Pytorch训练时显存分配过程探究
对于显存不充足的炼丹研究者来说,弄清楚Pytorch显存的分配机制是很有必要的。下面直接通过实验来推出Pytorch显存的分配过程。
实验实验代码如下:
import torch
from torch import cuda x = torch.zeros([3,1024,1024,256],requires_grad=True,device='cuda')
print("1", cuda.memory_allocated()/1024**2)
y = 5 * x
print("2", cuda.memory_allocated()/1024**2)
torch.mean(y).backward()
print("3", cuda.memory_allocated()/1024**2)
print(cuda.memory_summary())
输出如下:

代码首先分配3GB的显存创建变量x,然后计算y,再用y进行反向传播。可以看到,创建x后与计算y后分别占显存3GB与6GB,这是合理的。另外,后面通过backward(),计算出x.grad,占存与x一致,所以最终一共占有显存9GB,这也是合理的。但是,输出显示了显存的峰值为12GB,这多出的3GB是怎么来的呢?首先画出计算图:

下面通过列表的形式来模拟Pytorch在运算时分配显存的过程:
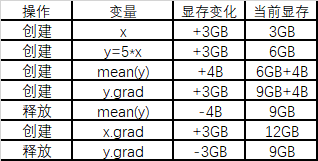
如上所示,由于需要保存反向传播以前所有前向传播的中间变量,所以有了12GB的峰值占存。
我们可以不存储计算图中的非叶子结点,达到节省显存的目的,即可以把上面的代码中的y=5*x与mean(y)写成一步:
import torch
from torch import cuda x = torch.zeros([3,1024,1024,256],requires_grad=True,device='cuda')
print("1", cuda.memory_allocated()/1024**2)
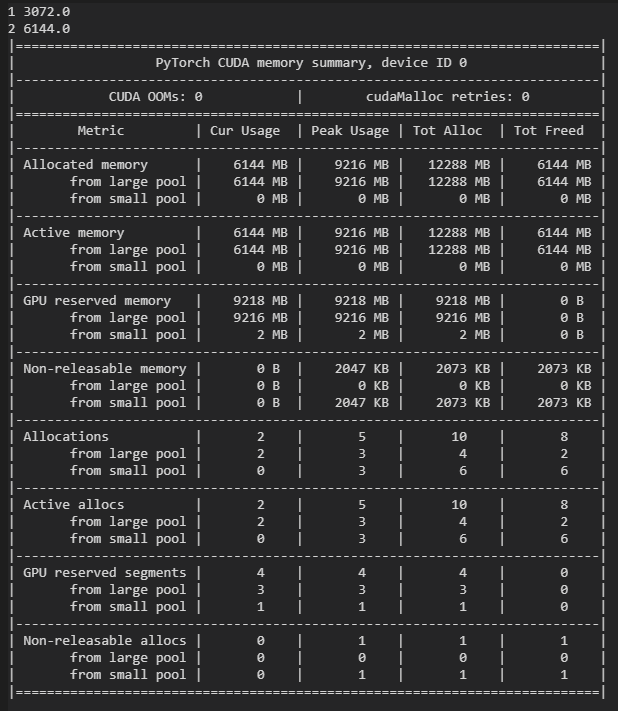
torch.mean(5*x).backward()
print("2", cuda.memory_allocated()/1024**2)
print(cuda.memory_summary())
占显存量减少了3GB:
Pytorch训练时显存分配过程探究的更多相关文章
- [Pytorch]深度模型的显存计算以及优化
原文链接:https://oldpan.me/archives/how-to-calculate-gpu-memory 前言 亲,显存炸了,你的显卡快冒烟了! torch.FatalError: cu ...
- OpenGL8-直接分配显存-极速绘制(Opengl1.5版本才有)
视频教程请关注 http://edu.csdn.net/lecturer/lecturer_detail?lecturer_id=440 /** * 这个例子介绍如何使用显卡内存进行绘制 下载地址 : ...
- TensorFlow中的显存管理器——BFC Allocator
背景 作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 使用GPU训练时,一次训练任务无论是模型参数还是中间结果都需要占用大量显存.为了 ...
- 【原创】Linux环境下的图形系统和AMD R600显卡编程(4)——AMD显卡显存管理机制
显卡使用的内存分为两部分,一部分是显卡自带的显存称为VRAM内存,另外一部分是系统主存称为GTT内存(graphics translation table和后面的GART含义相同,都是指显卡的页表,G ...
- Tensorflow与Keras自适应使用显存
Tensorflow支持基于cuda内核与cudnn的GPU加速,Keras出现较晚,为Tensorflow的高层框架,由于Keras使用的方便性与很好的延展性,之后更是作为Tensorflow的官方 ...
- 关于python中显存回收的问题
技术背景 笔者在执行一个Jax的任务中,又发现了一个奇怪的问题,就是明明只分配了很小的矩阵空间,但是在多次的任务执行之后,显存突然就爆了.而且此时已经按照Jax的官方说明配置了XLA_PYTHON_C ...
- (原)tensorflow中函数执行完毕,显存不自动释放
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/7608916.html 参考网址: https://stackoverflow.com/question ...
- Pytorch显存动态分配规律探索
下面通过实验来探索Pytorch分配显存的方式. 实验 显存到主存 我使用VSCode的jupyter来进行实验,首先只导入pytorch,代码如下: import torch 打开任务管理器查看主存 ...
- pytorch训练GAN时的detach()
我最近在学使用Pytorch写GAN代码,发现有些代码在训练部分细节有略微不同,其中有的人用到了detach()函数截断梯度流,有的人没用detch(),取而代之的是在损失函数在反向传播过程中将bac ...
随机推荐
- quic 分析 1
问题1:quic握手过程是怎样的? 怎样节约握手时间?握手时间多少个RTT?握手过程成涉及到哪些概念以及变量(代码) 0~1 RTT握手过程 QUIC握手的过程是需要一次数据交互,0-RTT时延即 ...
- nginx&http 第三章 ngx http ngx_http_process_request_headers
HTTP 请求行正确处理完成后,针对 HTTP/1.0 及以上版本紧接着要做的就是请求 HEADER 的处理与解析了 /** * 用于处理http的header数据 * 请求头: * Host: lo ...
- 信号-linux
https://www.linuxjournal.com/article/3985 每个信号在 signal.h 头文件中通过宏进行定义,实际是在 signal.h 中定义,对于编号以及信号名的映射关 ...
- delete和truncate/drop恢复数据的过程
使用myflash工具恢复delete操作数据,myflash工具注意事项: 该工具注意事项 1.binlog格式必须为row,且binlog_row_image=full 2.仅支持5.6与5.7 ...
- Gin的中间件和路由分组
什么是分组 对router创建Group(就是分组), 对同一分组会拥有同一前缀和同一中间件 写法 eg: r := gin.Default() v1 := r.Group("/v1&quo ...
- CSS属性(背景属性)
1.背景属性 <!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset=" ...
- 关于点击弹框外部区域弹框关闭的交互处理(前端JS)
常见需求场景 前端在处理交互的时候,经常遇到这样的场景,点击一个按钮,出现一个弹框,点击外部区域,弹框关闭. 解决方法 思路说明: 1.给弹框的div父级都加个类名,如: 2.在document绑定一 ...
- 汇编语言CPU状态控制指令
CPU状态控制指令 1.空操作指令NOP /该指令不执行任何操作,只是使IP加1,其机器码占有一个字节的存储单元,常用于程序调试./ 2.总线封锁前缀指令LOCK /该指令与其他指令联合使用,作为指令 ...
- VScode,code::blocksC语言编译运行出现不支持的16位应用程序解决方法
最近,莫名其妙c代码就是编译运行不了,老是提示不支持的16位应用程序 然后网上找了各种教程 只有这个成功了(害得我还升了下系统) 实现进入Windows设置 然后点更新和安全--恢复 然后点高级启动- ...
- 精尽MyBatis源码分析 - MyBatis初始化(二)之加载Mapper接口与XML映射文件
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...