BN层
论文名字:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
论文地址:https://arxiv.org/abs/1502.03167
BN被广泛应用于深度学习的各个地方,由于在实习过程中需要修改网络,修改的网络在训练过程中无法收敛,就添加了BN层进去来替换掉LRN层,网络可以收敛。现在就讲一下Batch Normalization的工作原理。
BN层和卷积层,池化层一样都是一个网络层。
首先我们根据论文来介绍一下BN层的优点
1)加快训练速度,这样我们就可以使用较大的学习率来训练网络。
2)提高网络的泛化能力。
3)BN层本质上是一个归一化网络层,可以替代局部响应归一化层(LRN层)。
4)可以打乱样本训练顺序(这样就不可能出现同一张照片被多次选择用来训练)论文中提到可以提高1%的精度。
前向计算和反向求导
在前向传播的时候:

从论文中给出的伪代码可以看出来BN层的计算流程是:
1.计算样本均值。
2.计算样本方差。
3.样本数据标准化处理。
4.进行平移和缩放处理。引入了γ和β两个参数。来训练γ和β两个参数。引入了这个可学习重构参数γ、β,让我们的网络可以学习恢复出原始网络所要学习的特征分布。
在反向传播的时候,通过链式求导方式,求出γ与β以及相关权值
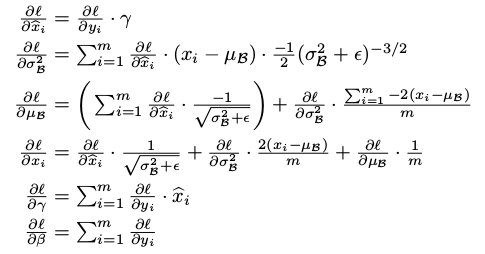
怎么使用BN层
先解释一下对于图片卷积是如何使用BN层。 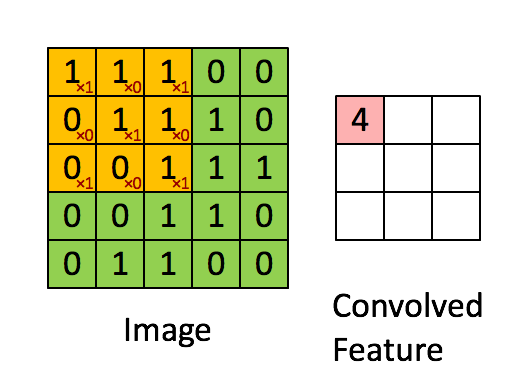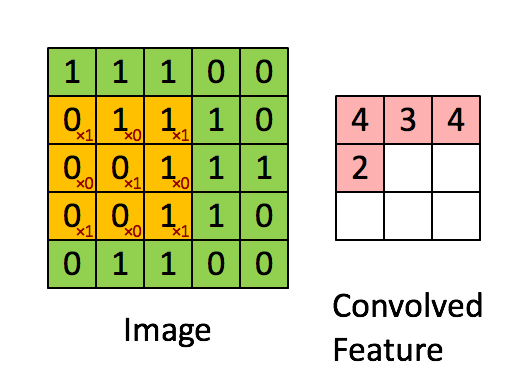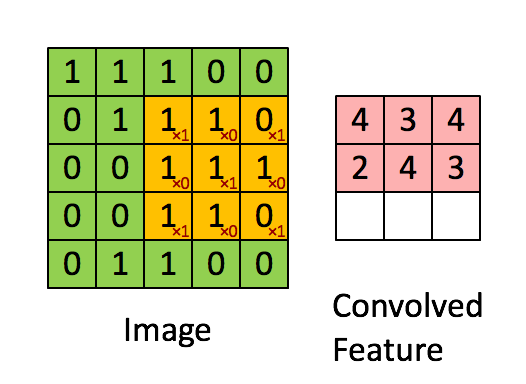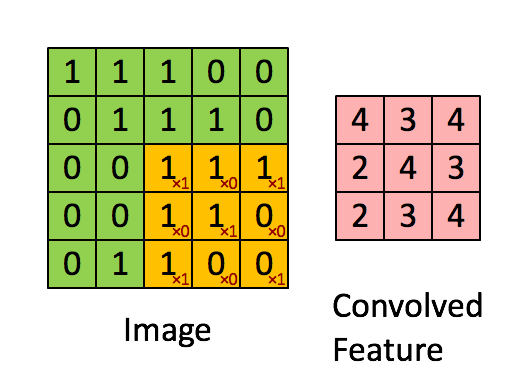
这是文章卷积神经网络CNN(1)中5x5的图片通过valid卷积得到的3x3特征图(粉红色)。特征图里的值,作为BN的输入,也就是这9个数值通过BN计算并保存γ与β,通过γ与β使得输出与输入不变。假设输入的batch_size为m,那就有m*9个数值,计算这m*9个数据的γ与β并保存。正向传播过程如上述,对于反向传播就是根据求得的γ与β计算梯度。
这里需要着重说明2个细节:
1.网络训练中以batch_size为最小单位不断迭代,很显然,新的batch_size进入网络,即会有新的γ与β,因此,在BN层中,有总图片数/batch_size组γ与β被保存下来。
2.图像卷积的过程中,通常是使用多个卷积核,得到多张特征图,对于多个的卷积核需要保存多个的γ与β。
结合论文中给出的使用过程进行解释 
输入:待进入激活函数的变量
输出:
1.对于K维的输入,假设每一维包含m个变量,所以需要K个循环。每个循环中按照上面所介绍的方法计算γ与β。这里的K维,在卷积网络中可以看作是卷积核个数,如网络中第n层有64个卷积核,就需要计算64次。
需要注意,在正向传播时,会使用γ与β使得BN层输出与输入一样。
2.在反向传播时利用γ与β求得梯度从而改变训练权值(变量)。
3.通过不断迭代直到训练结束,求得关于不同层的γ与β。如网络有n个BN层,每层根据batch_size决定有多少个变量,设定为m,这里的mini-batcherB指的是特征图大小*batch_size,即m=特征图大小*batch_size,因此,对于batch_size为1,这里的m就是每层特征图的大小。
4.不断遍历训练集中的图片,取出每个batch_size中的γ与β,最后统计每层BN的γ与β各自的和除以图片数量得到平均直,并对其做无偏估计直作为每一层的E[x]与Var[x]。
5.在预测的正向传播时,对测试数据求取γ与β,并使用该层的E[x]与Var[x],通过图中11:所表示的公式计算BN层输出。
注意,在预测时,BN层的输出已经被改变,所以BN层在预测的作用体现在此处
BN层原理分析
1 训练数据为什么要和测试数据同分布?
看看下图,如果我们的网络在左上角的数据训练的,已经找到了两者的分隔面w,如果测试数据是右下角这样子,跟训练数据完全不在同一个分布上面,你觉得泛化能力能好吗?

2 为什么白化训练数据能够加速训练进程
如下图,训练数据如果分布在右上角,我们在初始化网络参数w和b的时候,可能得到的分界面是左下角那些线,需要经过训练不断调整才能得到穿过数据点的分界面,这个就使训练过程变慢了;如果我们将数据白化后,均值为0,方差为1,各个维度数据去相关,得到的数据点就是坐标上的一个圆形分布,如下图中间的数据点,这时候随便初始化一个w,b设置为0,得到的分界面已经穿过数据了,因此训练调整,训练进程会加快

3、为什么BN层可以改善梯度弥散
下面xhat到x的梯度公式,可以表示为正常梯度乘一个系数a,再加b,这里加了个b,整体给梯度一个提升,补偿sigmod上的损失,改善了梯度弥散问题。

4、为什么BN层一般用在线性层和卷积层后面,而不是放在非线性单元后
原文中是这样解释的,因为非线性单元的输出分布形状会在训练过程中变化,归一化无法消除他的方差偏移,相反的,全连接和卷积层的输出一般是一个对称,非稀疏的一个分布,更加类似高斯分布,对他们进行归一化会产生更加稳定的分布。其实想想也是的,像relu这样的激活函数,如果你输入的数据是一个高斯分布,经过他变换出来的数据能是一个什么形状?小于0的被抑制了,也就是分布小于0的部分直接变成0了,这样不是很高斯了。
5、BN起作用的原因
通过使得批量数据归一化具有0均值1方差的统计分布,避免数据处于激活函数的饱和区,具有较大的梯度,从而加速网络的训练过程。
减少了网络输入变化过大的问题,使得网络的输入稳定,减弱了与前层参数关系之间的作用,使得当前层独立于整个网络
BN具有轻微正则化的效果,可以和dropout一起使用
主要是归一化激活值前的隐藏单元来加速训练,正则化是副作用
6、BN具有正则化效果的原因
每个批量的数据仅根据当前批量计算均值和标准差,然后缩放
这就为该批量的激活函数带来了一些噪音,类似于dropout向每一层的激活函数带来噪音
若使用了较大的batch_size如512,则减小了噪音,减少了正则化带来的效果
参考文献:
https://blog.csdn.net/donkey_1993/article/details/81871132
https://blog.csdn.net/qq_29573053/article/details/79878437
https://www.cnblogs.com/kk17/p/9693462.html
https://blog.csdn.net/u012151283/article/details/78154917
BN层的更多相关文章
- Tensorflow训练和预测中的BN层的坑
以前使用Caffe的时候没注意这个,现在使用预训练模型来动手做时遇到了.在slim中的自带模型中inception, resnet, mobilenet等都自带BN层,这个坑在<实战Google ...
- 【转载】 Caffe BN+Scale层和Pytorch BN层的对比
原文地址: https://blog.csdn.net/elysion122/article/details/79628587 ------------------------------------ ...
- 【转载】 Pytorch(1) pytorch中的BN层的注意事项
原文地址: https://blog.csdn.net/weixin_40100431/article/details/84349470 ------------------------------- ...
- 【转载】 【caffe转向pytorch】caffe的BN层+scale层=pytorch的BN层
原文地址: https://blog.csdn.net/u011668104/article/details/81532592 ------------------------------------ ...
- 【卷积神经网络】对BN层的解释
前言 Batch Normalization是由google提出的一种训练优化方法.参考论文:Batch Normalization Accelerating Deep Network Trainin ...
- Batch Normalization的算法本质是在网络每一层的输入前增加一层BN层(也即归一化层),对数据进行归一化处理,然后再进入网络下一层,但是BN并不是简单的对数据进行求归一化,而是引入了两个参数λ和β去进行数据重构
Batch Normalization Batch Normalization是深度学习领域在2015年非常热门的一个算法,许多网络应用该方法进行训练,并且取得了非常好的效果. 众所周知,深度学习是应 ...
- [转载] ReLU和BN层简析
[转载] ReLU和BN层简析 来源:https://blog.csdn.net/huang_nansen/article/details/86619108 卷积神经网络中,若不采用非线性激活,会导致 ...
- pytorch固定BN层参数
背景:基于PyTorch的模型,想固定主分支参数,只训练子分支,结果发现在不同epoch相同的测试数据经过主分支输出的结果不同. 原因:未固定主分支BN层中的running_mean和running_ ...
- 卷积层和BN层融合
常规的神经网络连接结构如下  当网络训练完成, 在推导的时候为了加速运算, 通常将卷积层和 batch-norm 层融合, 原理如下 \[ \begin{align*} y_{conv} & ...
随机推荐
- .NET RSA解密、签名、验签
using System; using System.Collections.Generic; using System.Text; using System.IO; using System.Sec ...
- liferay常用api总结
liferay之笑傲江湖学习笔记<一> 我们大家都知道,想要在一项技术上过硬,你需要付出汗水的,需要闭门修炼,每一个成功的人,都是那种耐得住寂寞的人,好了闲话少说.开始学习之旅 在life ...
- Linux其他:环境变量配置
计算机==>右键==>属性==>高级系统设置==>环境变量==> 系统变量path后面+';python路径名
- Linux基础命令---ar
ar ar指令可以创建.修改库,也可以从库中提取单个模块.库是一个单独的文件,里面包含了按照特定结构组织起来的其他文件,我们称作member.归档文件通常是一个二进制文件,我们一般将归档文件当作库来使 ...
- 怎么归档老日志的shell脚本
本脚本来自有学习阿铭的博文学习:工作中,需要用到日志切割logrotate,按照各自的需要切割.定义保留日志.提示:本文中的S全部都$符,不要问为什么,马云爸爸的社区就这样. #用途:日志切割归档.按 ...
- MySQL Crash Course #16# Chapter 24. Using Cursors + mysql 循环
mysql中游标的使用案例详解(学习笔记)这篇讲得相当直白好懂了. 索引: cursor 基础讲解 mysql 循环 书上的整合代码 cursor 基础讲解 cursor 有点类似于 JDBC 中的 ...
- Core Java 2
p267~p270: 1.一个方法不仅需要告诉编译器将要返回什么值, 还要告诉编译器有可能发生什么错误(以便在错误发生时用妥善的方式处理错误). 2.方法应该在首部声明所有可能抛出的异常. 3.方法抛 ...
- Jsp中如何通过Jsp调用Java类中的方法
Jsp中如何通过Jsp调用Java类中的方法 1.新建一个项目,在src文件夹下添加一个包:如:cn.tianaoweb.com; 2.再在包中添加一个类:如 package com; public ...
- ESOURCE_LOCKED - cannot obtain exclusive access to locked queue '2484_0_00163'
早上一运维同事说,一个报盘程序启动的时候报了"ESOURCE_LOCKED - cannot obtain exclusive access to locked queue '2484_0_ ...
- 03: centos中配置使用svn
1.1 centos7.3源码搭建svn----安装各种依赖包 1.安装zlib-1.2.8.tar.xz xz -d zlib-1.2.8.tar.xz tar xvf zlib-1.2.8.tar ...