数据采集与融合第四次作业:多线程以及scrapy框架的使用
数据采集第四次作业:多线程以及scrapy框架的使用
任务一:单多线程的使用
单线程代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def imageSpider(start_url):
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err:
print(err)
except Exception as err: print(err)
def download(url):
global count
try:
count = count + 1
# 提取文件后缀扩展名
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("images\\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101280601.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count=0
imageSpider(start_url)
运行结果:可以观察到爬取到的图片是一张一张迭代出现的
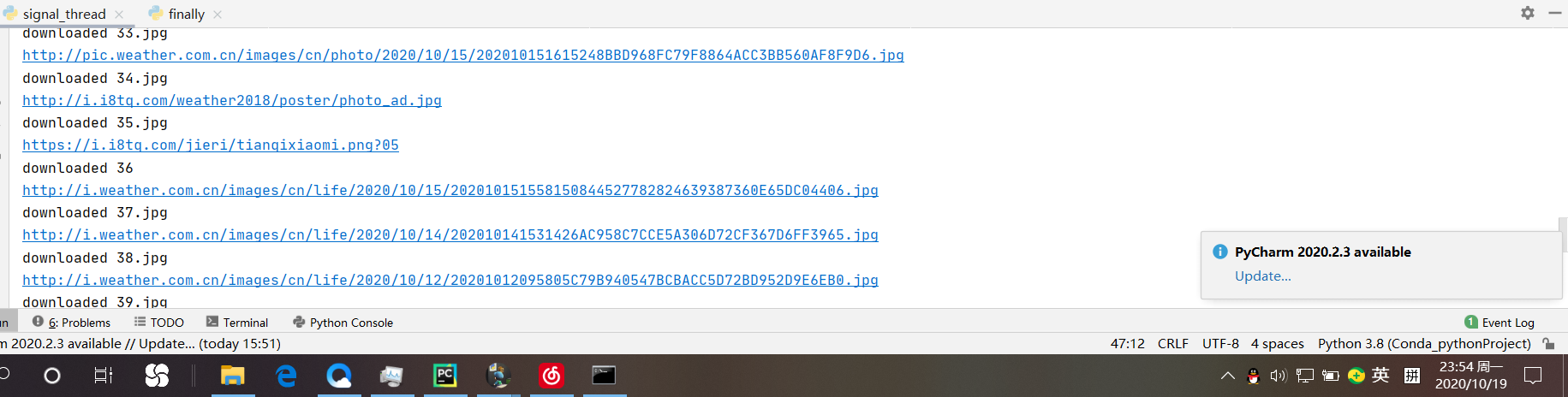
多线程代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def imageSpider(start_url):
global threads
global count
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
print(url)
count = count + 1
T = threading.Thread(target=download, args=(url, count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err: print(err)
def download(url,count):
try:
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("images\\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101280601.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}
count=0
threads=[]
imageSpider(start_url)
for t in threads:
t.join()
print("The End")
运行结果:可以观察到是“唰”一大串出现的结果,特别舒服,无需等待。

小结:多线程之所以比单线程效率要高出许多,是因为线程的划分尺度小于进程,使得多线程程序的并发性高。进程在执行过程之中拥有独立的内存单元,而多个线程共享内存,从而极大的提升了程序的运行效率。线程比进程具有更高的性能,这是由于同一个进程中的线程都有共性,多个线程共享一个进程的虚拟空间。线程的共享环境包括进程代码段、进程的共有数据等,利用这些共享的数据,线程之间很容易实现通信。操作系统在创建进程时,必须为改进程分配独立的内存空间,并分配大量的相关资源,但创建线程则简单得多。因此,使用多线程来实现并发比使用多进程的性能高得
PS:知识的融会贯通体现出来了,操作系统的内容
任务二:使用scrapy复现任务一
主要步骤:
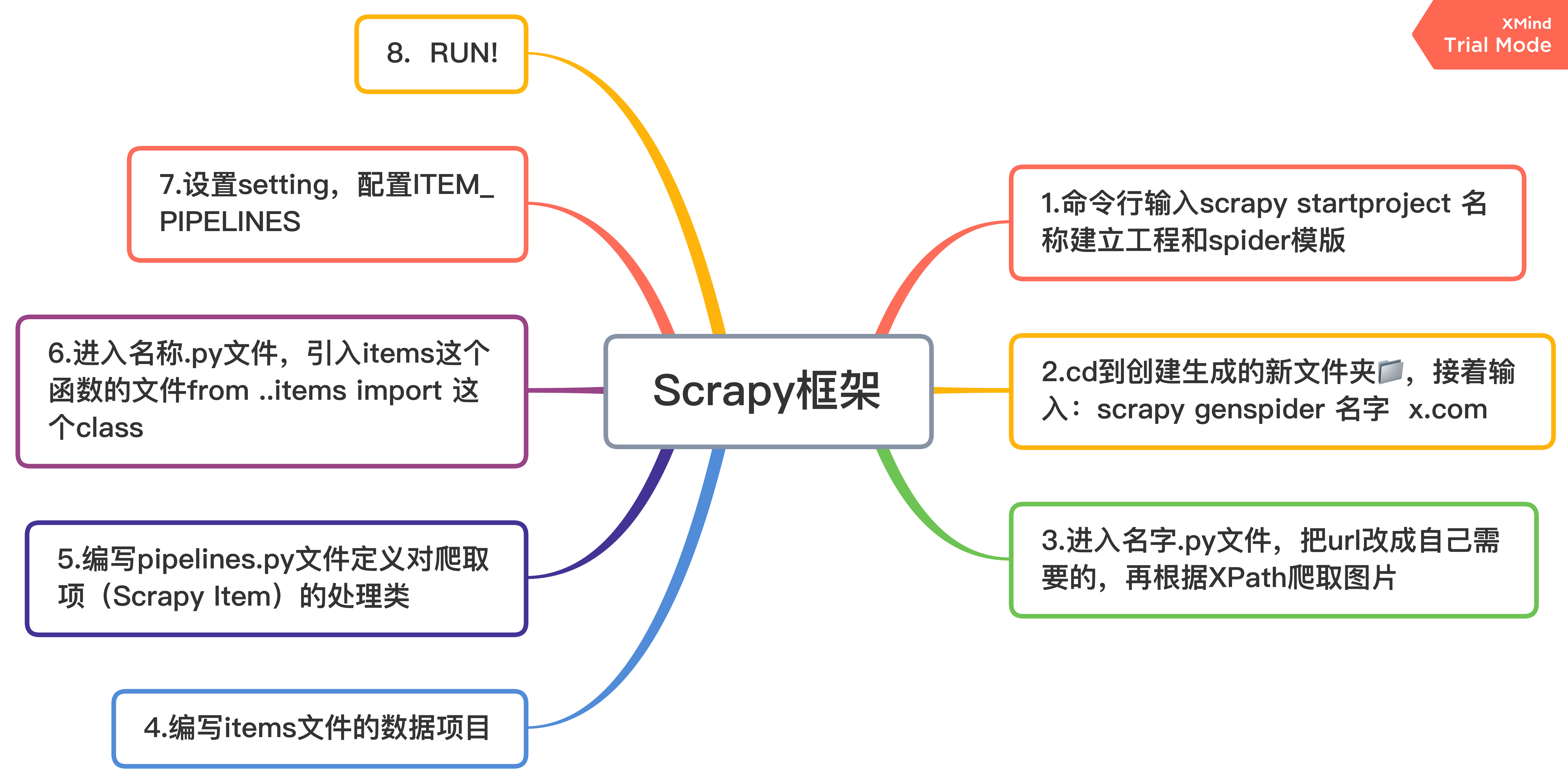
代码展示:
主spider:jpgdownload.py(不止下载jpg,也可以png)
import scrapy
from ..items import JpgItem
class JpgdownloadSpider(scrapy.Spider):
name = 'jpgdownload'#给爬虫命名
# allowed_domains = ['baidu.com']
start_urls = ['http://www.weather.com.cn']
def parse(self, response):
try:
srcs = response.xpath('//img/@src')
# os.mkdir("D:/Conda_pythonProject/code_of_Data_Acquisition/Scrapy_pycharm/images")
imgs_src = srcs.extract() # 返回一个图片src的list
for src in imgs_src:
item = JpgItem()
print(src) # 输出下载的Url信息
item["url"] = src
# item["name"] = name
# print(name)
yield item
except Exception as err:
print(err)
items:
import scrapy
class JpgItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
url = scrapy.Field()
pass
pipelines:
import urllib
import urllib.request
from .settings import IMAGES_STORE
import os
class JpgPipeline:
count = 0
def process_item(self, item, spider):
if (item["url"][len(item["url"]) - 4] == "."):
ext = item["url"][len(item["url"]) - 4:]
else:
ext = ""
JpgPipeline.count += 1
save_path = IMAGES_STORE
os.chdir(save_path)
urllib.request.urlretrieve(url=item["url"], filename="NO"+str(JpgPipeline.count)+ext)
return item
setting:
ITEM_PIPELINES = {
'jpg.pipelines.JpgPipeline': 300,
# 'scrapy.pipelines.images.ImagesPipeline':1,#scrapy内置管道
}
IMAGES_STORE=r'D:\Conda_pythonProject\code_of_Data_Acquisition\Scrapy_pycharm\images' #图片保存地址
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl jpgdownload -s LOG_ENABLED=false".split())
结果展示:
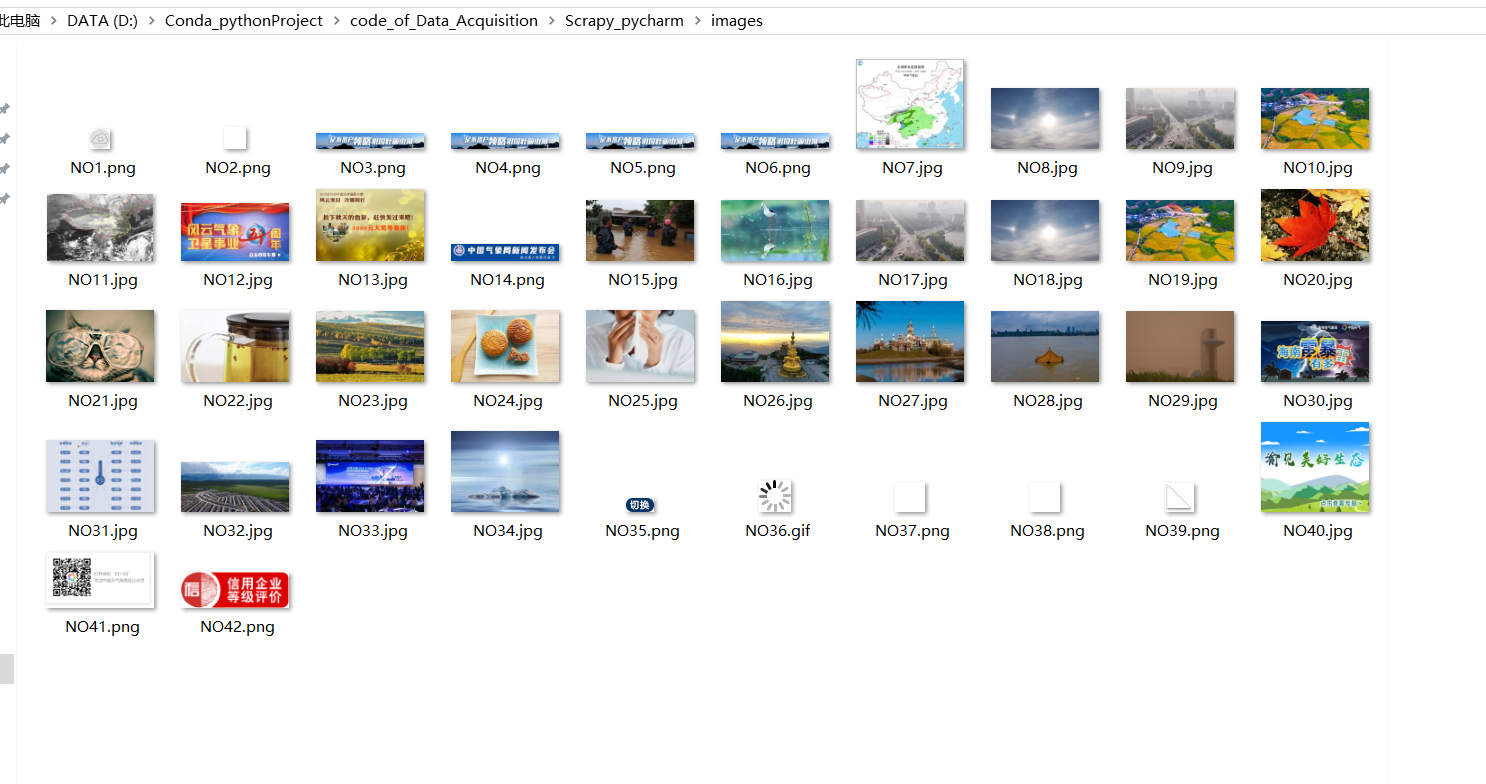
小结:个人感觉XPath很香,scrapy用不来,对各个模块之间的关系还要进一步加深理解。通过本次实验我也了解到在scrapy中不需要传统的import os来写文件,使用setting的内置通道并在piprlines中调用即可
IMAGES_STORE=r'D:\Conda_pythonProject\code_of_Data_Acquisition\Scrapy_pycharm\images' #图片保存地址
from .settings import IMAGES_STORE #在pipelines中
任务三:使用scrapy框架爬取股票信息
搞到大半夜了也不能再scrapy中复现上一次制定xls显示爬取结果的代码,有些自闭了,直接贴控制台输出的代码和结果。
stock.py
import scrapy
import re
import urllib.request
from bs4 import UnicodeDammit
from bs4 import BeautifulSoup
from ..items import EaststockItem
class StockSpider(scrapy.Spider):
name = 'stock'
# allowed_domains = ['baidu.com']
start_urls = ['http://quote.eastmoney.com/stock_list.html']
def parse(self, response):
url = "http://22.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406286903286457721_1602799759543&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80&fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18&_=1602799759869"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400"}
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, 'html.parser')
data = re.findall(r'"diff":\[(.*?)]', soup.text)
datas = data[0].strip("{").strip("}").split('},{') # 去掉头尾的"{"和"}",再通过"},{"切片
for i in range(len(datas)):
item = EaststockItem()
item["data"] = datas[i].replace('"', "").split(",") # 去掉双引号并通过","切片
yield item
pipelines:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class EaststockPipeline:
number = 0
print(
"序号" + '\t' + "代码" + '\t' + "名称" + '\t' + "最新价" + '\t' + "涨跌幅" + '\t' + "跌涨额" + '\t' + "成交量" + '\t' + "成交额" + '\t' + "振幅" + '\t' + "最高" + '\t' + "最低" + '\t' + "今开" + '\t' + "昨收")
def process_item(self, item, spider):
EaststockPipeline.number += 1
try:
stock = item["data"]
print(
str(EaststockPipeline.number) + '\t' + stock[6][4:] + '\t' + stock[7][4:] + '\t' + stock[0][3:] + '\t' +
stock[1][3:] + '\t' + stock[2][3:] + '\t' + stock[3][3:] + '\t' + stock[4][3:] + '\t' + stock[5][
3:] + '\t' +
stock[8][4:] + '\t' + stock[9][4:] + '\t' + stock[10][4:] + '\t' + stock[11][4:])
except:
pass
return item
setting:
ITEM_PIPELINES = {
'eaststock.pipelines.EaststockPipeline': 300,
}
items:
import scrapy
class EaststockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
data = scrapy.Field()
# Number = scrapy.Field()
# Name = scrapy.Field()
# Newest_price = scrapy.Field()
# updownExtent = scrapy.Field()
# updownValue = scrapy.Field()
# Money_number = scrapy.Field()
# Money = scrapy.Field()
# Up_number = scrapy.Field()
pass
输出图片:
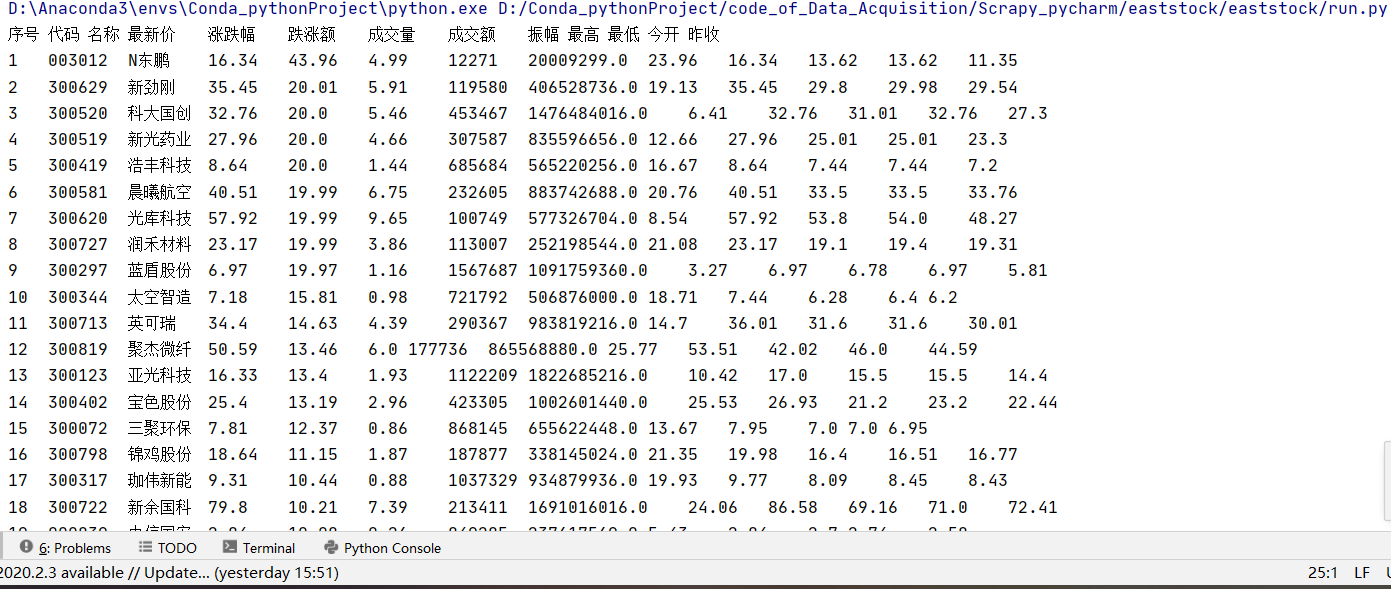
小结:或许是软工作业做完接着就写爬虫的原因,没能在scrapy中实现表格输出,等有精力了再请教同学试试。
总结:scrapy令初学者的我感到并不是很舒服,要编写5个地方似乎有点麻烦。它更多的是针对大规模爬取,scrapy框架将程序员从繁冗的流程式重复劳动中解放出来,简单的网页爬虫的重点,就集中在应对反爬,大规模爬取和高效稳定的爬取这几个方面。就像是一堆骨架需要注入血肉和灵魂它才能行走起来,编写好scrapy的各个结构才能让爬虫运行。
数据采集与融合第四次作业:多线程以及scrapy框架的使用的更多相关文章
- 网络爬虫第三次作业——多线程、scrapy框架
作业①: 1)单/多线程爬取网站图片实验 要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网http://www.weather.com.cn.分别使用单线程和多线程的方式爬取. ...
- 十四 web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
打码接口文件 # -*- coding: cp936 -*- import sys import os from ctypes import * # 下载接口放目录 http://www.yundam ...
- Python多线程爬图&Scrapy框架爬图
一.背景 对于日常Python爬虫由于效率问题,本次测试使用多线程和Scrapy框架来实现抓取斗图啦表情.由于IO操作不使用CPU,对于IO密集(磁盘IO/网络IO/人机交互IO)型适合用多线程,对于 ...
- 【OO学习】OO第四单元作业总结及OO课程总结
[OO学习]OO第四单元作业总结及OO课程总结 第四单元作业架构设计 第十三次作业 第十四次作业 总结 这两次作业架构思路上是一样的. 通过将需要使用的UmlElement,封装成Element的子类 ...
- BUAA OO 2019 第四单元作业总结
目录 第四单元总结 总 UML UML 类图 UML 时序图 UML 状态图 架构设计 第十三次作业 第十四次作业 课程总结 历次作业总结 架构设计 面向对象方法理解 测试方法理解与实践 改进建议 尽 ...
- oo第四单元作业总结暨课程总结
oo第四单元作业总结暨课程总结 一.本单元作业架构设计 本单元需要构建一个UML解析器,通过对输入的UML类图/顺序图/状态图的相关信息进行解析以供查询,其中课程组已提供输入整体架构及输入解析部分,仅 ...
- OO第四单元作业总结以及课程总结
第四单元总结--UML 第四单元作业架构分析 第一次作业其实是本单元三次作业中最难的一次.由于第一次是第一次作业,要考虑到搭建框架和设计架构,这次作业的思维性很强.在了解了各个类型元素(Element ...
- 2019OO第四单元作业总结&OO课程整体总结
第四单元作业总结 第四单元的作业主题是UML图的解析,通过对UML图代码的解析,我对UML图的结构以及各种元素之间的关系的理解更加深入了. ------------------------------ ...
- 耿丹CS16-2班第四次作业汇总
Deadline: 2016-10-13 12:00 作业内容 实验3-1 分别使用while循环.do while循环.for循环求1+2+3+ --+100. 实验3-2 分别使用while循环. ...
随机推荐
- linux块设备驱动---程序设计(转)
块设备驱动注册与注销 块设备驱动中的第1个工作通常是注册它们自己到内核,完成这个任务的函数是 register_blkdev(),其原型为:int register_blkdev(unsigned i ...
- 【手摸手,带你搭建前后端分离商城系统】01 搭建基本代码框架、生成一个基本API
[手摸手,带你搭建前后端分离商城系统]01 搭建基本代码框架.生成一个基本API 通过本教程的学习,将带你从零搭建一个商城系统. 当然,这个商城涵盖了很多流行的知识点和技术核心 我可以学习到什么? S ...
- 技术心得丨一种有效攻击BERT等模型的方法
Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Enta ...
- centos8安装RabbitMQ
一.安装erlang # 添加仓库 curl -s https://packagecloud.io/install/repositories/rabbitmq/erlang/script.rpm.sh ...
- docker19.03搭建私有容器仓库
一,启动docker后,搜索registry [root@localhost source]# systemctl start docker [root@localhost source]# dock ...
- 缩略图调查——抖音客户端/PC/iphone
最近对抖音有点上瘾,经常看到这样的视频列表: 由于抖音平台的限制,用户最多只能上传60s的视频,因此分段为3个视频.而在视频列表的缩略图模式下,三个视频的封面恰好组合成一张图像.这种方式比较符合审美标 ...
- svn右键菜单不显
问题1: 32位svn客户端安装到64位win7机器上,出现svn右键菜单不显. 网上有些说,,选择Mufwin7,关键下拉列表没有这项. 后来有人推荐64位系统安装64svn;32位系统安装32sv ...
- sangforEDR 任意命令执行
EDR 使用范围 由于只有POC 没有详细细节.暂时不知道具体细节. 部分EDR 已经完成升级,不存在该漏洞. POC https://XXX:8081/tool/log/c.php?strip_sl ...
- Java nio Client端简单示例
java nio是一种基于Channel.Selector.Buffer的技术,它是一种非阻塞的IO实现方式 以下Client端示例 public class ClientNio { public s ...
- JavaScript实现基于对象的栈
class Stack { constructor() { this.count = 0; this.items = {}; } push(element) { this.items[this.cou ...