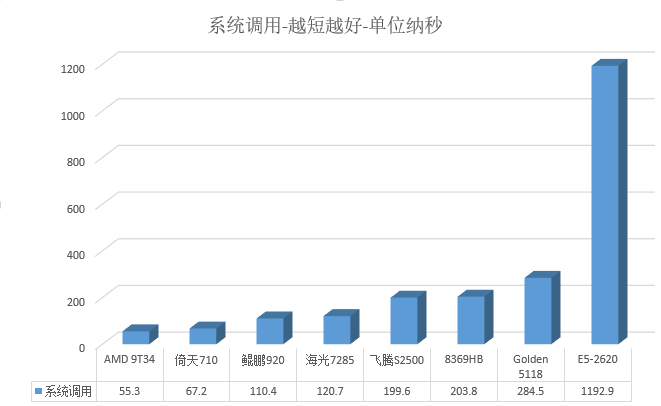
结果图表-2
E5-2620 2.0Ghz
2 physical CPUs, 6 cores/CPU, 2 hardware threads/core = 24 hw threads total
-- No CPU affinity --
10000000 system calls in 11841646290ns (1184.2ns/syscall)
2000000 process context switches in 6039748545ns (3019.9ns/ctxsw)
2000000 thread context switches in 6745297188ns (3372.6ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 755823488ns (377.9ns/ctxsw)
-- With CPU affinity --
10000000 system calls in 14343751134ns (1434.4ns/syscall)
2000000 process context switches in 16353343542ns (8176.7ns/ctxsw)
2000000 thread context switches in 13617487377ns (6808.7ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 2363107269ns (1181.6ns/ctxsw)
-- With CPU affinity to CPU 0 --
10000000 system calls in 11929472188ns (1192.9ns/syscall)
2000000 process context switches in 6915983386ns (3458.0ns/ctxsw)
2000000 thread context switches in 6837489882ns (3418.7ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 795652256ns (397.8ns/ctxsw)
Intel(R) Xeon(R) Gold 5118 CPU @ 2.30GHz 云海OS虚拟机
1 physical CPUs, 8 cores/CPU, 1 hardware threads/core = 8 hw threads total
-- No CPU affinity --
10000000 system calls in 2841917410ns (284.2ns/syscall)
2000000 process context switches in 7404178178ns (3702.1ns/ctxsw)
2000000 thread context switches in 7502081647ns (3751.0ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 222130514ns (111.1ns/ctxsw)
-- With CPU affinity --
10000000 system calls in 2835862084ns (283.6ns/syscall)
2000000 process context switches in 4990890087ns (2495.4ns/ctxsw)
2000000 thread context switches in 4311646652ns (2155.8ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 870608240ns (435.3ns/ctxsw)
-- With CPU affinity to CPU 0 --
10000000 system calls in 2844931708ns (284.5ns/syscall)
2000000 process context switches in 7601947691ns (3801.0ns/ctxsw)
2000000 thread context switches in 7914561498ns (3957.3ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 247057805ns (123.5ns/ctxsw)
Intel(R) Xeon(R) Gold 5118 CPU @ 2.30GHz 云海OS物理机
2 physical CPUs, 12 cores/CPU, 2 hardware threads/core = 48 hw threads total
-- No CPU affinity --
10000000 system calls in 5769760409ns (577.0ns/syscall)
2000000 process context switches in 7245677219ns (3622.8ns/ctxsw)
2000000 thread context switches in 7069213271ns (3534.6ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 475086926ns (237.5ns/ctxsw)
-- With CPU affinity --
10000000 system calls in 5762431985ns (576.2ns/syscall)
2000000 process context switches in 8692364627ns (4346.2ns/ctxsw)
2000000 thread context switches in 6572286258ns (3286.1ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 1304249661ns (652.1ns/ctxsw)
-- With CPU affinity to CPU 0 --
10000000 system calls in 5774310295ns (577.4ns/syscall)
2000000 process context switches in 6869635514ns (3434.8ns/ctxsw)
2000000 thread context switches in 6927117249ns (3463.6ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 473255745ns (236.6ns/ctxsw)
飞腾S2500-物理机器-NFSV3
2 physical CPUs, 128 cores/CPU, 1 hardware threads/core = 256 hw threads total
-- No CPU affinity --
10000000 system calls in 3838470070ns (383.8ns/syscall)
2000000 process context switches in 10913991269ns (5457.0ns/ctxsw)
2000000 thread context switches in 10987973614ns (5494.0ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 354962539ns (177.5ns/ctxsw)
-- With CPU affinity --
10000000 system calls in 3851009222ns (385.1ns/syscall)
2000000 process context switches in 10500204985ns (5250.1ns/ctxsw)
2000000 thread context switches in 8605107251ns (4302.6ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 1694906366ns (847.5ns/ctxsw)
-- With CPU affinity to CPU 0 --
10000000 system calls in 3871134715ns (387.1ns/syscall)
2000000 process context switches in 8211223439ns (4105.6ns/ctxsw)
2000000 thread context switches in 8915611368ns (4457.8ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 362941497ns (181.5ns/ctxsw)
飞腾S2500-物理机器-银河麒麟V10
model name : HUAWEI,Kunpeng 920
2 physical CPUs, 128 cores/CPU, 1 hardware threads/core = 256 hw threads total
-- No CPU affinity --
10000000 system calls in 1104251960ns (110.4ns/syscall)
2000000 process context switches in 5502095280ns (2751.0ns/ctxsw)
2000000 thread context switches in 5057680610ns (2528.8ns/ctxsw)
2000000 thread context switches in 159336010ns (79.7ns/ctxsw)
-- With CPU affinity --
10000000 system calls in 1104213220ns (110.4ns/syscall)
2000000 process context switches in 3157105260ns (1578.6ns/ctxsw)
2000000 thread context switches in 2749304460ns (1374.7ns/ctxsw)
2000000 thread context switches in 520588690ns (260.3ns/ctxsw)
-- With CPU affinity to CPU 0 --
10000000 system calls in 1104361790ns (110.4ns/syscall)
2000000 process context switches in 2554260900ns (1277.1ns/ctxsw)
2000000 thread context switches in 2501093900ns (1250.5ns/ctxsw)
2000000 thread context switches in 159835540ns (79.9ns/ctxsw)
飞腾S2500-KVM虚拟机
10000000 system calls in 2016128780ns (201.6ns/syscall)
2000000 process context switches in 20813179318ns (10406.6ns/ctxsw)
2000000 thread context switches in 21270077053ns (10635.0ns/ctxsw)
2000000 thread context switches in 283497350ns (141.7ns/ctxsw)
-- With CPU affinity --
10000000 system calls in 2003773606ns (200.4ns/syscall)
2000000 process context switches in 7149973534ns (3575.0ns/ctxsw)
2000000 thread context switches in 6041671015ns (3020.8ns/ctxsw)
2000000 thread context switches in 1184706267ns (592.4ns/ctxsw)
-- With CPU affinity to CPU 0 --
10000000 system calls in 1996452026ns (199.6ns/syscall)
2000000 process context switches in 20093433102ns (10046.7ns/ctxsw)
2000000 thread context switches in 20838253803ns (10419.1ns/ctxsw)
2000000 thread context switches in 284723964ns (142.4ns/ctxsw)
海光机器
model name : Hygon C86 7285 32-core Processor
pgrep: cannot allocate 4611686018427387903 bytes
2 physical CPUs, 32 cores/CPU, 2 hardware threads/core = 128 hw threads total
-- No CPU affinity --
10000000 system calls in 1188373575ns (118.8ns/syscall)
2000000 process context switches in 7182741168ns (3591.4ns/ctxsw)
2000000 thread context switches in 5057264353ns (2528.6ns/ctxsw)
2000000 thread context switches in 218741918ns (109.4ns/ctxsw)
-- With CPU affinity --
10000000 system calls in 1199538092ns (120.0ns/syscall)
2000000 process context switches in 4926579090ns (2463.3ns/ctxsw)
2000000 thread context switches in 4116607893ns (2058.3ns/ctxsw)
2000000 thread context switches in 877003690ns (438.5ns/ctxsw)
-- With CPU affinity to CPU 0 --
10000000 system calls in 1207213049ns (120.7ns/syscall)
2000000 process context switches in 4803238321ns (2401.6ns/ctxsw)
2000000 thread context switches in 5033478360ns (2516.7ns/ctxsw)
2000000 thread context switches in 218102516ns (109.1ns/ctxsw)
鲲鹏机器
2 physical CPUs, 128 cores/CPU, 1 hardware threads/core = 256 hw threads total
-- No CPU affinity --
10000000 system calls in 1628256836ns (162.8ns/syscall)
2000000 process context switches in 3567828849ns (1783.9ns/ctxsw)
2000000 thread context switches in 3366796751ns (1683.4ns/ctxsw)
2000000 thread context switches in 208056729ns (104.0ns/ctxsw)
-- With CPU affinity --
10000000 system calls in 3957162873ns (395.7ns/syscall)
2000000 process context switches in 66176473553ns (33088.2ns/ctxsw)
2000000 thread context switches in 64858764678ns (32429.4ns/ctxsw)
2000000 thread context switches in 9224336984ns (4612.2ns/ctxsw)
-- With CPU affinity to CPU 0 --
10000000 system calls in 1658580824ns (165.9ns/syscall)
2000000 process context switches in 4162672768ns (2081.3ns/ctxsw)
2000000 thread context switches in 3930988507ns (1965.5ns/ctxsw)
2000000 thread context switches in 206905930ns (103.5ns/ctxsw)
Intel 8369HB 3.3Ghz
10000000 system calls in 2039800553ns (204.0ns/syscall)
2000000 process context switches in 3484116193ns (1742.1ns/ctxsw)
2000000 thread context switches in 3504345370ns (1752.2ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 163336302ns (81.7ns/ctxsw)
-- With CPU affinity --
10000000 system calls in 2042749498ns (204.3ns/syscall)
2000000 process context switches in 3512477901ns (1756.2ns/ctxsw)
2000000 thread context switches in 3037479215ns (1518.7ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 589604636ns (294.8ns/ctxsw)
-- With CPU affinity to CPU 0 --
10000000 system calls in 2037861063ns (203.8ns/syscall)
2000000 process context switches in 3543912186ns (1772.0ns/ctxsw)
2000000 thread context switches in 3575216872ns (1787.6ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 164079529ns (82.0ns/ctxsw)
阿里倚天710
1 physical CPUs, 8 cores/CPU, 1 hardware threads/core = 8 hw threads total
-- No CPU affinity --
10000000 system calls in 672626352ns (67.3ns/syscall)
2000000 process context switches in 3586487130ns (1793.2ns/ctxsw)
2000000 thread context switches in 3228362627ns (1614.2ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 102817391ns (51.4ns/ctxsw)
-- With CPU affinity --
10000000 system calls in 672290182ns (67.2ns/syscall)
2000000 process context switches in 1990312435ns (995.2ns/ctxsw)
2000000 thread context switches in 1682598464ns (841.3ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 328222163ns (164.1ns/ctxsw)
-- With CPU affinity to CPU 0 --
10000000 system calls in 672409838ns (67.2ns/syscall)
2000000 process context switches in 3347526340ns (1673.8ns/ctxsw)
2000000 thread context switches in 3100110717ns (1550.1ns/ctxsw)
sched_setscheduler(): Operation not permitted
2000000 thread context switches in 102631615ns (51.3ns/ctxsw)
AMD 9T34
model name : AMD EPYC 9T34 64-Core Processor
1 physical CPUs, 8 cores/CPU, 2 hardware threads/core = 16 hw threads total
-- No CPU affinity --
10000000 system calls in 553414290ns (55.3ns/syscall)
2000000 process context switches in 1963917388ns (982.0ns/ctxsw)
2000000 thread context switches in 2131473467ns (1065.7ns/ctxsw)
2000000 thread context switches in 115396178ns (57.7ns/ctxsw)
-- With CPU affinity --
10000000 system calls in 554322086ns (55.4ns/syscall)
2000000 process context switches in 2730693871ns (1365.3ns/ctxsw)
2000000 thread context switches in 2559121196ns (1279.6ns/ctxsw)
2000000 thread context switches in 550724648ns (275.4ns/ctxsw)
-- With CPU affinity to CPU 0 --
10000000 system calls in 553295602ns (55.3ns/syscall)
2000000 process context switches in 2011838005ns (1005.9ns/ctxsw)
2000000 thread context switches in 2027328701ns (1013.7ns/ctxsw)
2000000 thread context switches in 114914625ns (57.5ns/ctxsw)
ContextSwitch 学习与使用的更多相关文章
- 从直播编程到直播教育:LiveEdu.tv开启多元化的在线学习直播时代
2015年9月,一个叫Livecoding.tv的网站在互联网上引起了编程界的注意.缘于Pingwest品玩的一位编辑在上网时无意中发现了这个网站,并写了一篇文章<一个比直播睡觉更奇怪的网站:直 ...
- Angular2学习笔记(1)
Angular2学习笔记(1) 1. 写在前面 之前基于Electron写过一个Markdown编辑器.就其功能而言,主要功能已经实现,一些小的不影响使用的功能由于时间关系还没有完成:但就代码而言,之 ...
- ABP入门系列(1)——学习Abp框架之实操演练
作为.Net工地搬砖长工一名,一直致力于挖坑(Bug)填坑(Debug),但技术却不见长进.也曾热情于新技术的学习,憧憬过成为技术大拿.从前端到后端,从bootstrap到javascript,从py ...
- 消息队列——RabbitMQ学习笔记
消息队列--RabbitMQ学习笔记 1. 写在前面 昨天简单学习了一个消息队列项目--RabbitMQ,今天趁热打铁,将学到的东西记录下来. 学习的资料主要是官网给出的6个基本的消息发送/接收模型, ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- Unity3d学习 制作地形
这周学习了如何在unity中制作地形,就是在一个Terrain的对象上盖几座小山,在山底种几棵树,那就讲一下如何完成上述内容. 1.在新键得项目的游戏的Hierarchy目录中新键一个Terrain对 ...
- 《Django By Example》第四章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:祝大家新年快乐,这次带来<D ...
- 菜鸟Python学习笔记第一天:关于一些函数库的使用
2017年1月3日 星期二 大一学习一门新的计算机语言真的很难,有时候连函数拼写出错查错都能查半天,没办法,谁让我英语太渣. 关于计算机语言的学习我想还是从C语言学习开始为好,Python有很多语言的 ...
- 多线程爬坑之路-学习多线程需要来了解哪些东西?(concurrent并发包的数据结构和线程池,Locks锁,Atomic原子类)
前言:刚学习了一段机器学习,最近需要重构一个java项目,又赶过来看java.大多是线程代码,没办法,那时候总觉得多线程是个很难的部分很少用到,所以一直没下决定去啃,那些年留下的坑,总是得自己跳进去填 ...
- node.js学习(三)简单的node程序&&模块简单使用&&commonJS规范&&深入理解模块原理
一.一个简单的node程序 1.新建一个txt文件 2.修改后缀 修改之后会弹出这个,点击"是" 3.运行test.js 源文件 使用node.js运行之后的. 如果该路径下没有该 ...
随机推荐
- BugBuilder: 高质量大规模缺陷库自动构建方法
摘要:本文提出并开发了高质量大规模缺陷库全自动构建方法BugBuilder,自动从版本控制系统中的人为编写的补丁中提取完整且精准的缺陷修复补丁. 本文分享自华为云社区<BugBuilder: 高 ...
- 解析Stream foreach源码
摘要:串行流比较简单,对于parallelStream,站在它背后的是ForkJoin框架. 本文分享自华为云社区<深入理解Stream之foreach源码解析>,作者:李哥技术 . 前言 ...
- 鸿蒙轻内核M核源码分析:数据结构之任务就绪队列
摘要:本文会给读者介绍鸿蒙轻内核M核源码中重要的数据结构,任务基于优先级的就绪队列Priority Queue. 本文分享自华为云社区<鸿蒙轻内核M核源码分析系列三 数据结构-任务就绪队列> ...
- PPT 动画入门
元素动画 进入动画 元素从无到有的过程 退出动画 元素从有到无的过程 退出动画和进入动画,一对一 强调动画 在元素上变化的过程(如放大) 动作路径 3D动画 三维动画 低版本不支持 组合动画 切换动画 ...
- PPT 动态迷幻图谱
迷幻动画的本质拆解 插件: islide + 软件: PowerPoint https://www.islide.cc/ 圆型 画一个正圆,无填充色,边框 2.25磅 左边红色.右边黄色.中间两个透明 ...
- 【邀请有礼】全球视频云创新挑战赛邀请有礼:参与 100% 获得 “壕” 礼,更有机会获得 JBL 音箱、Cherry 机械键盘
活动背景: 2021 年首届全球视频云创新挑战赛报名火热进行中,这里奖金池高达四十万,有业界顶尖专家指导,有展示自我技能的广阔舞台,还有入职阿里的绿色招聘通道.如果你有一点点心动,那请不要错过这场挑战 ...
- 创建QUERY报表
一.SQ02创建信息集 该事务代码用于查询需要的表,及表之间的关联关系 首先设置查询区域,标准区域中所建立的信息集仅在当前客户端使用,全局区域中建立的信息集可以跨client 创建信息集 选择基础表关 ...
- 【JAVA基础】常量变量维护
常量维护 //参与签名的系统Header前缀,只有指定前缀的Header才会参与到签名中 //换行符 private static final char LF = '\n'; public stati ...
- C++岗位面试真题宝典 -- 操作系统篇
2.1 Linux中查看进程运行状态的指令.查看内存使用情况的指令.tar解压文件的参数. 参考回答 查看进程运行状态的指令:ps命令."ps -aux | grep PID",用 ...
- POJ 2387 Til the Cows Come Home(最短路板子题,Dijkstra算法, spfa算法,Floyd算法,深搜DFS)
Til the Cows Come Home Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 43861 Accepted: 14 ...