你知道MySQL是如何处理千万级数据的吗?
mysql 分表思路
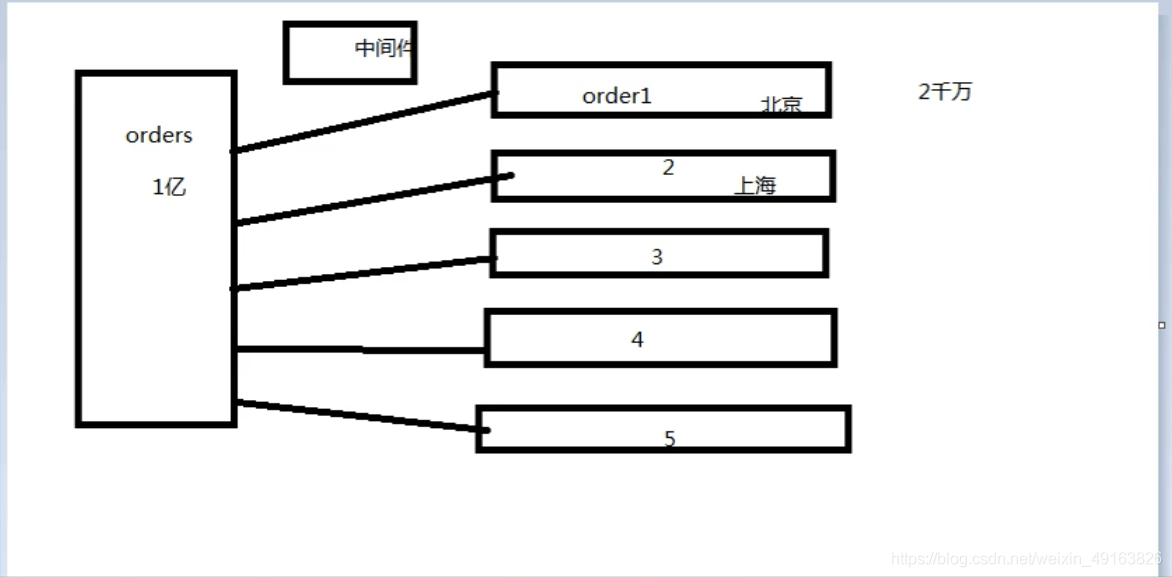
一张一亿的订单表,可以分成五张表,这样每张表就只有两千万数据,分担了原来一张表的压力,分表需要根据某个条件进行分,这里可以根据地区来分表,需要一个中间件来控制到底是去哪张表去找到自己想要的数据。
中间件:根据主表的自增 id 作为中间件(什么样的字段适合做中间件?要具备唯一性)
怎么分发?主表插入之后返回一个 id,根据这个 id 和表的数量进行取模,余数是几就往哪张表中插入数据。
注意:子表中的 id 要与主表的 id 保持一致
以后只有插入操作会用到主表,修改,删除,读取,均不需要用到主表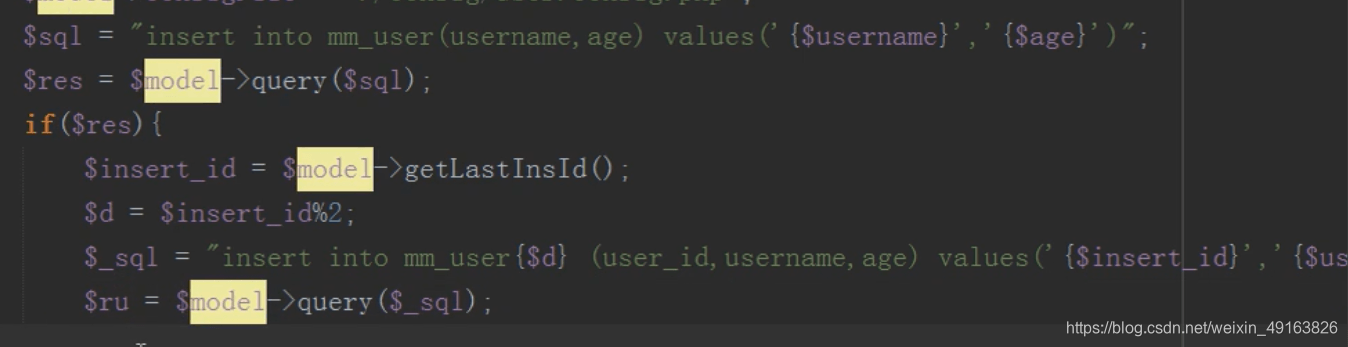
redis 消息队列
- 什么是消息队列?
答:消息传播过程中保存消息的容器 - 消息队列产生的历史原因
答:主要原因是由于在高并发环境下,由于来不及同步处理,请求往往会发生堵塞,比如说,大量的insert,update之类的请求同时到达MySQL,直接导致无数的行锁表锁,甚至最后请求会堆积过多,从而触发并发错误。通过使用消息队列,我们可以异步处理请求,从而缓解系统的压力。
消息队列的特点: 先进先出
把要执行的 sql 语句先保存在消息队列中,然后依次按照顺利异步插入的数据库中
应用: 新浪,把瞬间的评论先放入消息队列,然后通过定时任务把消息队列里面的 sql 语句依次插入到数据库中
修改
操作子表进行修改
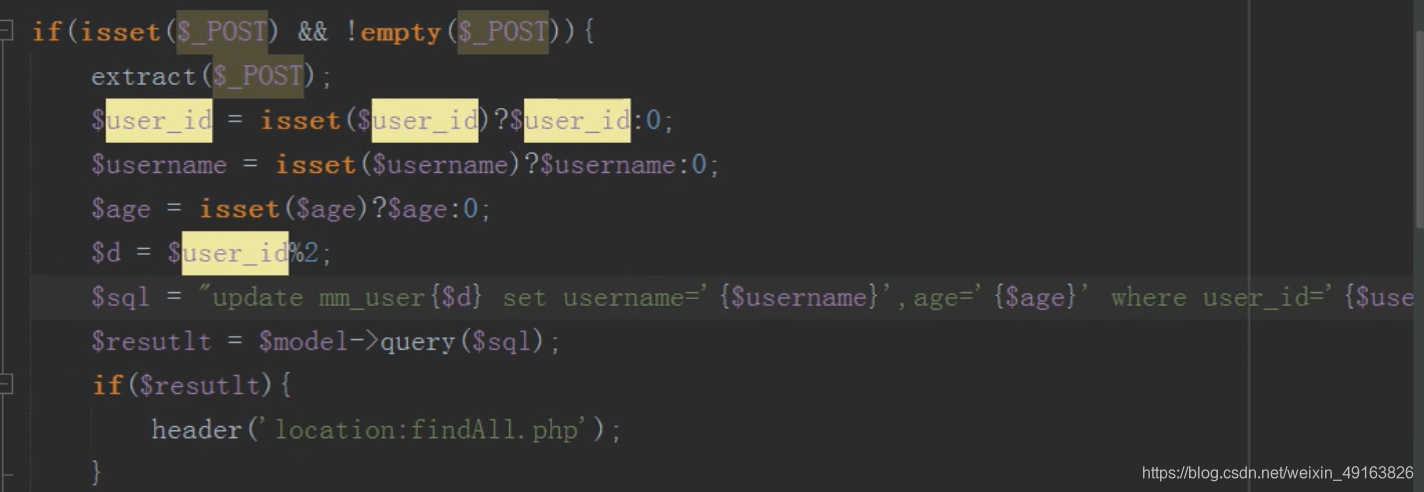
这样修改有一个问题,主表和子表的数据会出现不一致,如何让主表和字表数据一致?
redis 队列保持主表子表数据一致
修改完成后将要修改主表的数据,存入 redis 队列中
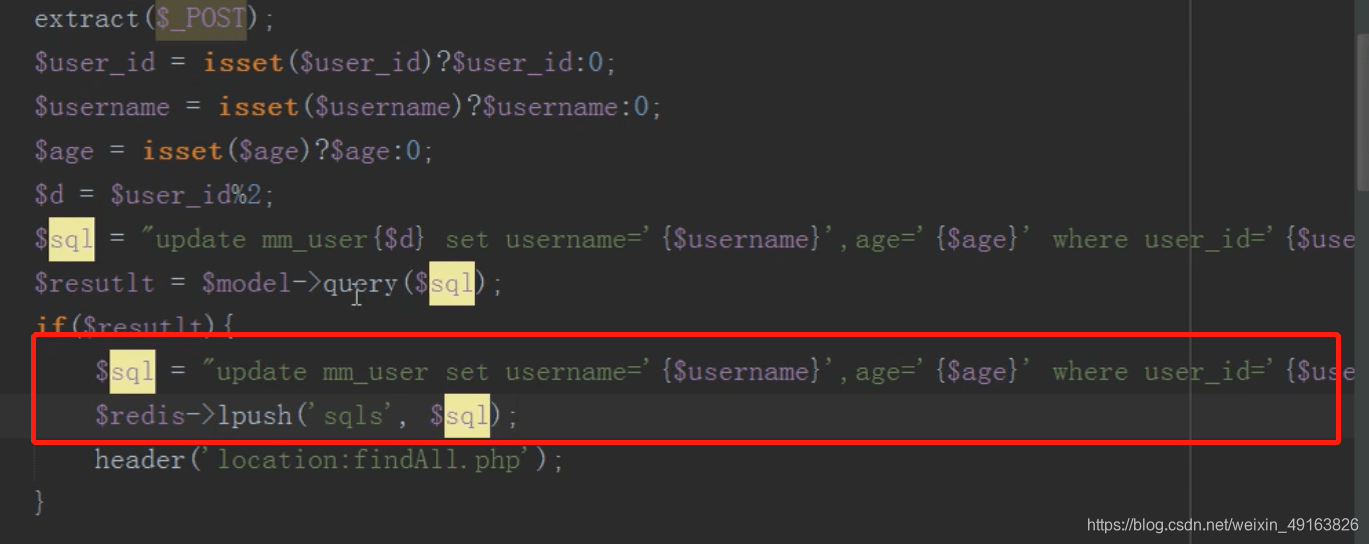
然后 linux 定时任务(contble)循环执行 redis 队列中的 sql 语句,同步更新主表的内容
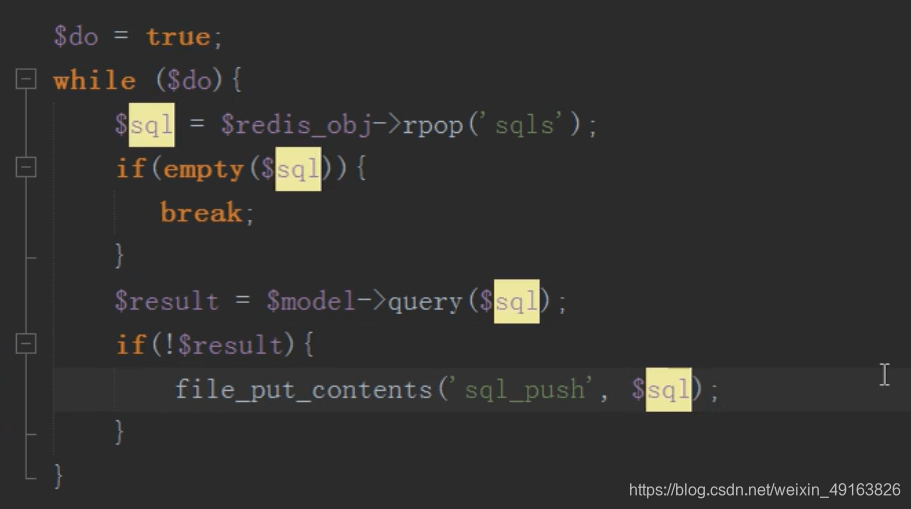
mysql 分布式之分表(查,删)
查询只需要查询子表,不要查询总表

删除,先根据 id 找到要删除的子表,然后删除,然后往消息队列中压入一条删除总表数据的 sql 语句
然后执行定时任务删除总表数据
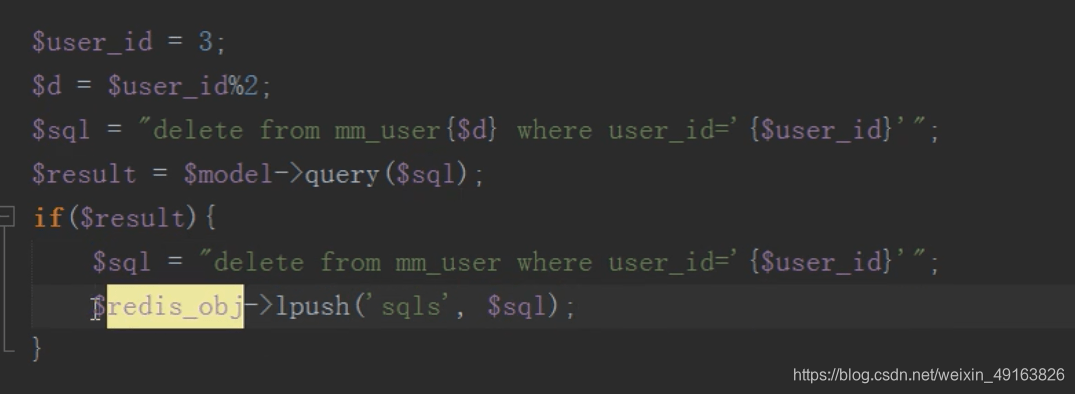
定时任务:
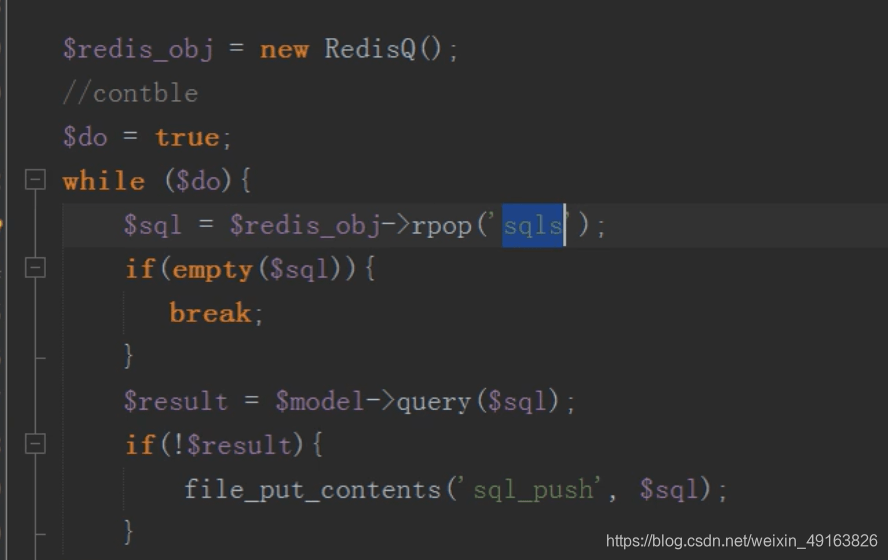
mysql 分布式之分库
分库思路
- 单库单表
单库单表是最常见的数据库设计,例如,有一张用户(user)表房子啊数据库db中,所有的用户都是可以在db库中的user表中查到。 - 单库多表
随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能。可以通过某种方式将user进行水平的切分,产生两个表结构完全一样的user_0000,user-0001等表,user_0000 + user-0001 + …的数据刚好是一份完整的数据。 - 多库多表
随着数据量增加也许单台DB的存储空间不够,随着查询量的增加单台数据库服务器已经没办法支撑。这个时候可以再对数据库进行水平区分。
分库原理图:
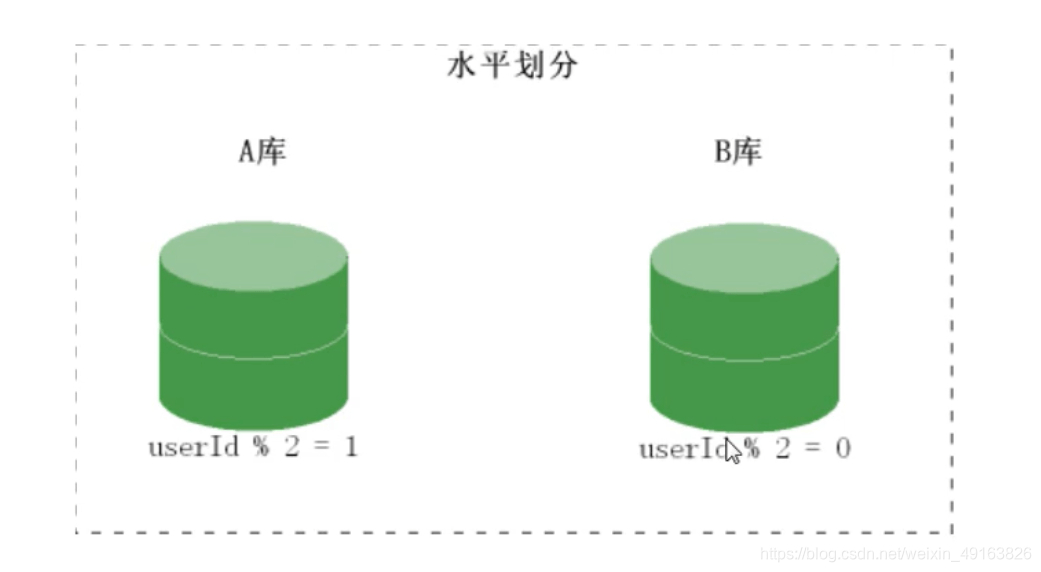
mysql 分布式之分库(增)
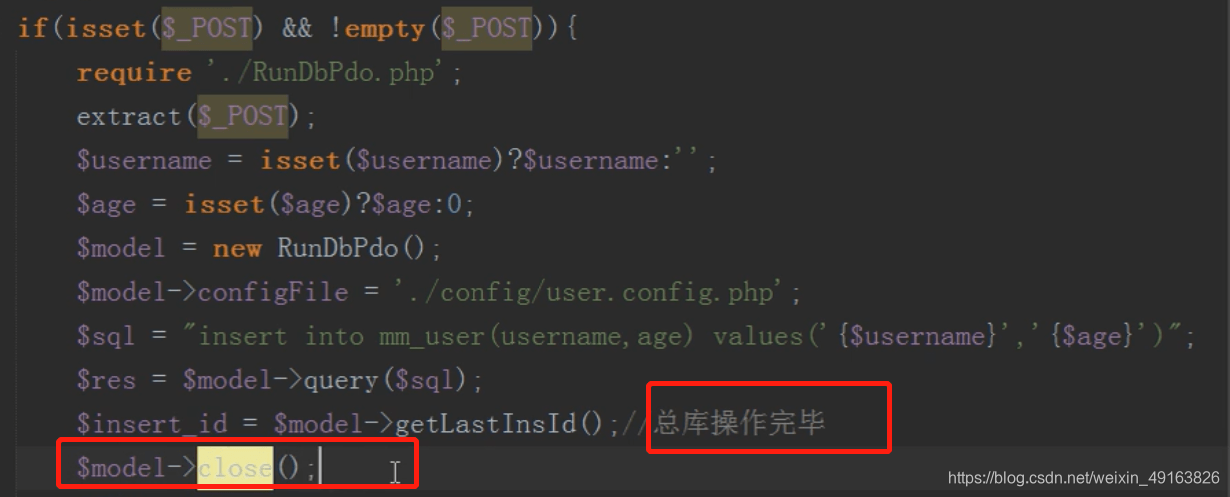
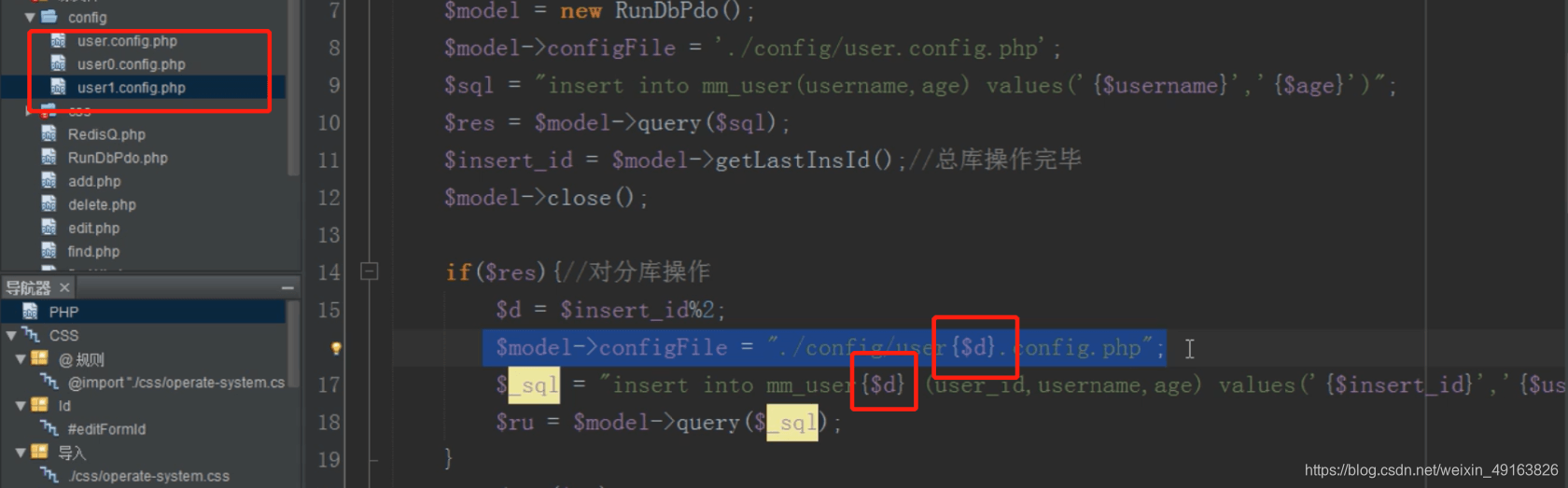
注意:操作完一个数据库一定要把数据库连接关闭,不然 mysql 会以为一直连接的同一个数据库
还是取模确定加载哪个配置文件连接哪个数据库
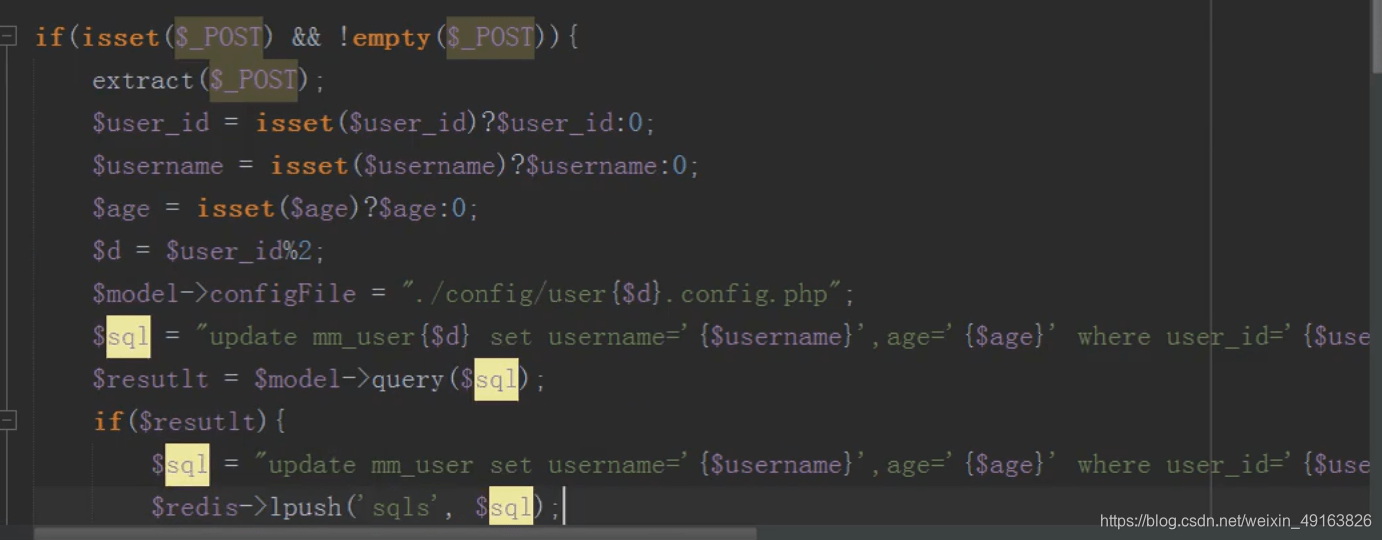
mysql 分布式之分库(改)
原理同新增
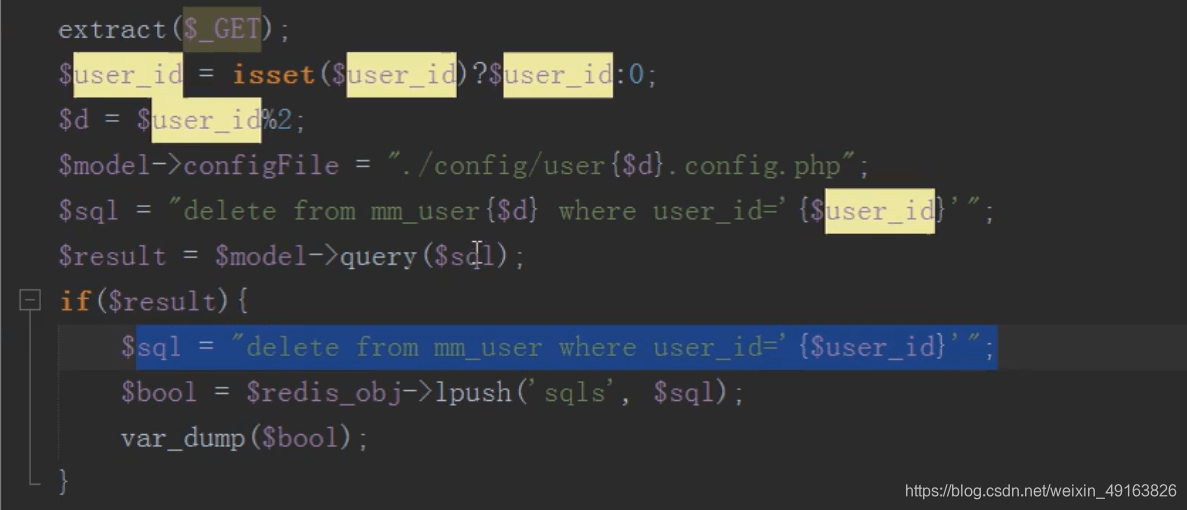
mysql 分布式之分库(查,删)
原理类似

删除
执行队列
mysql 分布式之缓存(memcache)的应用
将数据放入缓存中,节省数据库开销,先去缓存中查,如果有直接取出,如果没有,去数据库查,然后存入缓存中
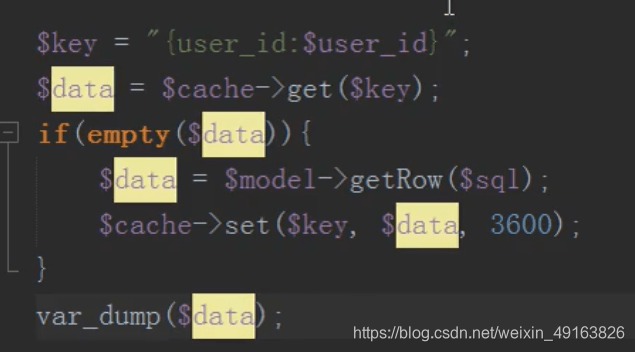
在编辑信息之后需要删除缓存,不然一直读取的是缓存的数据而不是修改过的数据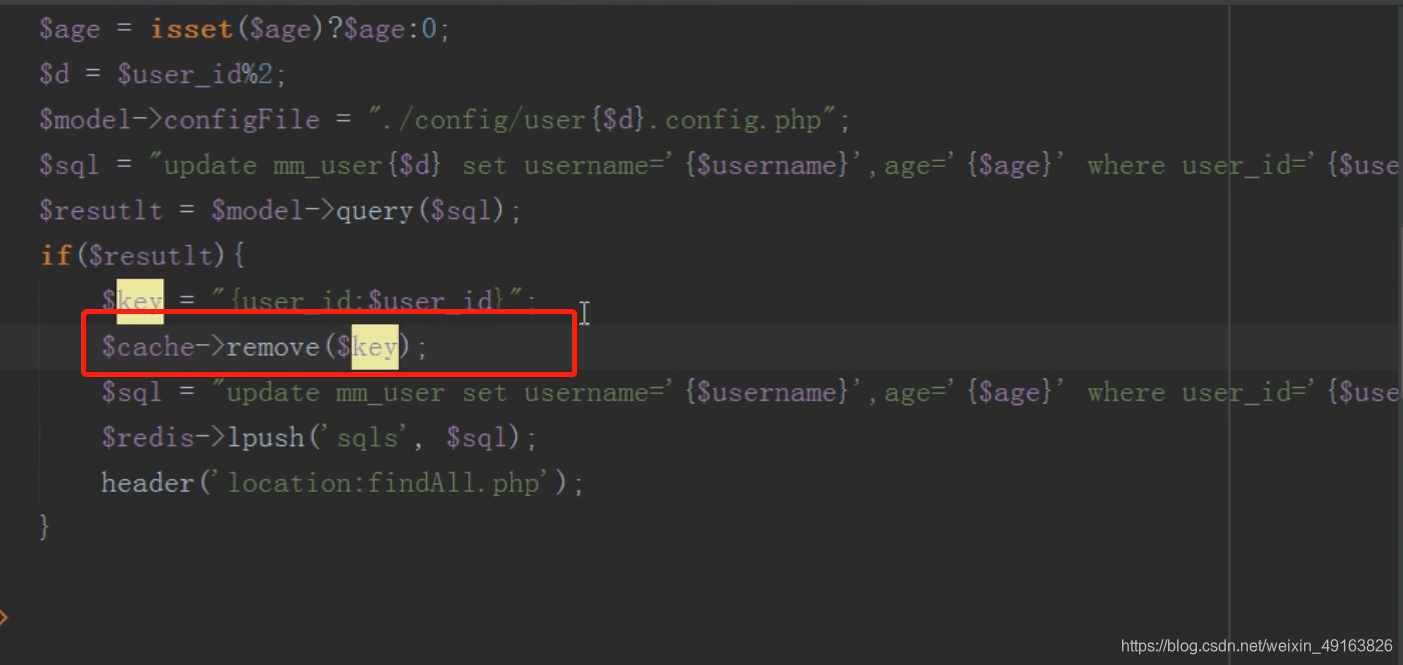
还有更多进阶学习资料在这噢进阶PHP月薪30k>>>架构师成长路线【视频、面试文档免费获取】
你知道MySQL是如何处理千万级数据的吗?的更多相关文章
- 转载:mysql 对于百万 千万级数据的分表实现方法
一般来说,当我们的数据库的数据超过了100w记录的时候就应该考虑分表或者分区了,这次我来详细说说分表的一些方法.目前我所知道的方法都是MYISAM的,INNODB如何做分表并且保留事务和外键,我还不是 ...
- MySQL千万级数据分区存储及查询优化
作为传统的关系型数据库,MySQL因其体积小.速度快.总体拥有成本低受到中小企业的热捧,但是对于大数据量(百万级以上)的操作显得有些力不从心,这里我结合之前开发的一个web系统来介绍一下MySQL数据 ...
- mysql千万级数据量查询出所有重复的记录
查询重复的字段需要创建索引,多个条件则创建组合索引,各个条件的索引都存在则不必须创建组合索引 有些情况直接使用GROUP BY HAVING则能直接解决:但是有些情况下查询缓慢,则需要使用下面其他的方 ...
- MySQL百万级、千万级数据多表关联SQL语句调优
本文不涉及复杂的底层数据结构,通过explain解释SQL,并根据可能出现的情况,来做具体的优化,使百万级.千万级数据表关联查询第一页结果能在2秒内完成(真实业务告警系统优化结果).希望读者能够理解S ...
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案
如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案
- Mysql千万级数据删除实操-企业案例
某天,在生产环节中,发现一个定时任务表,由于每次服务区查询这个表就会造成慢查询,给mysql服务器带来不少压力,经过分析,该表中绝对部分数据是垃圾数据 需要删除,约1050万行,由于缺乏处理大数据的额 ...
- (转载)MYSQL千万级数据量的优化方法积累
转载自:http://blog.sina.com.cn/s/blog_85ead02a0101csci.html MYSQL千万级数据量的优化方法积累 1.分库分表 很明显,一个主表(也就是很重要的表 ...
- 转载自lanceyan: 一致性hash和solr千万级数据分布式搜索引擎中的应用
一致性hash和solr千万级数据分布式搜索引擎中的应用 互联网创业中大部分人都是草根创业,这个时候没有强劲的服务器,也没有钱去买很昂贵的海量数据库.在这样严峻的条件下,一批又一批的创业者从创业中获得 ...
- 完全用nosql轻松打造千万级数据量的微博系统(转)
原文:http://www.cnblogs.com/imxiu/p/3505213.html 其实微博是一个结构相对简单,但数据量却是很庞大的一种产品.标题所说的是千万级数据量 也并不是一千万条微博信 ...
随机推荐
- C# 接口与抽象类的区别? 情景下使用接口,什么情景下使用抽象类?
接口与抽象类的区别: 接口支持多继承:抽象类不能实现多继承. 接口可以用于支持回调:抽象类不能实现回调,因为继承不支持. 接口只包含方法.属性.索引器.事件的签名,但不能定义字段和包含实现的方法:抽象 ...
- 为什么阿里、头条、美团这些互联网大厂都在用Spring Boot?
前言 自 2014 年发布至今,Spring Boot 的搜索指数 一路飙升.没错 Spring Boot 越来越火了,作为一名行走一线的 Java 程序员,你可能在各个方面感受到了 Spring B ...
- Java常用API(ArrayList类)
Java常用API(ArrayList类) 我们为什么要使用ArrayList类? 为了更加方便的储存对象,因为使用普通的数组来存储对象太过麻烦了,因为数组的一个很大的弱点就是长度从一开始就固定了,所 ...
- Ethical Hacking - GAINING ACCESS(1)
Gaining Access Introduction Everything is a computer Two main approaches (1)Server Side Do not requi ...
- RabbitMQ 入门之基础概念
什么是消息队列(MQ) 消息是在不同应用间传递的数据.这里的消息可以非常简单,比如只包含字符串,也可以非常复杂,包含多个嵌套的对象.消息队列(Message Queue)简单来说就是一种应用程序间的通 ...
- go test 测试用例那些事(二) mock
关于go的单元测试,之前有写过一篇帖子go test测试用例那些事,但是没有说go官方的库mock,很有必要单独说一下这个库,和他的实现原理. mock主要的功能是对接口的模拟,需要在写代码的时候定义 ...
- 题解 洛谷 P4143 【采集矿石】
对于一个固定的左端点,右端点向右移动时,其子串权值和不断增大,字典序降序排名不断减小,因此对于一个左端点,最多存在一个右端点使其满足条件. 所以可以枚举左端点,然后二分右端点的位置,权值和通过前缀和来 ...
- 题解 CF786B 【Legacy】
本题要求我们支持三种操作: ① 点向点连边. ② 点向区间连边. ③ 区间向点连边. 然后跑最短路得出答案. 考虑使用线段树优化建图. 建两颗线段树,入树和出树,每个节点为一段区间的原节点集合.入树内 ...
- wpf文字模糊
wpf如果使用了DropShadowEffect,会导致文字模糊,可以在window上设置 this.UseLayoutRounding = true;解决此问题
- jenkins集群(三) -- master和slave配置git
一.Linux(master)上安装git 1.运行命令:yum -y install git 2.git的默认安装目录是: 二.给Linux下Git配置好秘钥(公钥 + 私钥) 1.添加用户和密码 ...