推荐系统实践 0x0e LS-PLM
在之前介绍的几个模型中,存在这些问题:
- LR不能捕捉非线性,只能进行一次的回归预测
- GBDT+LR虽然能够产生非线性特征组合,但是树模型不适用于超高维稀疏数据
- FM利用二阶信息来产生变量之间的相关性,但是无法适应高阶组合特征,高阶组合容易爆炸
那么,下面介绍的LS-PLM模型一定程度上缓解了这个问题。
LS-PLM
LS-PLM是阿里巴巴曾经主流的推荐模型,这一篇文章就来介绍一下LS-PLM模型的内容。LS-PLM可以看做是对LR模型的自然推广,它采用的是分而治之的策略。先对样本分片,然后样本分片中运用逻辑回归进行预估。分片的作用是为了能够让CTR模型对不同的用户群体。不同使用场景都具有针对性。先对全量样本进行聚类,然后在对每个分类实施逻辑回归。透漏一下,这里阿里巴巴使用的分片聚类的经验值是12。
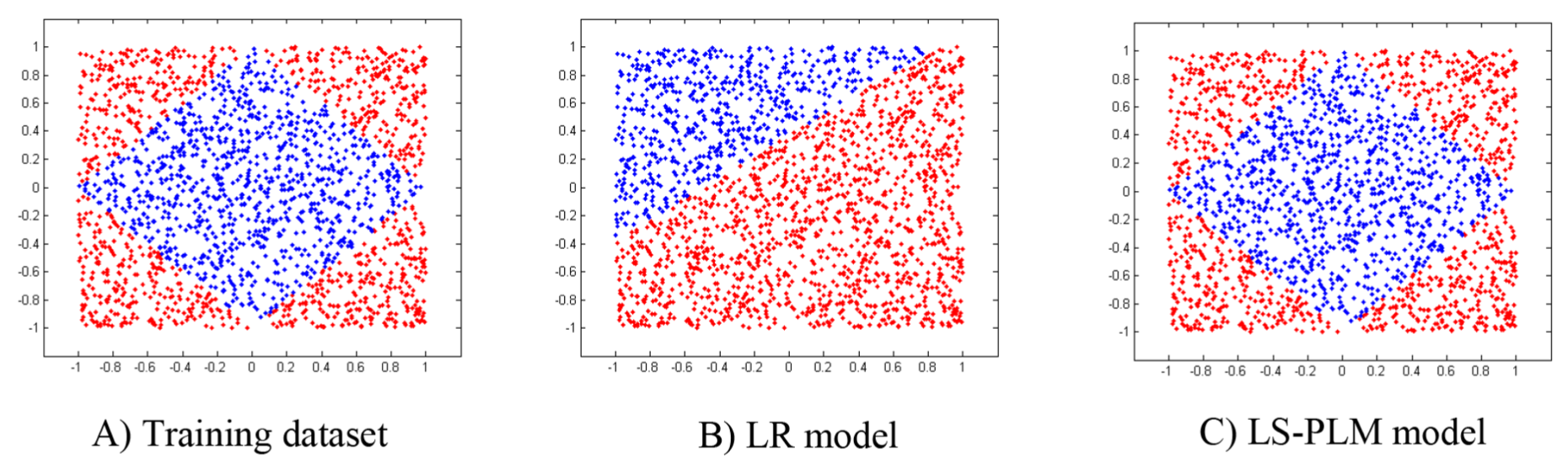
论文当中LS-PLM的效果与LR模型效果进行对比,如下图所示。
优势
LS-PLM存在三个优势:
- 非线性。通过足够的划分区域,LS-PLM可以拟合任何复杂的非线性函数。
- 可扩展性。与LR模型类似,LS-PLM可以扩展到大量样本和高维特征。在这之上设计了一个分布式系统,可以在数百台机器上并行训练模型。在线产品系统中,每天都会训练和部署几十个具有数千万参数的LS-PLM模型。
- 稀疏性。模型稀疏性是工业环境下在线服务的一个实际问题。这里展示了采用L1和L2,1正则器的LS-PLM可以实现良好的稀疏性。使得部署更加轻量级,在线推断效率也更高。
- 端到端的非线性学习能力。挖掘数据中的非线性模式,节省大量人工处理样本和特征工程的过程。
论文基于directional derivatives(方向导数)和quasi-Newton(拟牛顿)方法来解决因为正则项使得目标函数非凸的问题。
数学形式
LS-PLM的数学形式如下面公式所示
\]
首先用聚类函数\(\pi\)对模型进行分类分片,再用LR模型计算样本在分片中具体的CTR,然后将两者相乘之后求和。公式中的\(m\)就是分片数,可以较好地平衡模型的拟合能力和推广能力。当\(m=1\)时就会退化为普通的逻辑回归。
实际上,LS-PLM采用的softma函数x进行分类,sigmoid函数作为回归。于是公式变成:
\]
\(\{u_1,...u_m\}\)为聚类函数(分片函数)\(\pi_i\)的参数,\(\{w_1,...w_m\}\)为拟合函数\(\eta_i\)的参数。
优化
由于目标函数中的加入的正则化项\(L_1\),\(L_{2,1}\)都是非平滑函数,所以目标函数也是非平滑的、非凸函数。因为目标函数的负梯度方向并不存在,所以用能够得到f最小的方向导数的方向b作为负梯度的近似值。这里的推导比较复杂,可以看一下原来论文,之后我尽可能用通俗易懂的语言补充这里。
这个\(L_{2,1}\)挺意思的,贴一下它原来的公式:
\]
代码
import torch
import torch.nn as nn
import torch.optim as optim
class LSPLM(nn.Module):
def __init__(self, m, optimizer, penalty='l2', batch_size=32, epoch=100, learning_rate=0.1, verbose=False):
super(LSPLM, self).__init__()
self.m = m
self.optimizer = optimizer
self.batch_size = batch_size
self.epoch = epoch
self.verbose = verbose
self.learning_rate = learning_rate
self.penalty = penalty
self.softmax = None
self.logistic = None
self.loss_fn = nn.BCELoss(reduction='mean')
def fit(self, X, y):
if self.softmax is None and self.logistic is None:
self.softmax = nn.Sequential(
nn.Linear(X.shape[1], self.m).double(),
nn.Softmax(dim=1).double()
)
self.logistic = nn.Sequential(
nn.Linear(X.shape[1], self.m, bias=True).double()
, nn.Sigmoid())
if self.optimizer == 'Adam':
self.optimizer = optim.Adam(self.parameters(), lr=self.learning_rate)
elif self.optimizer == 'SGD':
self.optimizer = optim.SGD(self.parameters(), lr=self.learning_rate, weight_decay=1e-5, momentum=0.1,
nesterov=True)
# noinspection DuplicatedCode
for epoch in range(self.epoch):
start = 0
end = start + self.batch_size
while start < X.shape[0]:
if end >= X.shape[0]:
end = X.shape[0]
X_batch = torch.from_numpy(X[start:end, :])
y_batch = torch.from_numpy(y[start:end]).reshape(1, end - start)
y_batch_pred = self.forward(X_batch).reshape(1, end - start)
loss = self.loss_fn(y_batch_pred, y_batch)
loss.backward()
self.optimizer.step()
start = end
end += self.batch_size
if self.verbose and epoch % (self.epoch / 20) == 0:
print('EPOCH: %d, loss: %f' % (epoch, loss))
return self
def forward(self, X):
logistic_out = self.logistic(X)
softmax_out = self.softmax(X)
combine_out = logistic_out.mul(softmax_out)
return combine_out.sum(1)
def predict_proba(self, X):
X = torch.from_numpy(X)
return self.forward(X)
def predict(self, X):
X = torch.from_numpy(X)
out = self.forward(X)
out[out >= 0.5] = 1.0
out[out < 0.5] = 0.0
return out
参考
Learning Piece-wise Linear Models from Large Scale Data for Ad Click Predict
Github:hailingu/MLFM
LS-PLM学习笔记
推荐系统实践 0x0e LS-PLM的更多相关文章
- 协同滤波 Collaborative filtering 《推荐系统实践》 第二章
利用用户行为数据 简介: 用户在网站上最简单存在形式就是日志. 原始日志(raw log)------>会话日志(session log)-->展示日志或点击日志 用户行一般分为两种: 1 ...
- zz京东电商推荐系统实践
挺实在 今天为大家分享下京东电商推荐系统实践方面的经验,主要包括: 简介 排序模块 实时更新 召回和首轮排序 实验平台 简介 说到推荐系统,最经典的就是协同过滤,上图是一个协同过滤的例子.协同过滤主要 ...
- 推荐系统实践 0x07 基于邻域的算法(2)
基于邻域的算法(2) 上一篇我们讲了基于用户的协同过滤算法,基本流程就是寻找与目标用户兴趣相似的用户,按照他们对物品喜好的对目标用户进行推荐,其中哪些相似用户的评分要带上目标用户与相似用户的相似度作为 ...
- 推荐系统实践 0x0b 矩阵分解
前言 推荐系统实践那本书基本上就更新到上一篇了,之后的内容会把各个算法拿来当专题进行讲解.在这一篇,我们将会介绍矩阵分解这一方法.一般来说,协同过滤算法(基于用户.基于物品)会有一个比较严重的问题,那 ...
- 推荐系统实践 0x09 基于图的模型
用户行为数据的二分图表示 用户的购买行为很容易可以用二分图(二部图)来表示.并且利用图的算法进行推荐.基于邻域的模型也可以成为基于图的模型,因为基于邻域的模型都是基于图的模型的简单情况.我们可以用二元 ...
- Spark推荐系统实践
推荐系统是根据用户的行为.兴趣等特征,将用户感兴趣的信息.产品等推荐给用户的系统,它的出现主要是为了解决信息过载和用户无明确需求的问题,根据划分标准的不同,又分很多种类别: 根据目标用户的不同,可划分 ...
- 基于Neo4j的个性化Pagerank算法文章推荐系统实践
新版的Neo4j图形算法库(algo)中增加了个性化Pagerank的支持,我一直想找个有意思的应用来验证一下此算法效果.最近我看Peter Lofgren的一篇论文<高效个性化Pagerank ...
- 推荐系统实践 0x05 推荐数据集MovieLens及评测
推荐数据集MovieLens及评测 数据集简介 MoiveLens是GroupLens Research收集并发布的关于电影评分的数据集,规模也比较大,为了让我们的实验快速有效的进行,我们选取了发布于 ...
- 推荐系统实践 0x06 基于邻域的算法(1)
基于邻域的算法(1) 基于邻域的算法主要分为两类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法.我们首先介绍基于用户的协同过滤算法. 基于用户的协同过滤算法(UserCF) 基于用户的 ...
随机推荐
- 异常记录-Dialog样式踩坑
好久没记录文档了,拖了老半个月,终于空下来时间,为了避免以后踩坑,必须记录记录. 背景: 为activity设置样式为弹窗activity 异常一: activity设置style后,布局不能够正常显 ...
- 详解Java锁的升级与对比(1)——锁的分类与细节(结合部分源码)
前言 之前只是对Java各种锁都有所认识,但没有一个统一的整理及总结,且没有对"锁升级"这一概念的加深理解,今天趁着周末好好整理下之前记过的笔记,并归纳为此博文,主要参考资源为&l ...
- 插件Spire.PDF帮你高效搞定PDF打印
Spire.PDF介绍 Spire.PDF是一个专业的PDF组件,能够独立地创建.编写.编辑.操作和阅读PDF文件,支持 .NET.Java.WPF和Silverlight.Spire.PDF的PDF ...
- ABBYY FineReader 14创建PDF文档功能解析
使用ABBYY FineReader,您可以轻松查看和编辑任何类型的 PDF,真的是一款实至名归的PDF编辑转换器,您知道的,它能够保护.签署和编辑PDF文档,甚至还可以创建PDF文档,本文和小编一起 ...
- 美食vlog如何剪辑?用什么视频制作软件剪辑比较好?
是不是发现自己拍摄的美食永远没有美食博主拍出来的好看?那么美食vlog如何剪辑?用什么视频制作软件剪辑比较好呢?下面小编就教大家用视频编辑软件会声会影强大的颜色分级功能就能拯救你的美食vlog. 接下 ...
- 【移动自动化】【五】常用API
常用API click: 点击 sendKeys: 输入内容 swipe: 滑动 TouchAction:这也是手势操作 github https://github.com/wangxiao9/app ...
- Java基础教程——缓冲流
缓冲流 "缓冲流"也叫"包装流",是对基本输入输出流的增强: 字节缓冲流: BufferedInputStream , BufferedOutputStream ...
- PHP AES加密封装类
简介 PHP AES 加密解密常用封装类 使用方式 $key = 123; $aes = new Aes($key); $data = ['a' => 1]; $aes->decrypt( ...
- 老猿学5G扫盲贴:中国移动网络侧CHF的功能分解说明
☞ ░ 老猿Python博文目录░ 一.引言 在<老猿学5G扫盲贴:中国移动网络侧CHF主要功能及计费处理的主要过程>介绍了中国移动CHF的总体功能,同时说明了CHF网元主要由AGF.CD ...
- windows下使用pyinstaller将多个目录的Python文件打包成exe可执行文件
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 一.引言 需要将一个工程涉及两个目录的模块文件打包成exe,打包环境如 ...