Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找
Python爬虫教程-33-scrapy shell 的使用
- scrapy shell 的使用
- 条件:我们需要先在环境中,安装 scrapy 包,如果还没有安装,请参照:Python爬虫教程-30-Scrapy 爬虫框架介绍
- 为什么要使用 scrapy shell?
- 当我们需要爬取智联招聘,某一个岗位的信息的时候,如果我们当然不能简单的把整个页面的 HTML 都作为返回的结果吧,这时候我们需要提取数据,我们可以使用正则,但是呢使用正则由很容易出问题,也就需要我们不断地去调试,如果说对于一个较大的 Scrapy 项目去测试正则的结果是否正确,就过于麻烦了,这时候,我们要使用 scrapy shell 去调试,测试成功后,在拷贝到我们的项目中就可以了
- 怎么打开 scrapy shell?
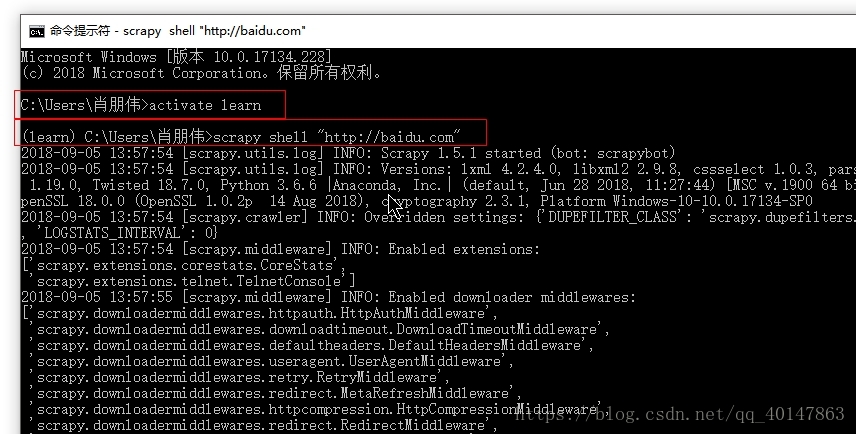
- 1.打开【cmd】
- 2.进入需要的 Anaconda 环境
- 例如:
我的环境名为:learn
activate learn
- 3.使用命令进入 scrapy shell "需要访问的地址"
例如:
scrapy shell "http://baidu.com"
- 4.操作截图:
这里会出现一大堆,不用管,最后会有一个代码输入的地方:
这里就是我们写代码的地方
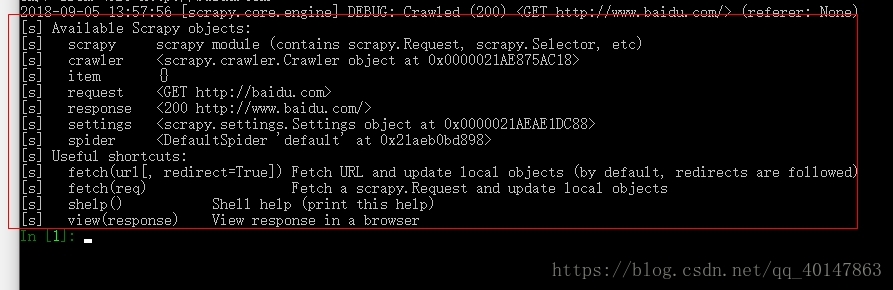
scrapy shell 的简单使用
- 1. response
- 执行命令之后,可以看到有很多 [s] 开头的东西,就是我们可以在下面代码输入框中使用的变量**
- 执行后,会自动将指定 url 的网页
- 下载完后,url 的内容保存在 response 的变量中
- response.body
- response.headers
- response.headers['Server']
- response.xpath() 使用 xpath
- response.css() 使用 css 语法选取内容
- 2.例如:我们使用:view(response):
- 截图:
- 结果就是调用浏览器,查看视图
- 截图:
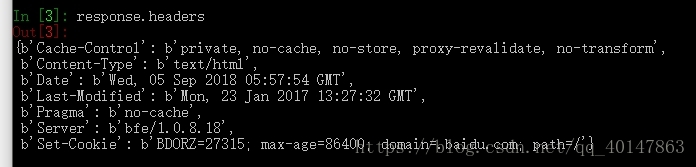
- 3.例如:我们想查看 headers 的内容:
- 使用:response.headers
- 截图:
- 4.一回车就执行了,怎样多行输入呢?
- 在 scrapy shell 中,我们只进行简单的多行输入,比如函数,for循环,更多的多个函数,特别多行的话,我们何尝不使用 Pycharm 呢,我们使用 scrapy shell 的目的就是简单执行,快速
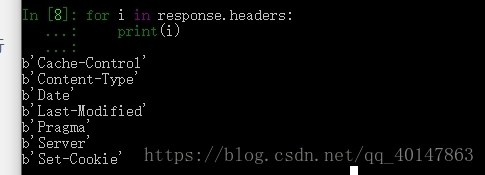
- 例如:for 循环打印 response.headers
- 截图:
- 这时候又有新的问题了,for 循环,可以多行了,但回车没法执行了
- 这时候使用的是:Ctrl + Enter 键执行
- 5.怎样输出属性的值呢?
- 例如:我们打印 response.headers 中的一个 Set-Cookie 项对于的值
- 截图:
- 6.selector
- 选择器,允许用户使用选择器来选择自己想要的内容
- response.selector.xpath:response.xpath 是 response.selector.xpath 的快捷方式
- response.selector.css:response.css 是 response.selector.css 的快捷方式
- selector.extract:把节点内容用 unicode 形式返回
- selector.re:允许用户通过正则选择内容


response.xpath 使用案例
- 1.使用 scrapy shell "http://baidu.com" 访问百度,得到response
- 2.目标:我们是想要找到这个页面的所有 div 头,并赋值给 divs
- 3.使用 len(divs) 查看共有多少个 div
- 4.我们输出下标为 0 的 div 头信息
- 操作截图:
- 5.这里只是头信息,想要获取 div 的内容代码
- 使用 divs[1].extract()
- 截图:


- 6.使用 xpath 精确查找
1.我们想找表格中的一个 a 标签
response.xpath( "//table/tr/td/a" )
- 2.//table 表示不管 table 在哪个标签的下面,找到所有的 table 标签
- 3.这里 / 只是表示在哪个标签里,是谁的子标签,不一定是儿子标签,也包括孙子标签
- 4.如果需要查找的页面有很多很多 a 标签,那么这样找,范围还是太宽了
5.按标签属性查找:
res_href = response.xpath( "//table/tr/td/a/@href" )
- 这时候,我就可以找到所有 a 标签的链接,我们可以打印一下链接
for i in res_href :
print( i.extract() )- 6.按标签属性的值查找:
- 例如:我们想要查找表格中一个 id = teacher 的一个列
res_href = response.xpath( "//table/tr/td[@id='teacher']" )
以上是使用 xpath 精确查找,当然也可以使用 re 正则 去查找,本篇就介绍到这里了,拜拜
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-33-scrapy shell 的使用的更多相关文章
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- Python爬虫教程-09-error 模块
Python爬虫教程-09-error模块 今天的主角是error,爬取的时候,很容易出现错,所以我们要在代码里做一些,常见错误的处,关于urllib.error URLError URLError ...
随机推荐
- JavaWeb后台从input表单获取文本值的两种方式
JavaWeb后台从input表单获取文本值的两种方式 #### index.html <!DOCTYPE html> <html lang="en"> & ...
- 基础篇:4.1)规范化:3d工程图纸出图步骤详解
本章目的:按照工程图出图步骤,更方便出具规范的工程图. 1.工程出图步骤 这是作者个人归纳的步骤,供同行业工程师参考完善. 以solidworks为例,工程出图步骤如下:1.1)打开绘制的3d零件图, ...
- C# 进程通信SendMessage和有关消息参数
SendMessage是啥? 函数原型: LRESULT SendMessage(HWND hWnd,UINT Msg,WPARAM wParam,LPARAM IParam)SendMessage( ...
- 查找Ubuntu下包的归属
今天在制作docker时,发现我的程序有些依赖的包不太好找应该安装什么. 在centos下面,可以用命令: rpm -qf <libraryname> 在Ubuntu下面,发现一个网站基本 ...
- Python Requests IP直连
import re import requests from urllib3.util import connection _orig_create_connection = connection.c ...
- unity动态加载FBX模型(Http下载到Rescources文件,场景Load直接调用):
using UnityEngine; using System.Collections; using System.IO; using System.Net; using System; using ...
- jQuery 学习笔记(jQuery: The Return Flight)
第一课. ajax:$.ajax(url[, settings]) 练习代码: $(document).ready(function() { $("#tour").on(" ...
- centos 7编译安装mysql 5.7.17
1.进入MySQL官网下载MySQL源代码 依次点击Downloads -> Community -> MySQL Community Server 源代码1.Select Operati ...
- jqueyr validtion的使用
江北机场对validtion的扩展 <script type="text/javascript"> $.validator.setDefaults({ /*关闭键盘输入 ...
- Mutex,Monitor,lock,MethodImplAttribute,SynchronizedAttribute的用法差异
1)Mutex:进程之间的同步(互斥量). 2)lock/Monitor……:线程同步.其中lock是Monitor的简化版本(直接生成try{Monitor.Enter(……)}finally{Mo ...