Pytorch训练时显存分配过程探究
对于显存不充足的炼丹研究者来说,弄清楚Pytorch显存的分配机制是很有必要的。下面直接通过实验来推出Pytorch显存的分配过程。
实验实验代码如下:
import torch
from torch import cuda x = torch.zeros([3,1024,1024,256],requires_grad=True,device='cuda')
print("1", cuda.memory_allocated()/1024**2)
y = 5 * x
print("2", cuda.memory_allocated()/1024**2)
torch.mean(y).backward()
print("3", cuda.memory_allocated()/1024**2)
print(cuda.memory_summary())
输出如下:

代码首先分配3GB的显存创建变量x,然后计算y,再用y进行反向传播。可以看到,创建x后与计算y后分别占显存3GB与6GB,这是合理的。另外,后面通过backward(),计算出x.grad,占存与x一致,所以最终一共占有显存9GB,这也是合理的。但是,输出显示了显存的峰值为12GB,这多出的3GB是怎么来的呢?首先画出计算图:

下面通过列表的形式来模拟Pytorch在运算时分配显存的过程:
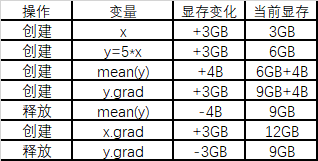
如上所示,由于需要保存反向传播以前所有前向传播的中间变量,所以有了12GB的峰值占存。
我们可以不存储计算图中的非叶子结点,达到节省显存的目的,即可以把上面的代码中的y=5*x与mean(y)写成一步:
import torch
from torch import cuda x = torch.zeros([3,1024,1024,256],requires_grad=True,device='cuda')
print("1", cuda.memory_allocated()/1024**2)
torch.mean(5*x).backward()
print("2", cuda.memory_allocated()/1024**2)
print(cuda.memory_summary())
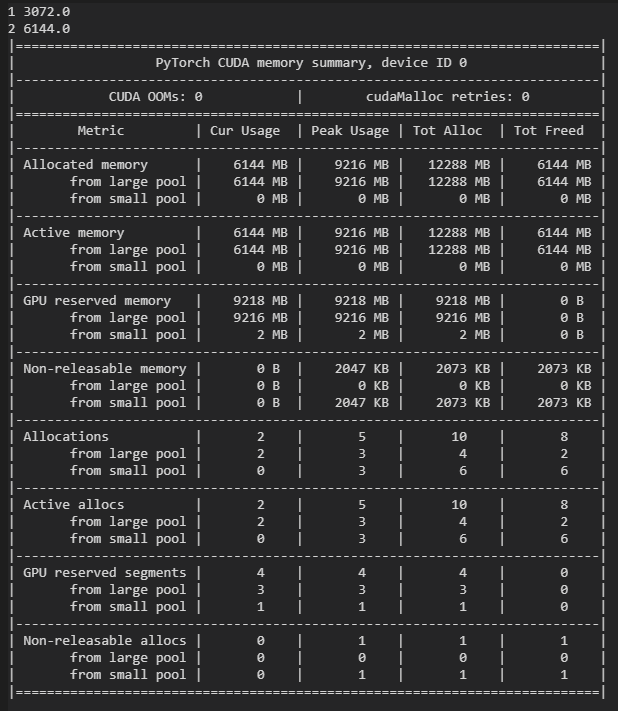
占显存量减少了3GB:
Pytorch训练时显存分配过程探究的更多相关文章
- [Pytorch]深度模型的显存计算以及优化
原文链接:https://oldpan.me/archives/how-to-calculate-gpu-memory 前言 亲,显存炸了,你的显卡快冒烟了! torch.FatalError: cu ...
- OpenGL8-直接分配显存-极速绘制(Opengl1.5版本才有)
视频教程请关注 http://edu.csdn.net/lecturer/lecturer_detail?lecturer_id=440 /** * 这个例子介绍如何使用显卡内存进行绘制 下载地址 : ...
- TensorFlow中的显存管理器——BFC Allocator
背景 作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 使用GPU训练时,一次训练任务无论是模型参数还是中间结果都需要占用大量显存.为了 ...
- 【原创】Linux环境下的图形系统和AMD R600显卡编程(4)——AMD显卡显存管理机制
显卡使用的内存分为两部分,一部分是显卡自带的显存称为VRAM内存,另外一部分是系统主存称为GTT内存(graphics translation table和后面的GART含义相同,都是指显卡的页表,G ...
- Tensorflow与Keras自适应使用显存
Tensorflow支持基于cuda内核与cudnn的GPU加速,Keras出现较晚,为Tensorflow的高层框架,由于Keras使用的方便性与很好的延展性,之后更是作为Tensorflow的官方 ...
- 关于python中显存回收的问题
技术背景 笔者在执行一个Jax的任务中,又发现了一个奇怪的问题,就是明明只分配了很小的矩阵空间,但是在多次的任务执行之后,显存突然就爆了.而且此时已经按照Jax的官方说明配置了XLA_PYTHON_C ...
- (原)tensorflow中函数执行完毕,显存不自动释放
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/7608916.html 参考网址: https://stackoverflow.com/question ...
- Pytorch显存动态分配规律探索
下面通过实验来探索Pytorch分配显存的方式. 实验 显存到主存 我使用VSCode的jupyter来进行实验,首先只导入pytorch,代码如下: import torch 打开任务管理器查看主存 ...
- pytorch训练GAN时的detach()
我最近在学使用Pytorch写GAN代码,发现有些代码在训练部分细节有略微不同,其中有的人用到了detach()函数截断梯度流,有的人没用detch(),取而代之的是在损失函数在反向传播过程中将bac ...
随机推荐
- MySQL视图详细介绍
前言: 在MySQL中,视图可能是我们最常用的数据库对象之一了.那么你知道视图和表的区别吗?你知道创建及使用视图要注意哪些点吗?可能很多人对视图只是一知半解,想详细了解视图的同学看过来哟,本篇文章会详 ...
- shell编程之条件与分支语句
1.if条件分支语句 if expr1(条件测试) #如果expr1为真,返回0 then commands1 elif expr2 then commands2 .... ... else ...
- linux常用配置文件和命令总结
常用配置文件说明: 1..设置-n永远生效:Vim的配置文件:命令模式想永久生效, ~/.vimrc,新建文件,在里面输入保存即可 2.设置别名永远生效:在~/.bashrc 修改当前用户家目录里的 ...
- Ceph Bluestore首测
Bluestore 作为 Ceph Jewel 版本推出的一个重大的更新,提供了一种之前没有的存储形式,一直以来ceph的存储方式一直是以filestore的方式存储的,也就是对象是以文件方式存储在o ...
- Python_PyQt5_打开文件并修改字体
在同文件夹下新建一个 测试文档.txt 再运行下面代码,可以实现效果 代码 1 #!Python3 2 # -*- coding:utf-8 -*- 3 4 """ 5 ...
- 《Machine Learning in Action》—— 小朋友,快来玩啊,决策树呦
<Machine Learning in Action>-- 小朋友,快来玩啊,决策树呦 在上篇文章中,<Machine Learning in Action>-- Taoye ...
- YH高校集中用电管理网上查询系统POST注入漏洞
1.burpsuite 抓包保存为1.txt POST /apartsearch.asp HTTP/1.1 Host: 2*0.86.2**.69 User-Agent: Mozilla/5.0 (W ...
- OWASP固件安全性测试指南
OWASP固件安全性测试指南 固件安全评估,英文名称 firmware security testing methodology 简称 FSTM.该指导方法主要是为了安全研究人员.软件开发人员.顾问. ...
- 思维导图iMindMap可以在哪些领域应用
生活工作中你常常会遇到许多力所不能及的事情,感到无奈.茫然,这时候你急需一个帮手来帮你打破困境,思维导图就是这样的救世主,至于它有哪些力所能及的事情就是下面小编要跟你讲的. 你是否经常遇到过这样的情况 ...
- python批量爬取猫咪图片
不多说直接上代码 首先需要安装需要的库,安装命令如下 pip install BeautifulSoup pip install requests pip install urllib pip ins ...