C++读取文件统计单词个数及频率
1.Github链接
GitHub链接地址https://github.com/Zzwenm/PersonProject-C2
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 480 | 720 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 180 |
| • Design Spec | • 生成设计文档 | 30 | 40 |
| • Design Review | • 设计复审 | 40 | 60 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| • Design | • 具体设计 | 40 | 60 |
| • Coding | • 具体编码 | 150 | 180 |
| • Code Review | • 代码复审 | 120 | 180 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 60 | 40 |
| • Size Measurement | • 计算工作量 | 20 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 700 | 910 |
3.计算模块接口的设计与实现过程
/*定义words用于记录单词数量*/
typedef struct {
string word;
int num;
}words;
/*定义一个容量用于存单词,方便后续的单词排序*/
vector<words> v;
/*定义类File记录.txt文件的信息*/
class File {
private:
int character; //字符数
int word; //单词数
string filename; //文件名
public:
File();
File(string s); //通过命令行传参获取filename
void get_character();
void get_word();
void get_mostword();
void get_all();
};
/*分别统计字符数、统计单词数和统计最多的10个单词及其词频*/
程序通过命令行传参获取.txt文件记录到filename中便于成员函数使用读取文件。在调用成员函数统计时直接将字符数、单词数记录到file中,单词及单词出现个数记录到words中并存入容量v中。
基本功能:
1.统计字符数
直接读取文件每个字符记录即可
file >> noskipws;// 记录所有字符
file >> temp;
while (!file.eof())
{
character++;
file >> temp;
}
2.统计单词数
由于单词有规定:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
所以需要对文件内容进行筛选,将每个字符连接起来记录到string s中char a[2] = { temp,0 };s += temp;,在每遇到一个分隔符进行一次筛选。判断单词长度是否超过三,且前四个字符要都为英文字母,符合条件则到容量v中查找是否有相同单词并记录次数。一直读取到文件末尾即可。
3.统计文件的有效行数:任何包含非空白字符的行,都需要统计。
设立一个变量用于统计每行非空白字符是否为零即可,非零即为有效行数。
4.统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
在统计单词数时已经存到了容量v中,进行一次排序即可。可以利用sort函数对单词进行排序。
sort(v.begin(), v.end(), set_word);set_word为bool函数用于比较顺序
bool set_word(const words &a, const words &b) { if (a.num == b.num)return a.word<b.word;else return a.num>b.num; }
4.计算模块接口部分的性能改进
由于第一步实现基本功能时没有对基本功能进行分离,全部写在了同一部分中,所以需要从中分离出,删除掉没用的部分。字符统计可以直接提取出来写成一个函数,统计单词时只需要将字符统计部分删除掉结合class file统计即可。
5.计算模块部分单元测试展示。
TEST_METHOD(TestMethod1)
{
// TODO: 在此输入测试代码
myFile file("in.txt");
Assert::AreEqual(745,file.get_characters());
}
TEST_METHOD(TestMethod2)
{
// TODO: 在此输入测试代码
myFile file("in.txt");
Assert::AreEqual(72, file.get_words());
}
TEST_METHOD(TestMethod3)
{
// TODO: 在此输入测试代码
myFile file("in.txt");
Assert::AreEqual(11, file.get_lines());
}
测试出现问题失败了

经过多次测试发现将pch.cpp中的函数写在pch.h中就不会有报错。
上网查阅资料后发现在测试的cpp中加入
#include"../wordCount/pch.h"
#include"../wordCount/pch.cpp"
就可以解决问题。
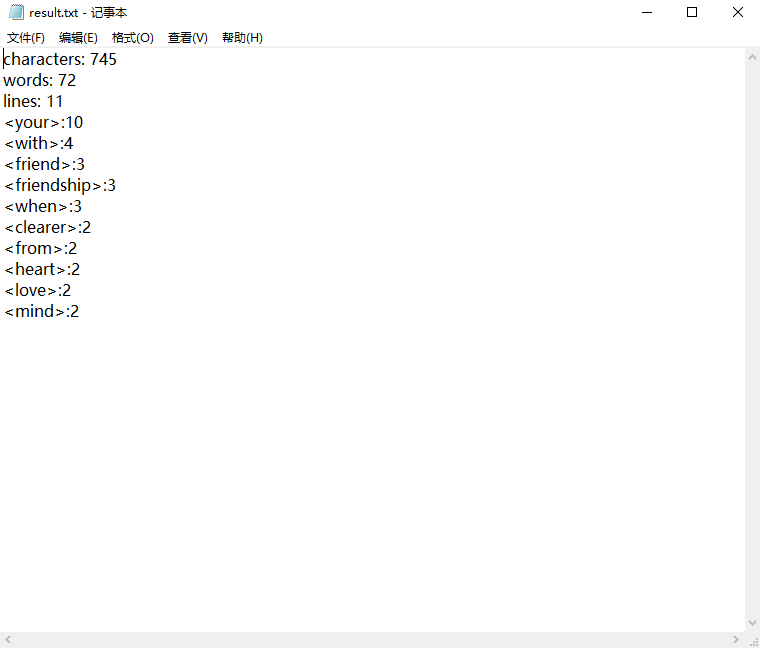
Assert::AreEqual(2230243,file.get_characters());// 测字符数
Assert::AreEqual(232213, file.get_words());//测单词数
Assert::AreEqual(15744, file.get_lines());//测有效行数

测试

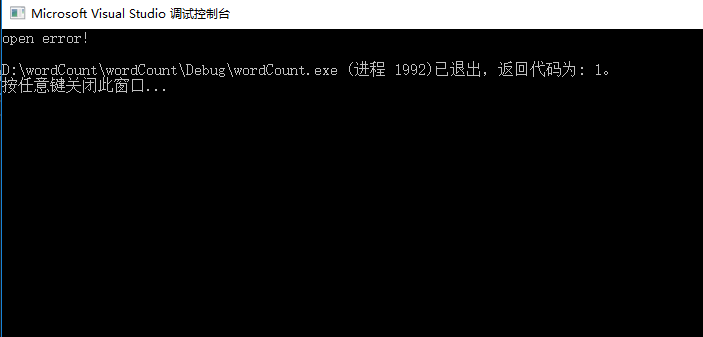
计算模块部分异常处理说明。
ifstream file(filename);
//添加错误提示说明 在读取文件失败时提示
if (!file)
{
cerr << "open error!" << endl;
exit(1);
}
感想
这次的代码及封装很早就完成实现了,大部分内容都需要在网上查阅资料学习,读取文件,输出文件,读取文件中的字符,单词的字典排序都需要上网学习一下,不过内容比较简单,很快就完成了。在封装的时候,由于个人的习惯,一直以来都没有面向对象的习惯,所以都将代码写在了main()函数中,所以在分离封装时又耗费了很久。同时也让我学会在编程时要学会封装接口,方便简洁。在弄单元测试时,新建测试时弄了预编译头,出现了意外的错误,上网查找了解决办法,修改了设置,弄得连最基本的调试都不能完成了。在修复后重新编写单元测试还是遇到这个问题,没有完成单元测试。在后续经过多次测试,终于找到了解决方法,也算是收获了单元测试。C++读取文件统计单词个数及频率的更多相关文章
- 第六章 第一个Linux驱动程序:统计单词个数
现在进入了实战阶段,使用统计单词个数的实例让我们了解开发和测试Linux驱动程序的完整过程.第一个Linux驱动程序是统计单词个数. 这个Linux驱动程序没有访问硬件,而是利用设备文件作为介质与应用 ...
- 第六章第一个linux个程序:统计单词个数
第六章第一个linux个程序:统计单词个数 从本章就开始激动人心的时刻——实战,去慢慢揭开linux神秘的面纱.本章的实例是统计一片文章或者一段文字中的单词个数. 第 1 步:建立 Linu x 驱 ...
- kwic--Java统计单词个数并按照顺序输出
2016-07-02(随笔写作时间) 写了好久的程序了为了避免以后用到.......... 是一个统计单词个数,并按照个数从大到小输出的.输入文件名OK 了 单词是按照首字母排序的,,,里面用到映射等 ...
- codevs1040统计单词个数(区间+划分型dp)
1040 统计单词个数 2001年NOIP全国联赛提高组 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题目描述 Description 给出一个长度不超 ...
- NOIP200107统计单词个数
NOIP200107统计单词个数 难度级别: A: 编程语言:不限:运行时间限制:1000ms: 运行空间限制:51200KB: 代码长度限制:2000000B 试题描述 给出一个长度不超过200的由 ...
- NOIP2001 统计单词个数
题三 统计单词个数(30分) 问题描述 给出一个长度不超过200的由小写英文字母组成的字母串(约定;该字串以每行20个字母的方式输入,且保证每行一定为20个).要求将此字母串分成k份(1<k&l ...
- Codevs_1040_[NOIP2001]_统计单词个数_(划分型动态规划)
描述 http://codevs.cn/problem/1040/ 与Codevs_1017_乘积最大很像,都是划分型dp. 给出一个字符串和几个单词,要求将字符串划分成k段,在每一段中求共有多少单词 ...
- luogu P1026 统计单词个数
题目链接 luogu P1026 统计单词个数 题解 贪心的预处理母本串从i到j的最大单词数 然后dp[i][j] 表示从前i个切了k次最优解 转移显然 代码 #include<cstdio&g ...
- Codevs 1040 统计单词个数
1040 统计单词个数 2001年NOIP全国联赛提高组 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题目描述 Description 给出一个长度不超过200的 ...
随机推荐
- vue的实例
vue的实例 创建一个vue实例的写法和创建一个变量一样 var vm = new Vue{{ //我们一般用vm来接收vue的实例,vm是 ViewModel的缩写 }} 然后,我们就可以给vue实 ...
- day 29 socketserver ftp功能的简单讲解
1.上传下载的简单示例 server: import socket import struct import json server =socket.socket() server.bind((' ...
- linux 下安装 Cisco Packet Tracer 7.11以及一些注意
https://blog.csdn.net/qq_35882901/article/details/77652571 https://linux.cn/article-5576-1.html 开启登录 ...
- go内建容器-字符和字符串操作
1.基础定义 在基础语法篇提到过golang的rune相当于其他编程语言的char,其本质是一个int32(四字节),用[]rune来转换一个字符串时,得到的是个解码后的结果,存储在新开辟的[]run ...
- python--模块之random随机数模块
作用是产生随机数 import random random.random:用于生成一个0--1的随机浮点数. print(random.random())>>0.3355102133472 ...
- PC平台逆向破解实验报告
PC平台逆向破解实验报告 实践目标 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串. 该程序同时包含另 ...
- 记录:C#监视某个文件的打开记录
首先,先说下为什么要搞这个: 1.首先,我的电脑里有5万左右的目录或文件,用于存放歌曲,数量众多.2.我不一定会用哪种软件听歌(不过也就是几种而已).3.我想在听歌的时候,检测哪首首歌被打开,能获取到 ...
- treetable--.net webform中树形table表管理的应用
好记性不如烂笔头. treetable 官网:http://ludo.cubicphuse.nl/jquery-treetable/#api 今天要做一个关于table的树节点展示,还有编辑,删除功能 ...
- linux下实现ssh无密码登录访问
在192.168.9.51机器上 1)运行:#ssh-keygen -t rsa 2)然后拍两下回车(均选择默认) 3)运行: #ssh-copy-id -i /root/.ssh/id_rsa.pu ...
- eclipse导入jmeter3.1源码并运行
jmeter3.1源码地址:https://archive.apache.org/dist/jmeter/source/ 1.打开eclipse,新建一个java project的项目,并点击next ...