Pytorch显存动态分配规律探索
下面通过实验来探索Pytorch分配显存的方式。
实验
显存到主存
我使用VSCode的jupyter来进行实验,首先只导入pytorch,代码如下:
import torch
打开任务管理器查看主存与显存情况。情况分别如下:


在显存中创建1GB的张量,赋值给a,代码如下:
a = torch.zeros([256,1024,1024],device= 'cpu')
查看主存与显存情况:


可以看到主存与显存都变大了,而且显存不止变大了1G,多出来的内存是pytorch运行所需的一些配置变量,我们这里忽略。
再次在显存中创建一个1GB的张量,赋值给b,代码如下:
b = torch.zeros([256,1024,1024],device= 'cpu')
查看主显存情况:

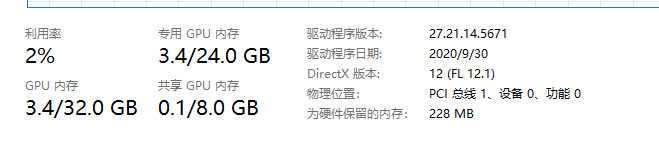
这次主存大小没变,显存变高了1GB,这是合情合理的。然后我们将b移动到主存中,代码如下:
b = b.to('cpu')
查看主显存情况:


发现主存是变高了1GB,显存却只变小了0.1GB,好像只是将显存张量复制到主存一样。实际上,pytorch的确是复制了一份张量到主存中,但它也对显存中这个张量的移动进行了记录。我们接着执行以下代码,再创建1GB的张量赋值给c:
c = torch.zeros([256,1024,1024],device= 'cuda')
查看主显存情况:

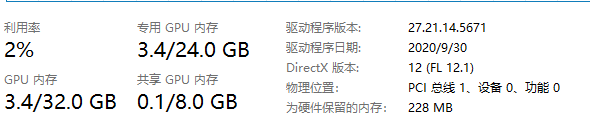
发现只有显存大小变大了0.1GB,这说明,Pytorch的确记录了显存中张量的移动,只是没有立即将显存空间释放,它选择在下一次创建新变量时覆盖这个位置。接下来,我们重复执行上面这行代码:
c = torch.zeros([256,1024,1024],device= 'cuda')
主显存情况如下:


明明我们把张量c给覆盖了,显存内容却变大了,这是为什么呢?实际上,Pytorch在执行这句代码时,是首先找到可使用的显存位置,创建这1GB的张量,然后再赋值给c。但因为在新创建这个张量时,原本的c依然占有1GB的显存,pytorch只能先调取另外1GB显存来创建这个张量,再将这个张量赋值给c。这样一来,原本的那个c所在的显存内容就空出来了,但和前面说的一样,pytorch并不会立即释放这里的显存,而等待下一次的覆盖,所以显存大小并没有减小。
我们再创建1GB的d张量,就可以验证上面的猜想,代码如下:
d = torch.zeros([256,1024,1024],device= 'cuda')
主显存情况如下:


显存大小并没有变,就是因为pytorch将新的张量创建在了上一步c空出来的位置,然后再赋值给了d。另外,删除变量操作也同样不会立即释放显存:
del d
主显存情况:


显存没有变化,同样是等待下一次的覆盖。
主存到显存
接着上面的实验,我们创建直接在主存创建1GB的张量并赋值给e,代码如下:
e = torch.zeros([256,1024,1024],device= 'cpu')
主显存情况如下:


主存变大1GB,合情合理。然后将e移动到显存,代码如下:
e = e.to('cuda')
主显存情况如下:


主存变小1GB,显存没变是因为上面张量d被删除没有被覆盖,合情合理。说明主存的释放是立即执行的。
总结
通过上面的实验,我们了解到,pytorch不会立即释放显存中失效变量的内存,它会以覆盖的方式利用显存中的可用空间。另外,如果要重置显存中的某个规模较大的张量,最好先将它移动到主存中,或是直接删除,再创建新值,否则就需要两倍的内存来实现这个操作,就有可能出现显存不够用的情况。
Pytorch显存动态分配规律探索的更多相关文章
- [Pytorch]深度模型的显存计算以及优化
原文链接:https://oldpan.me/archives/how-to-calculate-gpu-memory 前言 亲,显存炸了,你的显卡快冒烟了! torch.FatalError: cu ...
- Pytorch训练时显存分配过程探究
对于显存不充足的炼丹研究者来说,弄清楚Pytorch显存的分配机制是很有必要的.下面直接通过实验来推出Pytorch显存的分配过程. 实验实验代码如下: import torch from torch ...
- 显卡、显卡驱动、显存、GPU、CUDA、cuDNN
显卡 Video card,Graphics card,又叫显示接口卡,是一个硬件概念(相似的还有网卡),执行计算机到显示设备的数模信号转换任务,安装在计算机的主板上,将计算机的数字信号转换成模拟 ...
- 深度学习中GPU和显存分析
刚入门深度学习时,没有显存的概念,后来在实验中才渐渐建立了这个意识. 下面这篇文章很好的对GPU和显存总结了一番,于是我转载了过来. 作者:陈云 链接:https://zhuanlan.zhihu. ...
- Linux显存占用无进程清理方法(附批量清理命令)
在跑TensorFlow.pytorch之类的需要CUDA的程序时,强行Kill掉进程后发现显存仍然占用,这时候可以使用如下命令查看到top或者ps中看不到的进程,之后再kill掉: fuser -v ...
- 解决GPU显存未释放问题
前言 今早我想用多块GPU测试模型,于是就用了PyTorch里的torch.nn.parallel.DistributedDataParallel来支持用多块GPU的同时使用(下面简称其为Dist). ...
- MegEngine亚线性显存优化
MegEngine亚线性显存优化 MegEngine经过工程扩展和优化,发展出一套行之有效的加强版亚线性显存优化技术,既可在计算存储资源受限的条件下,轻松训练更深的模型,又可使用更大batch siz ...
- 分页型Memory LCD显存管理与emWin移植
上一篇随笔整理了一下逐行扫描型Memory LCD的显存管理与emWin移植,这篇就整理一下分页型Memory LCD显存管理与emWin移植. //此处以SSD1306作为实例 //OLED的显存/ ...
- 逐行扫描型Memory LCD显存管理与emWin移植
因为Memory LCD 的特性,不能设置像素坐标,只能用缓存整体刷新. 所以对于Memory LCD来说,emWin移植仅与打点函数有关,这里用Sharp Memory LCD(ls013b7dh0 ...
随机推荐
- docker启动镜像报错
docker启动镜像报错: docker: Error response from daemon: driver failed programming external connectivity on ...
- leaflet中如何优雅的解决百度、高德地图的偏移问题
话不多说,先上效果图 以前在做项目时,经常会听到客户说,你们这个地图是哪来的,太丑了,能不能换成百度地图--高德也行-- 大家生活中,基本上都已经习惯了使用百度地图和高德地图,而在做项目时,用这两个地 ...
- c++程序设计实践——银行系统
银行系统 本科大二程序设计实践的作业,算是一个比较简单的项目吧,主要使用的编程范式有面向对象编程 其中引入<multimap><map>头文件实现多映射输出存取记录 引入< ...
- BASH让标准输出和错误输出颜色不同
shell中运行的程序输出有标准输出(stdout)和错误输出(stderr)两种.当在终端中运行一个进程时,默认是stdout和stderr混在一起的,需要区分只能去读内容,人眼不容易快速区分. 如 ...
- spring boot:使用poi导出excel电子表格文件(spring boot 2.3.1)
一,什么是poi? 1,poi poi是用来兼容微软文档格式的java api, 它是apache的顶级项目之一, 也是我们在生产环境中导出excel时使用最多的库 2,poi官方网站: http:/ ...
- git的一些操作命令
一,如何修改一个commit的注释? root@kubuntu:/data/git/clog# git commit --amend 说明:架构森林是一个专注架构的博客,地址:https://www. ...
- git reset 与 git revert的区别?
一,git reset的功能: 该命令修改HEAD的位置,即将HEAD指向的位置改变为之前存在的某个版本, 说明: 修改后,push到远程仓库时需要使用"git push -f"提 ...
- python 微信小程序自动化
微信小程序自动化 https://www.cnblogs.com/yyoba/python27 - FautoTesthttps://www.cnblogs.com/yyoba/p/9973731.h ...
- day73:drf:drf视图相关类&路由Routers&创建虚拟环境
目录 1.APIView 2.GenericAPIView:通用视图类 3.5个视图扩展类:ListModelMixin,CreateModelMixin,RetrieveModelMixin,Upd ...
- 12天搞定Python,基础语法(上)
不知你是否见过建楼房的过程,没有的话,找个时间去瞧一瞧,看一看.看过之后,你就会明白.建楼房,只有打好地基之后,才能在砌墙,建的楼层越高,打的地基就越深. 学编程也一样,要想得心应手的应用,得先打好地 ...