Python爬虫教程-21-xpath 简介
本篇简单介绍 xpath 在python爬虫方面的使用,想要具体学习 xpath 可以到 w3school 查看 xpath 文档
xpath文档:http://www.w3school.com.cn/xpath/index.asp
Python爬虫教程-21-xpath
什么是 XPath?
- XPath 使用路径表达式在 XML 文档中进行导航
- XPath 包含一个标准函数库
- XPath 是 XSLT 中的主要元素
- XPath 是一个 W3C 标准
- 用途:它是一种用来确定XML文档中某部分位置的语言
- XPath开发工具:
- 开源的XPath表达式工具:XMLQuire
- Chrome 插件:XPath Helper
- FIrefox插件:XPath CHecker
- XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。但是XPath很快的被开发者采用来当作小型查询语言
- 在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点
xml案例py24.xml文件:https://xpwi.github.io/py/py爬虫/py24.xml
<?xml version="1.0" encoding="UTF-8" ?>
<booksore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<auther>Gidada De</auther>
<year>2018</year>
<price>23</price>
</book>
<book category="education">
<title lang="en">Python is Python</title>
<auther>Food War</auther>
<year>2008</year>
<price>83</price>
</book>
<book category="sport">
<title lang="en">Running</title>
<auther>Klaus Kuka</auther>
<year>2010</year>
<price>43</price>
</book>
</booksore>
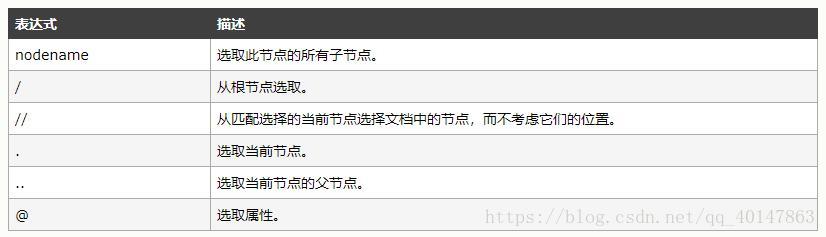
XPath 路径表达式
- XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
- 常用路径表达式:
- 实例:

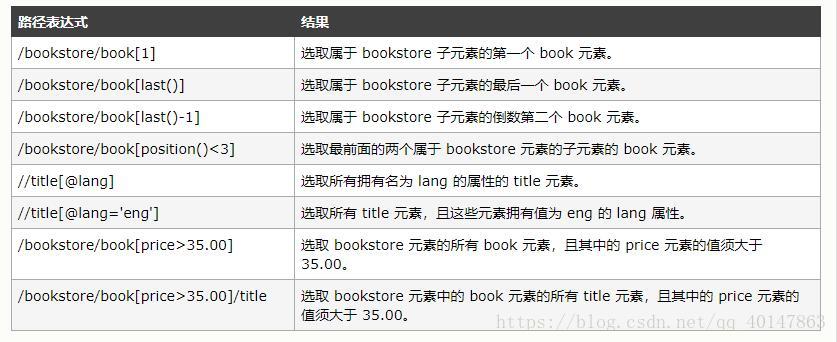
谓语(Predicates)
- 谓语用来查找某个特定的节点或者包含某个指定的值的节点
- 谓语被嵌在方括号中
- 实例:
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
选取未知节点
- XPath 通配符可用来选取未知的 XML 元素
- 实例:


选取若干路径
- 通过在路径表达式中使用“|”运算符,您可以选取若干个路径
- 实例:

更多文章链接:Python 爬虫随笔
- 图片来自w3school http://www.w3school.com.cn/xpath/xpath_syntax.asp
- 本笔记不允许任何个人和组织转载
Python爬虫教程-21-xpath 简介的更多相关文章
- Python爬虫教程-22-lxml-etree和xpath配合使用
Python爬虫教程-22-lxml-etree和xpath配合使用 lxml:python 的HTML/XML的解析器 官网文档:https://lxml.de/ 使用前,需要安装安 lxml 包 ...
- Python爬虫教程-20-xml 简介
本篇简单介绍 xml 在python爬虫方面的使用,想要具体学习 xml 可以到 w3school 查看 xml 文档 xml 文档链接:http://www.w3school.com.cn/xmld ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- Python爬虫教程-21-xpath
本篇简单介绍 xpath 在python爬虫方面的使用,想要具体学习 xpath 可以到 w3school 查看 xpath 文档 Python爬虫教程-21-xpath 什么是 XPath? XPa ...
- 小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(21):解析库 Beautiful Soup(上) 人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前 ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
随机推荐
- http请求全过程
第一步:浏览器生成http请求信息(第五层) 1.分解url 当用户输入网址时,浏览器会以一定的规则分解网址, 以 http://www.cemabenteng.com/dir/index.html ...
- Linux使用日志
Linux使用日志 ----------------------------------------------------------------------------- SecureCRTPor ...
- DIY FRDM-KL25Z开发环境 -- 基于GNU工具链
IDE大行其道的今天,一键make极大的便利了开发的同时,也每每让各种半路出家的猿们遇到工具链的问题感到束手无策(不就是说自己嘛?^_^!!!).也玩过不少板子了,始终没去深究工具链方面的问题,对于嵌 ...
- (转)linux shell 数字计算详解
代码中免不了要进行各种数据计算.抛开科学计算不提,普通的计算占地,百分比,同比,环比等需求就很常见.linux shell中进行数字计算,主要有如下几种方式: 1.bc bc是比较常用的linux计算 ...
- unity优化
1. 更新不透明贴图的压缩格式为ETC 4bit,因为android市场的手机中的GPU有多种,每家的GPU支持不同的压缩格式,但他们都兼容ETC格式, 2. 对于透明贴图,我们只能选择RGBA 16 ...
- Intel GPA 抓取3d模型
原文链接在这里 http://dev.cra0kalo.com/?p=213 背景信息 Intel的GPA本身是一款图形分析软件,并没有设计从3D程序里抓取模型资源的功能,但这里作者是通过hook G ...
- Java 二叉树一些基本操作
求二叉树中节点个数: /*1. 求二叉树中的节点个数 递归解法: (1)如果二叉树为空,节点个数为0 (2)如果二叉树不为空,二叉树节点个数 = 左子树节点个数 + 右子树节点个数 + 1 */ pu ...
- nginx自动部署脚本
需要下载脚本中需要的jar包nginx.pcre和zlib,自己也上传了一个自己部署的包 https://download.csdn.net/download/qq_17842663/10822976 ...
- Spring Boot学习笔记-配置devtools实现热部署
写在前面 Spring为开发者提供了一个名为spring-boot-devtools的模块来使Spring Boot应用支持热部署,提高开发者的开发效率,无需手动重启Spring Boot应用. de ...
- Intellij IDEA自定义类模板和方法模板
以Intellij IDEA 2017.3.5为例 定义类模板 依次打开File->Settings->File and Code Templates->Files, 选择class ...