Matplotlib处理csv文件
csv模块包含在python标准库中,可用于分析CSV文件中的数据行,让我们能够快速提取感兴趣的值。首先绘制一个简单的折线图:
1 #!usr/bin/env python
2 #*-*Coding=UTF-8 *-*
3 import csv #导入csv模块
4 from matplotlib import pyplot as plt
5
6 filename = 'sitka_weather_07-2014.csv' #要处理的文件名,2014年7月的数值
7
8 with open(filename) as file_object: #打开文件filename并且将结果文件对象存储在file_object中
9 reader = csv.reader(file_object) #调用csv.reader()将文件对象file_object作为实参传递给阅读器reader
10 header_row = next(reader) #调用一次next,得到文件的第一行
11 row_2 = next(reader) #再调用一次next,就会得到文件第二行的内容
12 #print(header_row,row_2)
13
14 #文件头的格式并非总是一致,空格和单位可能总是出现在奇怪的地方。这在原始数据文件中很常见,但不会带来任何问题
15 #为让文件头更容易理解,将列表中的每个头文件及其位置打印出来
16 for index, column_header in enumerate(header_row): #调用enumerate()来获取每个元素的索引及其值。
17 print(index, column_header) #打印索引,还有对应的值
18
19 #提取并读取数据
20 highs = [] #创建空列表来存储最高气温
21 for row in reader: #在文件对象中循环读取每一行
22 print(row,"\n") #打印文件对象中的所有行
23 print(type(row[1])) #查看第一行第一列数据类型
24 #highs.append(row[1]) #把每一行索引为1的值(字符串)附加到列表,也就是文件中我们所需的最高气温
25 high = int(row[1]) #将每一行的索引值为1的类型为字符串的值转化成整型以便绘制图形
26 highs.append(high) #将转化成整型的数值依次附加到列表末尾
27
28 print(highs) #打印是不是符合预期
29
30 #绘制最高气温图表
31 fig = plt.figure(dpi=128,figsize=(16,9)) #定义图表输出样式
32 plt.plot(highs,c='red') #绘制最高气温并且把颜色设置成红色
33
34 plt.title("Daily High Temperatures of Sitka in July 2014",fontsize=14) #图形标题
35 plt.xlabel(" ",fontsize=10) #图形x轴标签
36 plt.ylabel("Temperatures (F) ",fontsize=10) #图形y轴标签
37 plt.tick_params(axis='both',which='major',labelsize=5) #刻度参数
38
39 plt.show() #显示图形
没有出错的话,效果图应该如下。应该注意的一点是,代码中,如果没把从每一行索引值为1的字符串转化成整型数据类型,matplotlib也能画图,但是绘制出来的图形不是预期的。
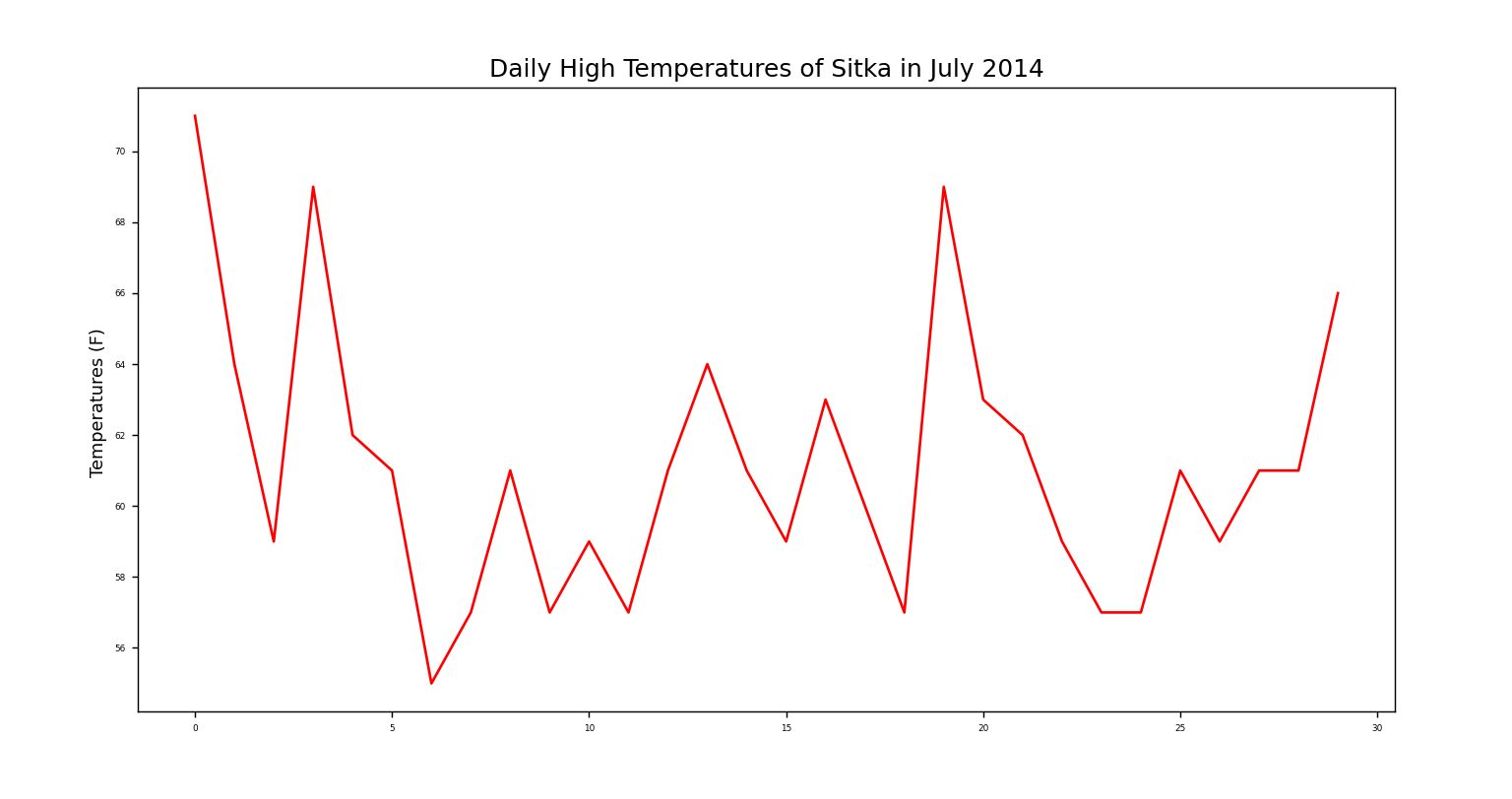
---------------------------------------------------------------------------------我是分割线---------------------------------------------------------------------------------
上面的图形只绘制了一个简单的表示最高气温的折线图,下面来添加时间还有最低气温还有涵盖更长时间(sitka_weather_2014.csv,即一整年的数值)以便比较:
1 #!usr/bin/env python
2 # *-* Coding=utf-8 *-*
3
4 import csv #导入csv模块
5 from matplotlib import pyplot as plt #导入模块以便绘图
6 from datetime import datetime #导入模块处理日期格式
7
8 filename = 'sitka_weather_2014.csv' #要处理的文件名
9 with open(filename) as file_object: #打开文件并将结果文件对象存储在file_object中
10 reader = csv.reader(file_object) #调用csv.reader()将文件对象file_object作为实参传递给阅读器reader
11 header_row = next(reader) #调用一次next,得到文件的第一行
12 row_2 = next(reader) #再调用一次next,得到文件第二行
13 print(header_row,row_2) #打印一下是不是符合预期
14
15 #文件头的格式并非总是一致,空格和单位可能总是出现在奇怪的地方。这在原始数据文件中很常见,但不会带来任何问题
16 for index, column_header in enumerate(header_row): #调用enumerate来获取每个元素的索引及其值
17 print(index, column_header) #打印索引还有对应的值
18
19 highs = [] #创建空列表以存储最高气温
20 dates =[] #创建空列表以存储日期
21 lows = [] #创建空列表以存储最低气温
22 for row in reader: #循环读取文件对象的每一行
23 high = int(row[1]) #把每一行索引为1的值即最高气温(字符串)转换成整型
24 date = datetime.strptime(row[0],"%Y-%m-%d") #利用datetime模块处理日期格式
25 low = int(row[3]) #把每一行索引为3的值即最低气温(字符串)转换成整型
26
27 highs.append(high) #将转换好的整型数值通过循环依次附加到列表末尾形成最高气温列表highs
28 dates.append(date) #将做好格式的日期通过循环依次福建到列表末尾以形成日期列表dates
29 lows.append(low) #将转换好的整型数值通过循环依次福建到列表末尾形成最低气温列表lows
30
31 print(highs,dates,lows) #打印一下是不是符合预期
32 #开始绘制图表
33 fig = plt.figure(dpi=128,figsize=(16,9)) #定义图表输出的dpi数值和输出格式
34 plt.plot(dates,highs,c='red',alpha=0.5) #绘制最高气温数据系列,并把线条设置为红色,不透明度设置为0.5
35 plt.plot(dates,lows,c='blue',alpha=0.5) #绘制最低气温数据系列,并把线条设置为蓝色,不透明度设置为0.5
36 plt.title("High and Low temperature of Sitka in 2014",fontsize=10) #图形标题
37 plt.xlabel(' ',fontsize=8) #x轴标签,绘制空标签,因为日期会出现在x轴标签位置
38 plt.ylabel("Temperatures (F) ",fontsize=8) #y轴标签
39 plt.tick_params(axis='both',labelsize=8) #刻度参数
40 fig.autofmt_xdate() #绘制斜体日期标签,以免日期标签太长而彼此重叠
41 #方法fill_between()接收一个x值系列和两个y值系列,并填充两个y值系列的空间
42 plt.fill_between(dates,highs,lows,color='green',alpha=0.1) #dates是x值系列,两个y值系列分别是highs和lows,颜色设置为绿色,不透明度设置为0.1
43 plt.show() #显示图形
44
没有出错的话,效果图应该如下。通过着色,让两个数据集之间的区域显而易见。
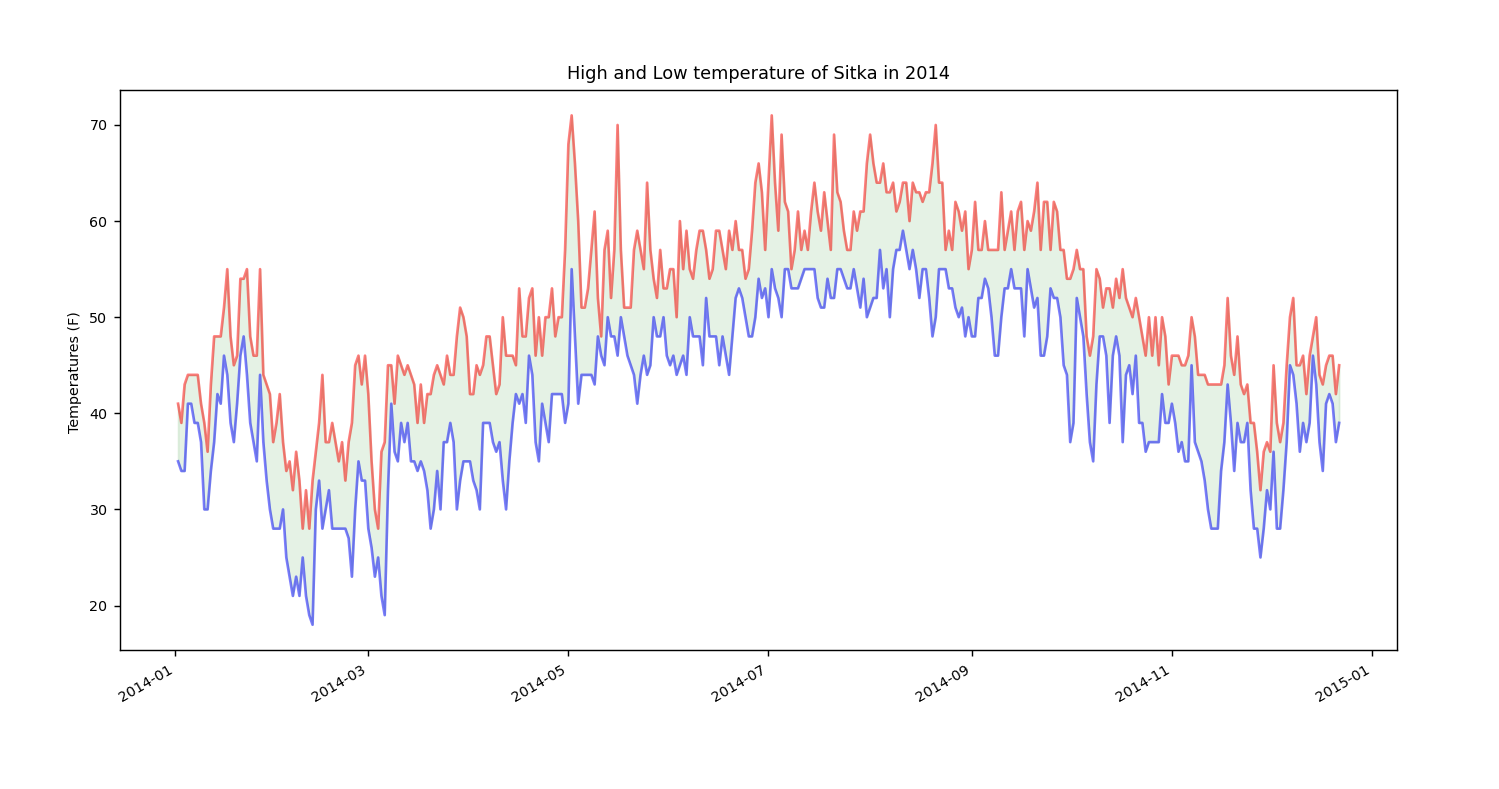
---------------------------------------------------------------------------------我是分割线---------------------------------------------------------------------------------
最后一个内容是错误检查。上面的代码,应该能处理来自世界各地任何地方的天气数据(可能会出现参数要改的情况),假定有的气象站出现了故障(或者服务器故障,或者工作人员粗心),未能收集部分或者全部应该收集的数据。缺失数据缺失可能会引发程序异常。下面把文件改成另一个文件,有数据缺失的情况。运行出现如下错误:
Traceback (most recent call last):
File "practice.py", line 23, in <module>
high = int(row[1]) #把每一行索引为1的值即最高气温(字符串)转换成整型
ValueError: invalid literal for int() with base 10: ''
这个错误表明,python无法将空字符串' '转换成整型。通过打印print(row),发现:
['2014-2-16', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '0.00', '', '', '-1']
2014年2月16日的一整行数据大部分都是空的,特别是需要的最高气温和最低气温。现在来改下代码以适应这种情况:
1 #!usr/bin/env python
2 # *-* Coding=utf-8 *-*
3
4 import csv #导入csv以处理csv文件
5 from matplotlib import pyplot as plt #从matplotlib导入pyplot以处理图形
6 from datetime import datetime #导入datetime以处理日期
7
8 filename = 'death_valley_2014.csv' #要处理的文件
9 with open(filename) as file_object: #打开文件并将结果文件对象存储在file_object中
10 reader = csv.reader(file_object) #调用csv.reader()将文件对象file_object作为实参传递给reader
11 header_row = next(reader) #调用next,读取文件的第一行
12 print(header_row) #打印是否符合预期
13
14 for index, column_header in enumerate(header_row): #调用enumerate()获取每个元素的索引和值
15 print(index,column_header) #打印索引还有对应的值
16 #文件头的格式并非总是一致,空格和单位可能总是出现在奇怪的地方。这在原始数据中非常常见,但不会带来任何问题。
17 #为让文件头更容易理解,将列表中的每个头文件及其位置打印出来
18 highs = [] #创建空列表以存储最高气温
19 dates = [] #创建空列表以存储日期
20 lows = [] #创建空列表以存储最低气温
21
22 for row in reader: #循环读取文件对象的每一行
23 #开始错误检查和处理,对于文件对象的每一行,都尝试从中提取日期,最高气温和最低气温,尝试失败就会引发ValueError异常
24 try:
25 high = int(row[1])
26 date = datetime.strptime(row[0],"%Y-%m-%d")
27 low = int(row[3])
28 except ValueError: #处理ValueError异常
29 #pass #直接pass,忽略
30 print(date,"data missing") #打印出缺失的数据日期和提示语
31 else:
32 highs.append(high) #将没有引发ValueError异常并且提取到的数值附加到列表highs末尾形成列表highs
33 dates.append(date) #将没有引发ValueError异常并且提取到的数值附加到列表dates末尾形成列表dates
34 lows.append(low) #将没有引发ValueError异常并且提取到的数值附加到列表lows末尾形成列表lows
35
36 fig = plt.figure(dpi=128,figsize=(16,9)) #定义图表输出的dpi数值和输出格式
37 plt.plot(dates,highs,c='red',alpha=0.5) #绘制最高气温数据系列,并把线条设置为红色,不透明度设置为0.5
38 plt.plot(dates,lows,c='blue',alpha=0.5) #绘制最低气温数据系列,并把线条设置为蓝色,不透明度设置为0.5
39 plt.title("High and Low Temperature (F) of Death Valley in 2014",fontsize=10) #图形标题
40 plt.xlabel(' ',fontsize=8) #x轴标签,绘制空标签,因为日期会出现在x轴标签位置
41 plt.ylabel('Temperature (F)',fontsize=8) #y轴标签
42 plt.tick_params(axis='both',which='major',labelsize=5) #刻度参数
43 fig.autofmt_xdate() #绘制斜体日期标签,以免日期标签太长而彼此重叠
44 #方法fill_between()接收一个x值系列和两个y值系列,并填充两个y值系列的空间
45 plt.fill_between(dates,highs,lows,color='green',alpha=0.1) #dates是x值系列,两个y值系列分别是highs和lows,颜色设置为绿色,不透明度设置为0.1
46 plt.show() #显示图形
没有出错的话,效果图应该如下。
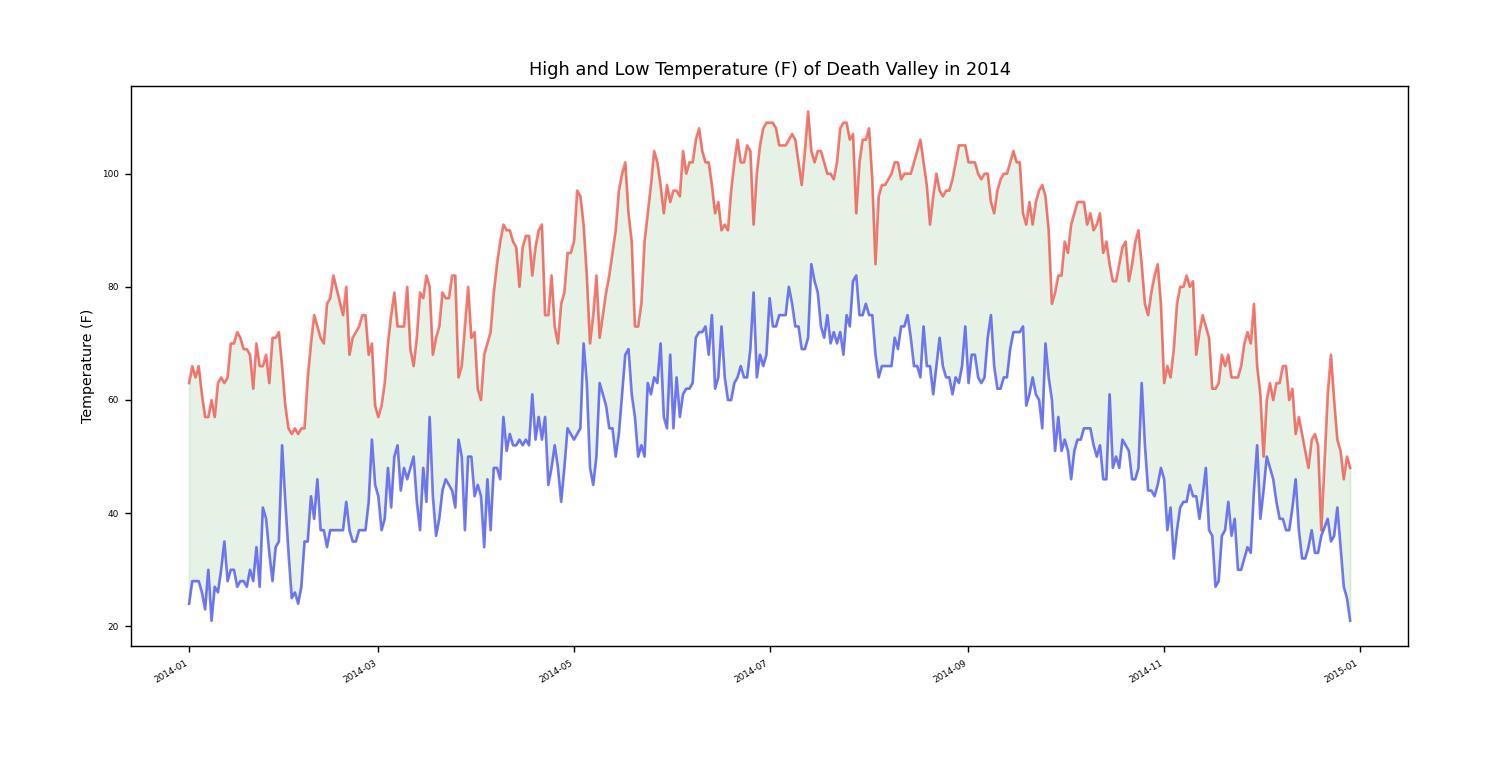
打完收工,数据参考:<python编程,从入门班到实践>。
Matplotlib处理csv文件的更多相关文章
- matplotlib读取csv文件
一,从本地加载csv文件 from matplotlib import pyplot as pltimport numpy as npimport csv#用来正常显示中文标签plt.rcParams ...
- 深度学习原理与框架-递归神经网络-时间序列预测(代码) 1.csv.reader(进行csv文件的读取) 2.X.tolist(将数据转换为列表类型)
1. csv.reader(csvfile) # 进行csv文件的读取操作 参数说明:csvfile表示已经有with oepn 打开的文件 2. X.tolist() 将数据转换为列表类型 参数说明 ...
- pandas 读csv文件 TypeError: Empty 'DataFrame': no numeric data to plot
简单的代码,利用pandas模块读csv数据文件,这里有两种方式,一种是被新版本pandas遗弃的Series.from_csv:另一种就是pandas.read_csv 先说一下问题这个问题就是在读 ...
- python3使用csv包,读写csv文件
python操作csv,现在很多都用pandas包了,不过python还是有一个原始的包可以直接操作csv,或者excel的,下面举个例子说明csv读写csv文件的方法: import os impo ...
- Python开发【模块】:CSV文件 数据可视化
CSV模块 1.CSV文件格式 要在文本文件中存储数据,最简单的方式是讲数据作为一系列逗号分隔的值(CSV)写入文件,这样的文件成为CSV文件,如下: AKDT,Max TemperatureF,Me ...
- [Python Study Notes]pd.read_csv()函数读取csv文件绘图
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''' ...
- python-pandas读取mongodb、读取csv文件
续上一篇博客(‘’selenium爬取NBA并将数据存储到MongoDB‘)https://www.cnblogs.com/lutt/p/10810581.html 本篇的内容是将存储到mongo的数 ...
- python读取csv文件数据绘制图像,例子绘制天气每天最高最低气温气象图
- 2. 假设当前文件夹中data.csv文件中存放了2020年某饭店营业额,第一列为日期(如2020-02-03),第二列为每天交易额(如3560),文件中第一行为表头,其余行为实 际数据。
假设当前文件夹中data.csv文件中存放了2020年某饭店营业额,第一列为日期(如2020-02-03),第二列为每天交易额(如3560),文件中第一行为表头,其余行为实 际数据.编写程序,完成下 ...
随机推荐
- java数组作为函数返回值
1 //将一个二维数组行和列元素互换.存到另一个二维数组 2 package test; 3 4 public class test1_8 { 5 public static int[][] huhu ...
- Docker实战 | 第一篇:Centos8 安装 Docker
1. 安装依赖包 yum install -y yum-utils device-mapper-persistent-data lvm2 2. 配置镜像源 yum config-manager --a ...
- guava中的SettableFuture分析
当缓存中没有要找的数据时,则要从数据库中去查询,而当并发量比较大时可能会击穿数据库,所以guava cache对同一值的查询做了合并请求的处理.其中就用到了SettableFuture,类似一把锁,只 ...
- AndroidStudio新导入项目,无法编译,rebuild、clean都无效
此按钮,可以用gradle重新编译
- IdentityServer4系列 | 快速搭建简易项目
一 .前言 从上一篇关于 常见术语说明中,主要是对IdentityServer4的说明,以及其中涉及常见的术语的表述说明,包括对身份认证服务器.用户.客户端.资源以及各个令牌等进行对比区别说明. 而在 ...
- Mybatis学习-配置、作用域和生命周期
核心配置文件:Mybatis-config.xml Mybatis的配置文件包含了会深深影响Mybatis行为的设置和属性信息 配置(configuration) 在mybatis-config.xm ...
- java并发编程实战《三》互斥锁(上)
互斥锁(上):解决原子性问题 原子性问题的源头是线程切换,操作系统做线程切换是依赖 CPU 中断的,所以禁止 CPU 发生中断就能够禁止线程切换. 在早期单核 CPU 时代,这个方案的确是可行的,而且 ...
- moviepy音视频剪辑:使用fl_time进行时间特效处理报错ValueError: Attribute duration not set
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt+moviepy音视频剪辑实战 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 在使 ...
- 在Python实现print标准输出sys.stdout、stderr重定向及捕获的简单办法
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 Python中的标准输出和错误输出由sys模块的stdout.stde ...
- 第15.12节PyQt(Python+Qt)入门学习:可视化设计界面组件布局详解
一.引言 在Qt Designer中,在左边部件栏的提供了界面布局相关部件,如图: 可以看到共包含有四种布局部件,分别是垂直布局(Vertical Layout).水平布局(Horizontal La ...