hadoop问题集(2)
28. Sqoop: java.lang.NullPointerException
sqoop import --connect jdbc:oracle:thin:@//xxxx:1521/aps --username xxx --password 'xxxx' --query " select REPORTNO, QUERYTIME, REPORTCREATETIME, NAME, CERTTYPE, CERTNO, USERCODE, QUERYREASON, HTMLREPORT, CREATETIME , to_char(SysDate,'YYYY-MM-DD HH24:mi:ss') as ETL_IN_DT from ZXC.HHICRQUERYREQ where \$CONDITIONS " --hcatalog-database BFMOBILE --hcatalog-table HHICRQUERYREQ --hcatalog-storage-stanza 'stored as ORC' --hive-delims-replacement " " -m 1
17/08/23 17:30:30 INFO Configuration.deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
17/08/23 17:30:31 INFO hcat.SqoopHCatUtilities: HCatalog table partitioning key fields = []
17/08/23 17:30:31 ERROR sqoop.Sqoop: Got exception running Sqoop: java.lang.NullPointerException
java.lang.NullPointerException
at org.apache.hive.hcatalog.data.schema.HCatSchema.get(HCatSchema.java:105)
at org.apache.sqoop.mapreduce.hcat.SqoopHCatUtilities.configureHCat(SqoopHCatUtilities.java:390)
at org.apache.sqoop.mapreduce.hcat.SqoopHCatUtilities.configureImportOutputFormat(SqoopHCatUtilities.java:783)
at org.apache.sqoop.mapreduce.ImportJobBase.configureOutputFormat(ImportJobBase.java:98)
at org.apache.sqoop.mapreduce.ImportJobBase.runImport(ImportJobBase.java:259)
at org.apache.sqoop.manager.SqlManager.importQuery(SqlManager.java:729)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:499)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:608)
at org.apache.sqoop.Sqoop.run(Sqoop.java:143)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:179)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:218)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:227)
at org.apache.sqoop.Sqoop.main(Sqoop.java:236)
17/08/23 17:30:31 INFO hive.metastore: Closed a connection to metastore, current connections: 0这里报了一个null pointer错误,十分让人费解.一开始以为是"HCatalog table partitioning key fields = []"引起的,使用sqoop import --verbose打印debug日志:
7/08/23 17:56:52 INFO Configuration.deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
17/08/23 17:56:53 INFO hcat.SqoopHCatUtilities: HCatalog table partitioning key fields = []
17/08/23 17:56:53 DEBUG util.ClassLoaderStack: Restoring classloader: sun.misc.Launcher$AppClassLoader@5474c6c
17/08/23 17:56:53 DEBUG manager.OracleManager$ConnCache: Caching released connection for jdbc:oracle:thin:@//XXX/XX/XXX
17/08/23 17:56:53 ERROR sqoop.Sqoop: Got exception running Sqoop: java.lang.NullPointerException
java.lang.NullPointerException
at org.apache.hive.hcatalog.data.schema.HCatSchema.get(HCatSchema.java:105)
at org.apache.sqoop.mapreduce.hcat.SqoopHCatUtilities.configureHCat(SqoopHCatUtilities.java:390)
at org.apache.sqoop.mapreduce.hcat.SqoopHCatUtilities.configureImportOutputFo发现并不是在那一步报错.后来查看oracle的表结构:
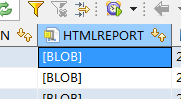
发现这个是BLOB.把sqoop脚本改为'BLOB' AS HTMLREPORT后,依然报错.
最后在网上找了一下:
https://community.hortonworks.com/questions/2168/javalangnullpointerexception-at-orgapachehivehcata.html
没看到啥有用的信息,但突然想着要比较一下字段类型,对比发现:
REPORTNO VARCHAR2
QUERYTIME VARCHAR2
REPORTCREATETIME VARCHAR2
NAME VARCHAR2
CERTTYPE VARCHAR2
CERTNO VARCHAR2
USERCODE VARCHAR2
QUERYREASON VARCHAR2
**HTMLREPORT BLOB**
CREATETIME VARCHAR2
reportno string
querytime string
reportcreatetime string
name string
certtype string
certno string
usercode string
queryreason string
createtime string
etl_in_dt string然后发现,据然TM的字段对不上,目标表根本没有HTMLREPORT字段!!MMP啊!修改后就好了.
总结:字段对不上会报java.lang.NullPointerException
29. sparksql报java.heap out of limit
如果下的sql:
select a.id,b.name from a join b on a.id = b.id and a.seri ='seq2007u123'改成:
select a.id,b.name from a join b on a.id = b.id and a.seri ='seq2007u123' and b.conta ='tx'
select x.id,y.name
(select a.id from a where a.seri ='seq2007u123') x join
(select a.id,b.name from a where b.conta ='tx' ) y
on x.id=y.id后,可能报这个错误.原因:
通过sparkUI看执行过程,发现在table scan阶段就挂了,并没有执行的到map阶段.
后经大神分析,原因是select a.id from a where a.seri ='seq2007u123'spark在分析时,认为其结果集少于10M,会进行广播,实际上该表有20亿行,这样buffer就不够用了.
解决办法,把大于多少M广播改小成1M.
30. SparkSql读写hive分区表时分区丢失
原因是SparkSql没用hcatalog而是用的自己的解析器解析的表结构,改成用hcatalog就可以了.另外在SparkSql中分区区分大小写.
大家好:
最近有同事反馈使用了Parquet之后,部分表的分区字段失效了。这个问题仅限于使用SparkSQL以及Hive On Spark模式。原因是使用Spark读写到Hive metastore Parquet table时,Spark SQL将会使用自己的Parquet而不是Hive的SerDes为了更好的性能。也就是直接使用Parquet文件的schema信息和Hive的schema信息两种不同的模式,他们的区别在于
1、Hive是不区分大小写的,但是Parquet区分
2、Hive认为所有的列是nullable,在Parquet中这只是列的一个特性。
也就是默认情况下,使用Spark引擎读写Hive表时,所有分区的操作都是区分大小写的。以下是对比测试



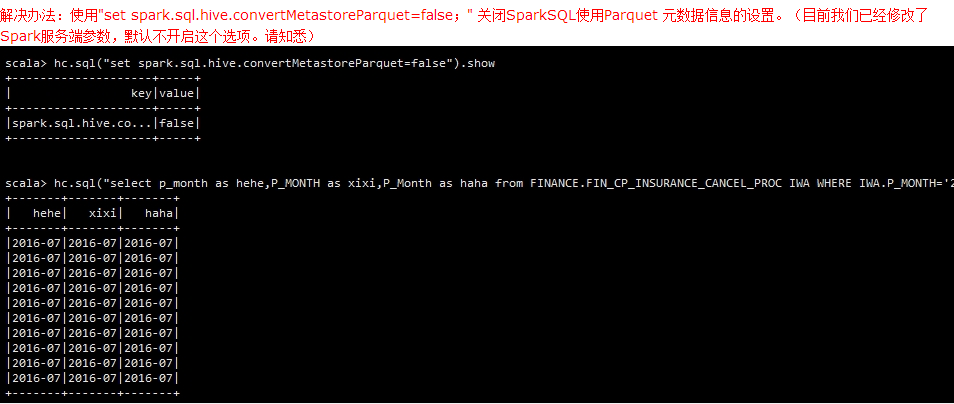
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
hadoop问题集(2)的更多相关文章
- Hadoop - Ambari集群管理剖析
1.Overview Ambari是Apache推出的一个集中管理Hadoop的集群的一个平台,可以快速帮助搭建Hadoop及相关以来组件的平台,管理集群方便.这篇博客记录Ambari的相关问题和注意 ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- hadoop的集群安装
hadoop的集群安装 1.安装JDK,解压jar,配置环境变量 1.1.解压jar tar -zxvf jdk-7u79-linux-x64.tar.gz -C /opt/install //将jd ...
- 大数据系列之Hadoop分布式集群部署
本节目的:搭建Hadoop分布式集群环境 环境准备 LZ用OS X系统 ,安装两台Linux虚拟机,Linux系统用的是CentOS6.5:Master Ip:10.211.55.3 ,Slave ...
- 基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍 在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1].为了从海量数据中获得洞察力,需要部署分布式深度学习.现有的DL框架通常需要为深度学习设置 ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- 暑假第二弹:基于docker的hadoop分布式集群系统的搭建和测试
早在四月份的时候,就已经开了这篇文章.当时是参加数据挖掘的比赛,在计科院大佬的建议下用TensorFlow搞深度学习,而且要在自己的hadoop分布式集群系统下搞. 当时可把我们牛逼坏了,在没有基础的 ...
- Hadoop基础-Hadoop的集群管理之服役和退役
Hadoop基础-Hadoop的集群管理之服役和退役 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在实际生产环境中,如果是上千万规模的集群,难免一个一个月会有那么几台服务器出点故 ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
随机推荐
- ASA 5.0/8.0/9.0 杂记
ASA 10.0 之前的版本都是使用odbc方式连接,由于某个项目的需求,无奈学习一下这些老掉牙的技巧. 1.新建 数据源 (不会的话,自行搜索一下) 2.使用 快捷方式 或者 其他方式 执行 C:\ ...
- Hadoop-Hive学习笔记(1)
1. Hive什么 a.Hive是基于Hadoop的一个数据仓库工具(注意不是数据仓库),将结构化的数据文件映射成一张数据库表. b.Hive是SQL的解析引擎,可以把sql语句转换成MapReduc ...
- 四、分离分层的 platform驱动
学习目标: 学习实现platform机制的分层分离,并基于platform机制,编写led设备和驱动程序: 一.分离分层 输入子系统.usb设备比驱动以及platform类型的驱动等都体现出分离分层机 ...
- 【Android】添加依赖包
貌似好像不知一种方法,以后有时间再研究,下面是其中的一种方法
- MAVLink功能开发,移植教程。
MAVLink功能开发 -----------------本文由"智御电子"提供,同时提供视频移植教程,以便电子爱好者交流学习.---------------- 1.MAVLink ...
- PyPI - Datetime
PyPI for Python 3.7 import datetime https://docs.python.org/3.7/library/datetime.html timedelta Obje ...
- Go搭建一个博客系统
go语言环境就不用多说了,版本肯定越高越好,这里用go1.10 先放着
- Div标签使用inline-block有间距
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 北京Uber优步司机奖励政策(12月17日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- MySql 使用explain分析查询
今天写了个慢到哭的查询,想用explain分析下执行计划,后来发现explain也是有局限性的: EXPLAIN不会告诉你关于触发器.存储过程的信息或用户自定义函数对查询的影响情况 •EXPLAIN不 ...