大数据系列之Hadoop分布式集群部署
本节目的:搭建Hadoop分布式集群环境
- 环境准备
- LZ用OS X系统 ,安装两台Linux虚拟机,Linux系统用的是CentOS6.5;Master Ip:10.211.55.3 ,Slave Ip:10.211.55.4
- 各虚拟机环境配置好Jdk1.8(1.7+即可)

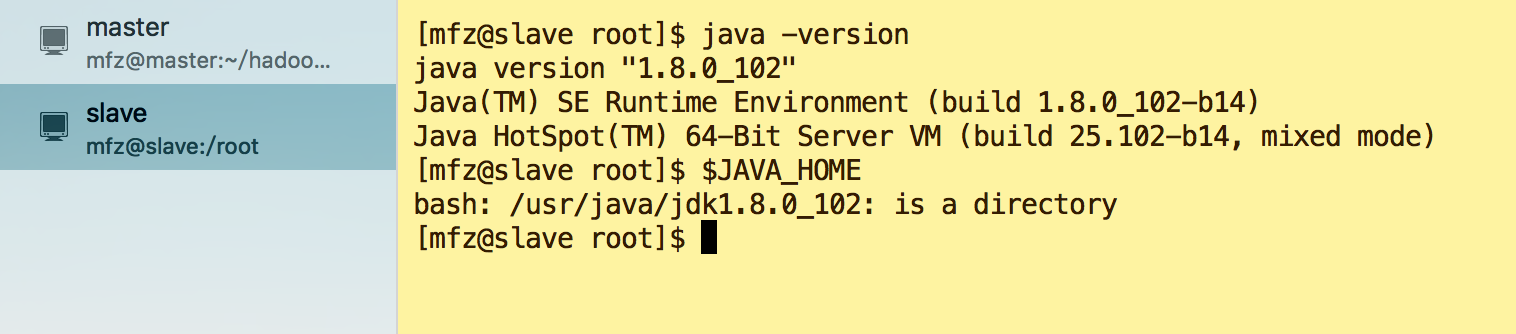
- 资料准备
- hadoop-2.7.3.tar.gz
- 虚拟机配置步骤
- 以下操作都在两台虚拟机 root用户下操作,切换至root用户命令
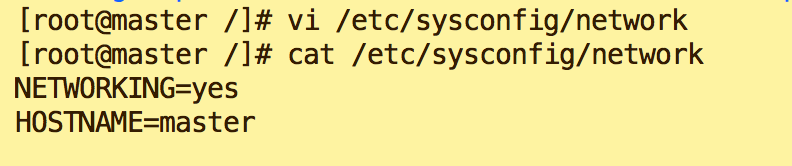
- 配置Master hostname 为Master ;
vi /etc/sysconfig/network
- 生效hostname
hostname master
检测主机名是否修改成功命令如下,在操作之前需要关闭当前终端,重新打开一个终端:即可看到终端命令前是[user@hostname]
- 按照步骤6+7 配置Slave hostname 为 Slave;
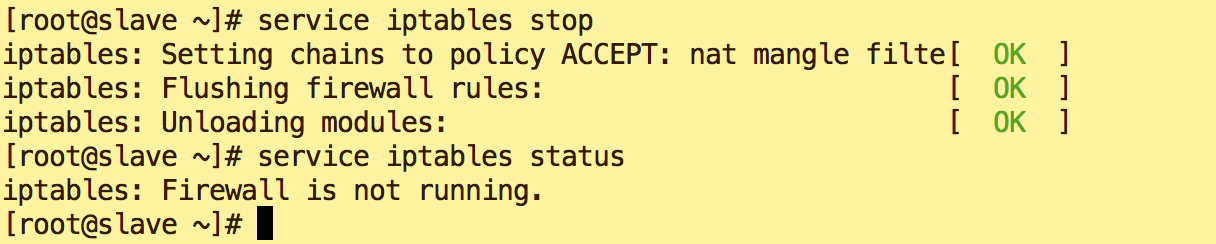
- 关闭Slave防火墙
service iptables stop
- 各虚拟机配置hosts列表,
vi /etc/hosts
添加内容(LZ master Ip是10.211.55.3,Salve Ip 是10.211.55.4)

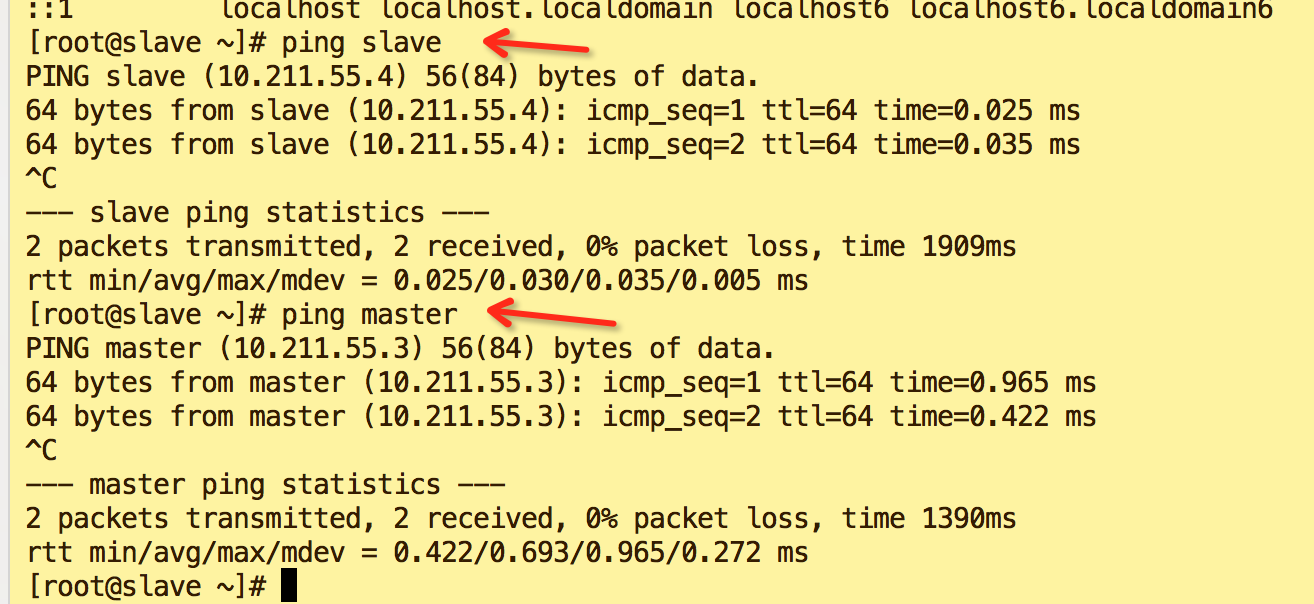
- 验证
ping slave
ping master如图表示修改成功
- 免密钥登录配置(此部分操作均在用户mfz下操作,切换至用户:su mfz)
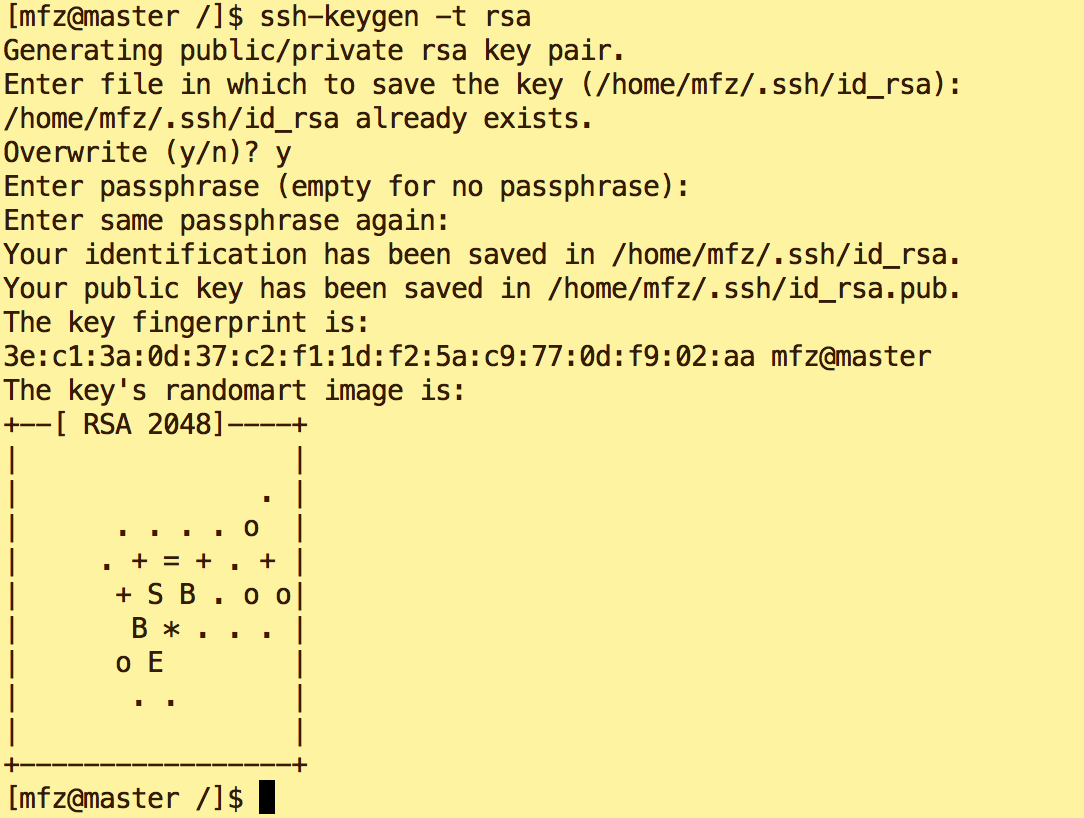
- Master节点上操作:
ssh-keygen -t rsa (多次回车(Enter)即可)
复制公钥文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
执行 ll查看

修改authorized_keys文件的权限,命令如下:
chmod ~/.ssh/authorized_keys (执行后文件权限为 -rw------- )
将authorized_keys文件复制到slave节点,命令如下:
scp ~/.ssh/authorized_keys mfz@slave:~/ (如果提示输入yes/no的时候,输入yes,回车密码是mfz slave登录密码)
- slave节点上操作
- 在终端生成密钥,命令如下(一路点击回车生成密钥)
ssh-keygen -t rsa
将authorized_keys文件移动到.ssh目录
mv authorized_keys ~/.ssh/
- 修改authorized_keys文件的权限,命令如下:
cd ~/.ssh
chmod authorized_keys - 验证免密钥登录 ,在master节点上执行命令如下
ssh slave
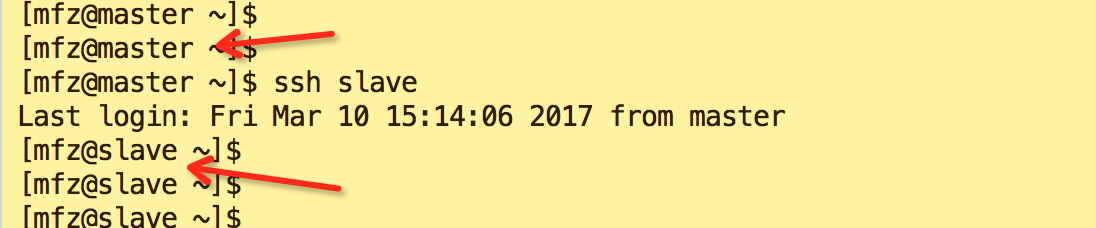 如果还提示输入slave登录密码则配置出错。检查步骤。
如果还提示输入slave登录密码则配置出错。检查步骤。
- Master节点上操作:
- Hadoop配置
每个节点上的Hadoop配置基本相同,在HadoopMaster节点操作,然后完成复制到另一个节点。下面所有的操作都使用mfz用户,切换mfz用户的命令是:su mfz
- 资源包上传到 /home/mfz/resources/下
-
- 执行命令,最后如果显示目录如下图则表示操作成功
cp /home/mfz/resources/hadoop-2.7..tar.gz /home/mfz/
cd /home/mfz
tar -xzvf hadoop-2.7..tar.gz
ll hadoop-2.7.
- 修改配置环境变量hadoop-env.sh 环境变量
vi /home/mfz/hadoop-2.7./etc/hadoop/hadoop-env.sh

配置hdfs-site.xml,添加\替换 如下
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>- 配置core-site.xml ,添加\替换 如下
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/mfz/hadoopdata</value>
<description>A base for other temporary directories.</description>
</property>
</configuration> - 修改yarn-env.sh 环境变量
vi yarn-env.sh

- 配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:</value>
</property>
</configuration> 配置计算框架mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xm --添加/替换 如下 <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>- 修改slaves文件,插入slave 节点hostname (可配置多个slave)
vi /home/mfz/hadoop-2.7./etc/hadoop/slaves
cat /home/mfz/hadoop-2.7./etc/hadoop/slaves
复制到从节点(使用下面的命令将已经配置完成的Hadoop复制到从节点HadoopSlave上) (可复制到多个slave)
cd
scp -r hadoop-2.7. slave:~/ --注意:因为之前已经配置了免密钥登录,这里可以直接远程复制。
- 运行验证-启动Hadoop集群
- 该节的配置需要同时在两个节点(HadoopMaster和HadoopSlave)上进行操作
- 操作命令如下:(LZ 环境变量统一放在了/etc/profile 下,也可放于单个用户~/.base_profile 下)
cd
vi /etc/profile 添加如下内容 #HADOOP
export HADOOP_HOME=/home/mfz/hadoop-2.7.
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH 生效配置
source /etc/profile 创建数据目录(该节的配置需要同时在两个节点(HadoopMaster和HadoopSlave)上进行操作。)
cd
mkdir hadoopdata
说明:(在用户mfz主目录下操作,此hadoopData目录是hadoop-2.7.3/etc/hadoop/core-site.xml 中hadoop.tmp.dir 的 value)- 格式化文件系统 ---格式化命令如下,该操作需要在HadoopMaster节点上执行:
hdfs namenode -format
- 如果出现ERROR/Exception 则表示出现问题了。自行百度解决。。。
- Master节点上启动hadoop 集群
cd /home/mfz/hadoop-2.7./ sbin/start-all.sh
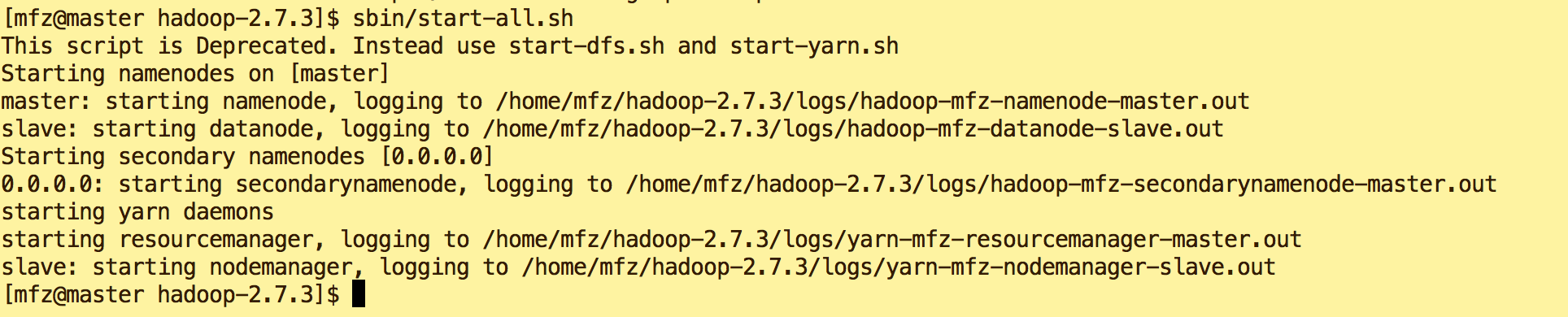
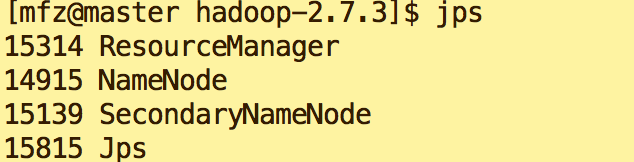
在master的终端执行jps命令,在打印结果中会看到4个进程,分别是ResourceManager、Jps、NameNode和SecondaryNameNode,如下图所示。如果出现了这4个进程表示主节点进程启动成功。
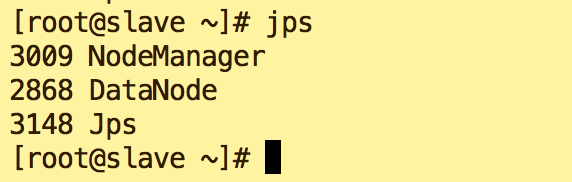
在slave的终端执行jps命令,在打印结果中会看到3个进程,分别是NodeManager、DataNode和Jps,如下图所示。如果出现了这3个进程表示从节点进程启动成功。
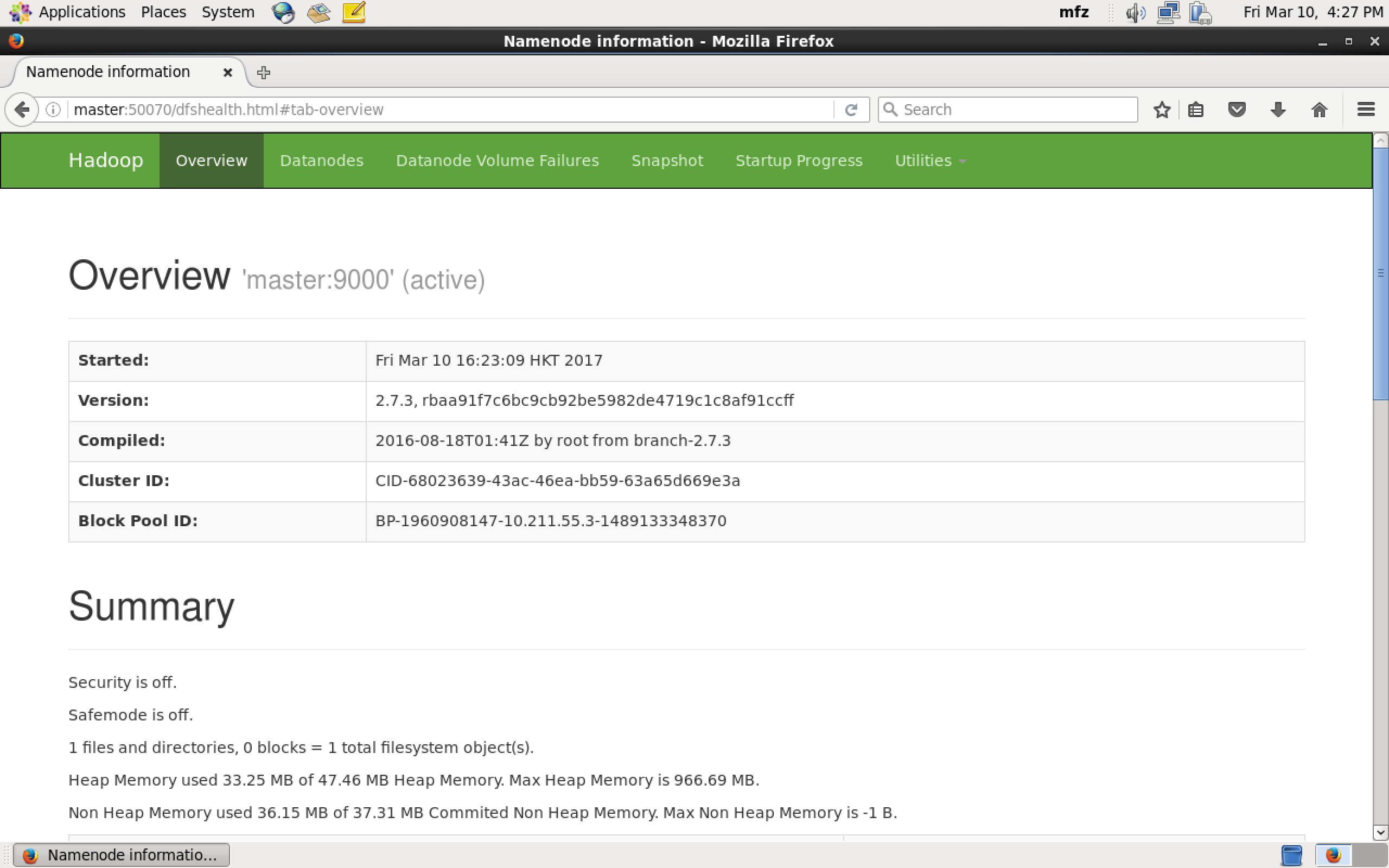
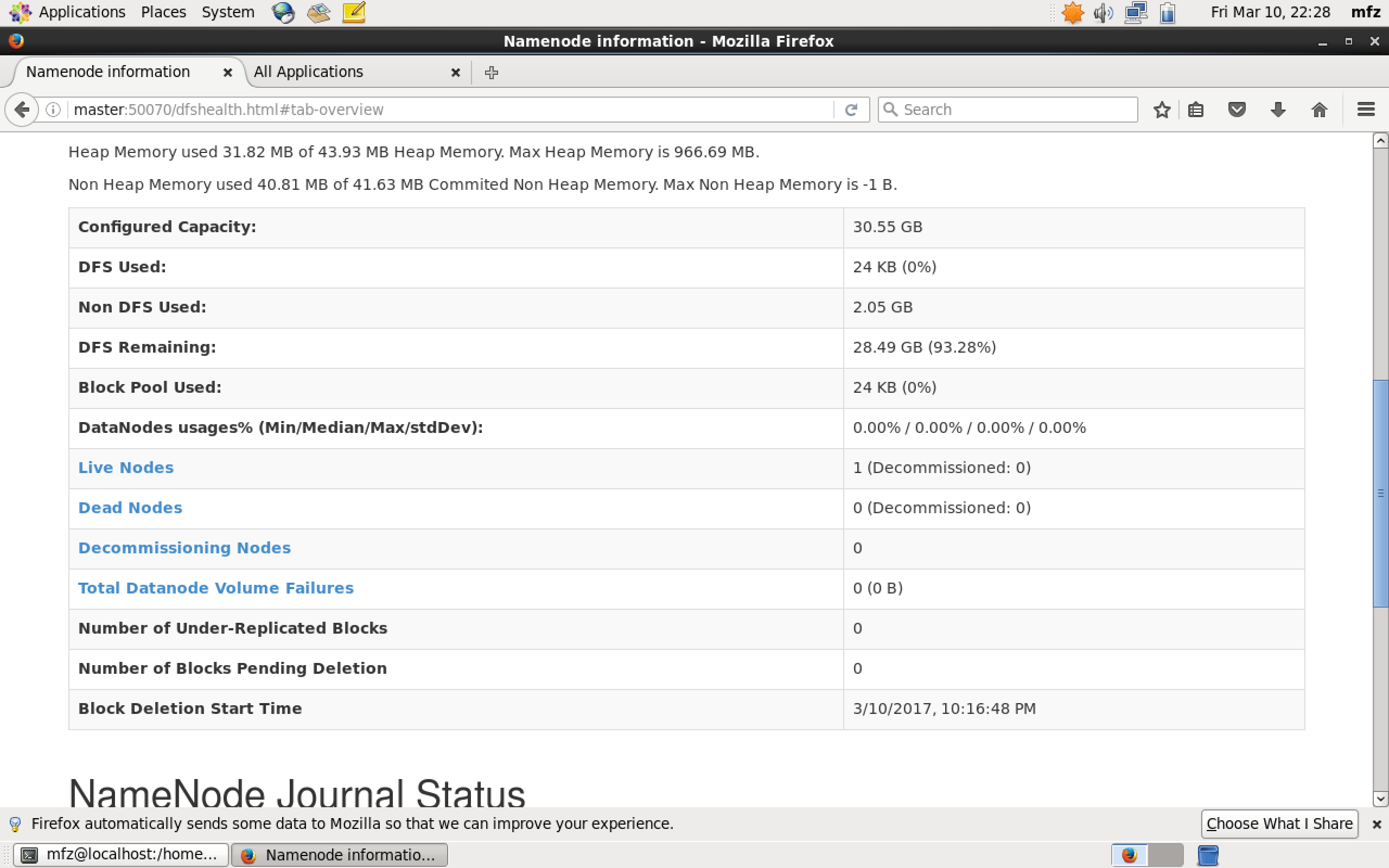
验证1:Web UI查看集群是否成功启动,在Master上启动Firefox浏览器,在浏览器地址栏中输入输入http://master:50070/,检查namenode 和datanode 是否正常。UI页面如下图所示。
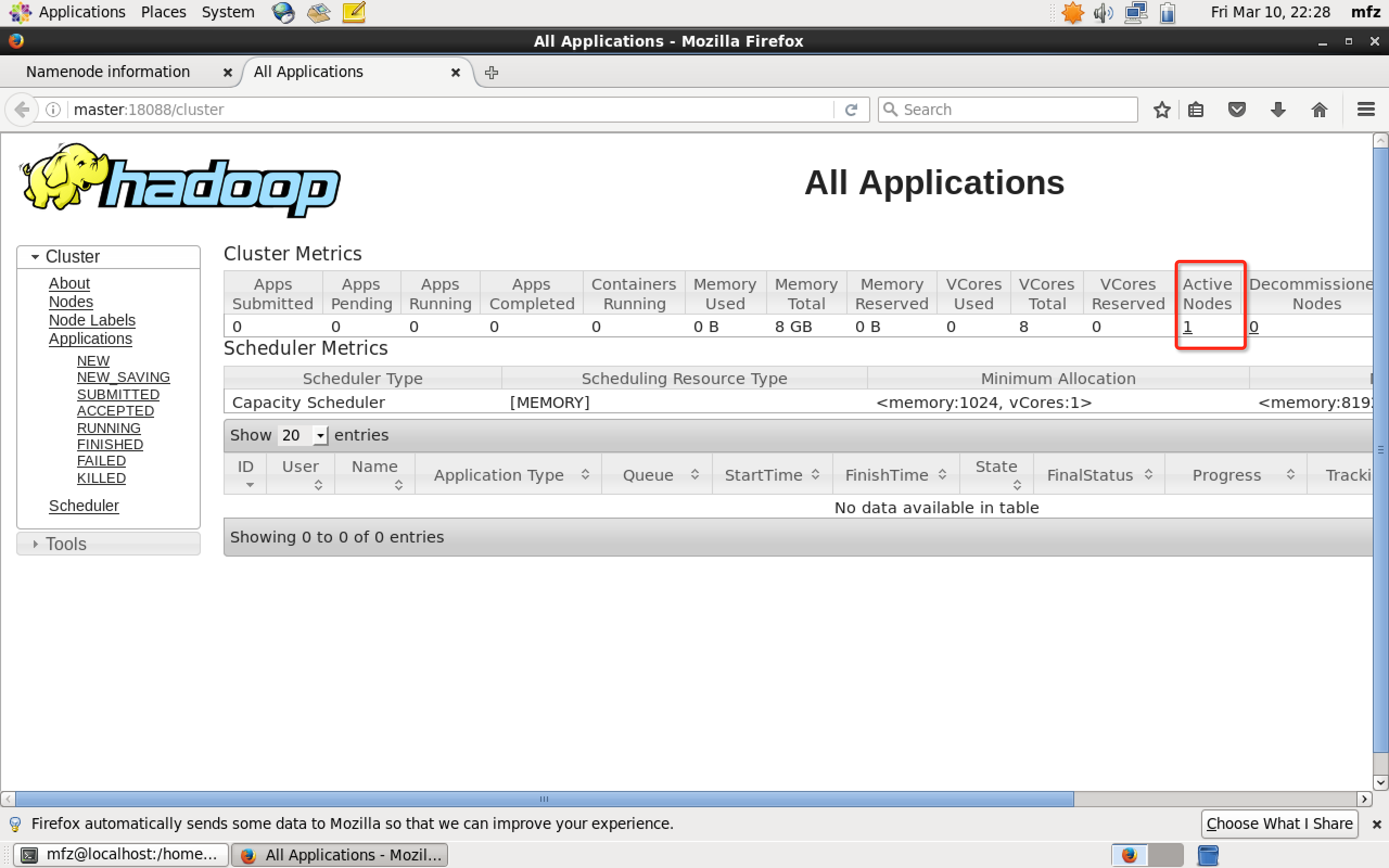
验证2: 在Master上启动Firefox浏览器,在浏览器地址栏中输入输入http://master:18088/,检查Yarn是否正常,页面如下图所示。
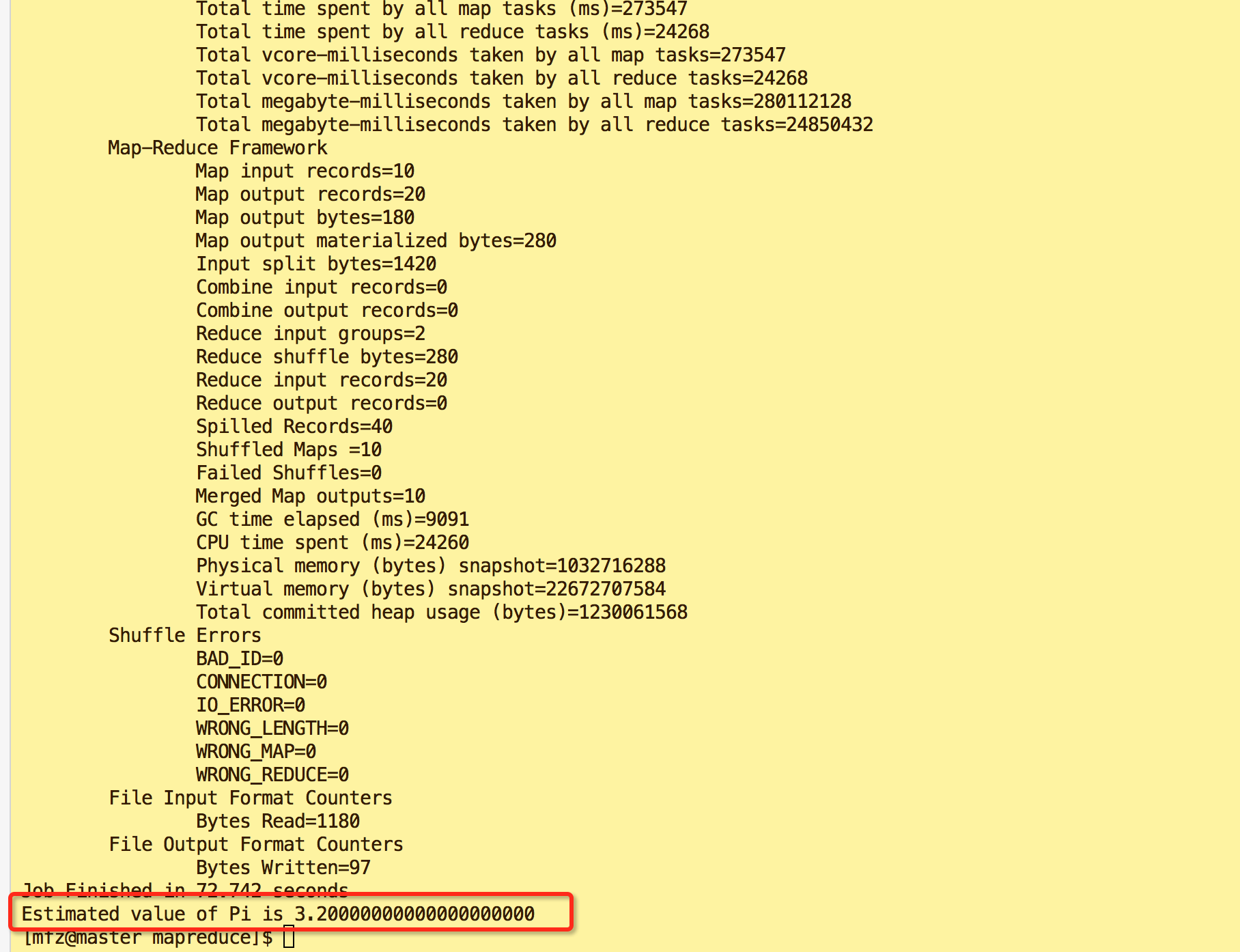
- 验证3:mfz用户下输入如下命令,得到结果最后输出'Job Finished in 72.742 seconds Estimated value of Pi is 3.20000000000000000000'则表示操作成功。
cd
cd hadoop-2.7./share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-2.7..jar pi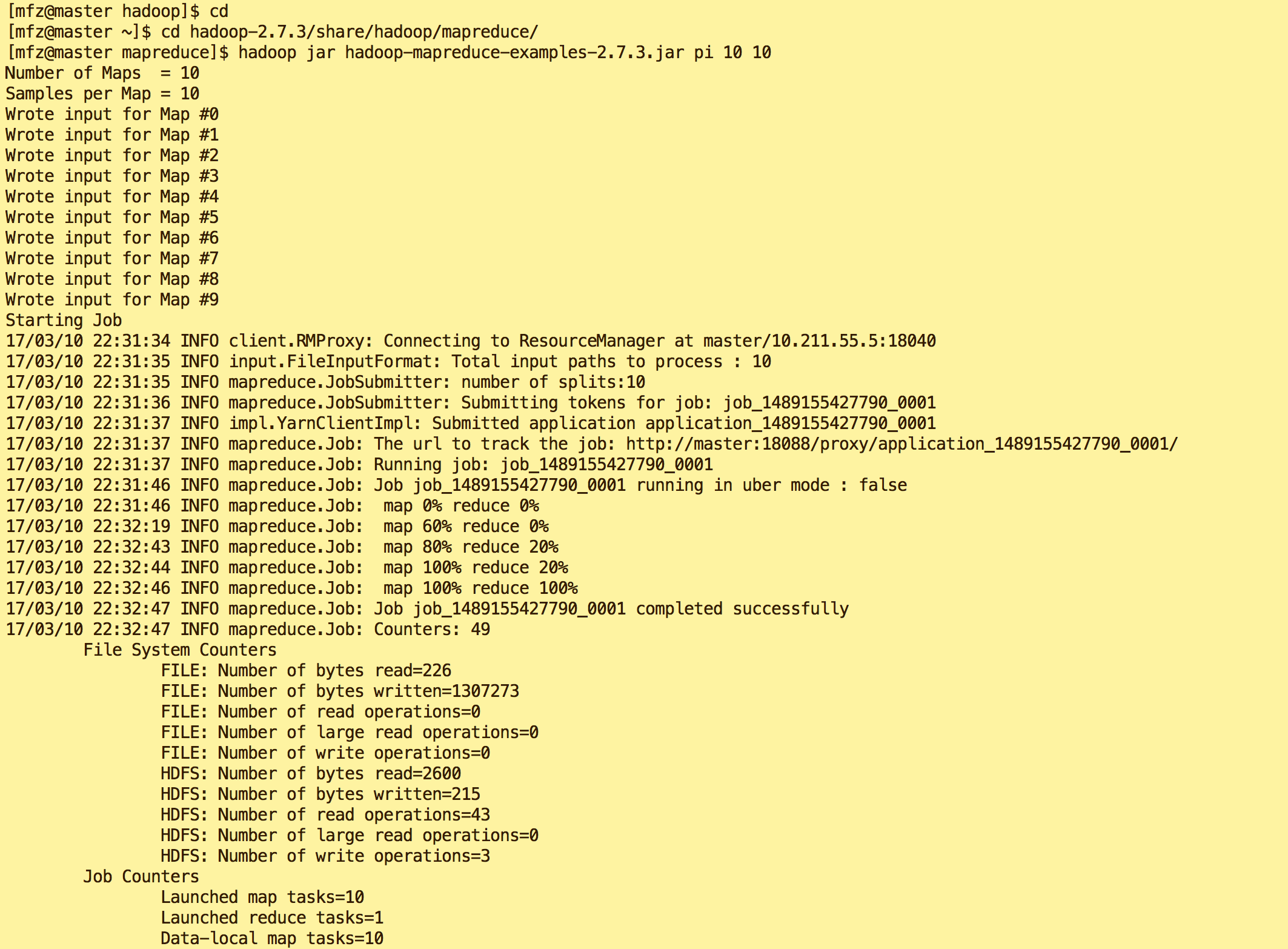
- 以上3个步骤验证都没有问题的话表示你成功完成了Hadoop分布式集群搭建。:)
验证启动结果

大数据系列之Hadoop分布式集群部署的更多相关文章
- Hadoop分布式集群部署(单namenode节点)
Hadoop分布式集群部署 系统系统环境: OS: CentOS 6.8 内存:2G CPU:1核 Software:jdk-8u151-linux-x64.rpm hadoop-2.7.4.tar. ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- hadoop分布式集群部署①
Linux系统的安装和配置.(在VM虚拟机上) 一:安装虚拟机VMware Workstation 14 Pro 以上,虚拟机软件安装完成. 二:创建虚拟机. 三:安装CentOS系统 (1)上面步 ...
- 大数据平台搭建-hadoop/hbase集群的搭建
版本要求 java 版本:1.8.*(1.8.0_60) 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl ...
- Hadoop实战:Hadoop分布式集群部署(一)
一.系统参数优化配置 1.1 系统内核参数优化配置 修改文件/etc/sysctl.conf,使用sysctl -p命令即时生效. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ...
- 大数据【三】YARN集群部署
一 概述 YARN是一个资源管理.任务调度的框架,采用master/slave架构,主要包含三大模块:ResourceManager(RM).NodeManager(NM).ApplicationMa ...
- Hadoop分布式集群部署
环境准备 IP HOSTNAME SYSTEM 192.168.131.129 hadoop-master CentOS 7.6 192.168.131.135 hadoop-slave1 CentO ...
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍 在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1].为了从海量数据中获得洞察力,需要部署分布式深度学习.现有的DL框架通常需要为深度学习设置 ...
随机推荐
- zoj-3782-Ternary Calculation
题目链接 http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=5269 题目很简单,直接把所有情况列出来. 我的AC代码 #inclu ...
- HTML <div> 和<span>
HTML <div> 和<span> HTML 可以通过 <div> 和 <span>将元素组合起来. HTML 区块元素 大多数 HTML 元素被定义 ...
- 支付宝开发中return_url和notify_url的区别分析
在处理支付宝业务中出现过这样的问题,付费完成后,在支付宝跳转到商家指定页面时,订单状态已经更新,通过调试发现是支付宝先通知notify_url,完成了订单状态. 支付宝return_url和notif ...
- JSP EL表达式忽略方法
JSP EL表达式忽略方法: web.xml中,和jsp中:jsp中的等级要高一些: web.xml: <?xml version="1.0" encoding=" ...
- spring mvc 与 jasper Report集成
http://blog.csdn.net/jia20003/article/details/8471169 注意其中的图片地址说明: 如果有子报表,也会到class文件夹中去寻找: 如果子报表有路径的 ...
- 不要怂,就是GAN (生成式对抗网络) (四):训练和测试 GAN
在 /home/your_name/TensorFlow/DCGAN/ 下新建文件 train.py,同时新建文件夹 logs 和文件夹 samples,前者用来保存训练过程中的日志和模型,后者用来保 ...
- 算法笔记_017:递归执行顺序的探讨(Java)
目录 1 问题描述 2 解决方案 2.1 问题化简 2.2 定位输出测试 2.3 回顾总结 1 问题描述 最近两天在思考如何使用蛮力法解决旅行商问题(此问题,说白了就是如何求解n个不同字母的所有不同排 ...
- Dynamics CRM 2015-Auto Save
Auto Save,顾名思义,就是不需要明确地点击Save按钮,自动保存.这个功能在创建CRM Organization的时候,默认是开启的. 需要注意的是: 1. Auto Save适用于Main ...
- linux-Centos6.5中nginx1.63源码安装
我自己在学习的过程中,搜索网上的教程,碰了很多壁,终于总结出自己一套易于配置和管理的安装方法 如果是用于生产环境,不用盲目追求最新版本,跟着我这个来就好了. 安装前预热: 1.创建nginx专属用户: ...
- JS闭包深入理解(理解篇)
看书的时候很是不明白为啥变量老是五,经过认真思考的出一下理解: function box() { var arr = []; for (var i = 0; i < 5; i++) { ...