ubuntu环境下搭建Hadoop集群中必须需要注意的问题
博主安装的hadoop是3.1.3这里是按照厦门大学那个博客安装的,在安装与启动过程中,费了不少事,特此记录一下问题。
安装的连接:
安装环境:http://dblab.xmu.edu.cn/blog/install-hadoop/
分布式搭建:http://dblab.xmu.edu.cn/blog/install-hadoop-cluster/
需要注意的是文中所讲的是hadoop2版本,其中集群搭建修改的五个配置文件中的 slaves文件,在hadoop3中已改名成 wordks 目录在/usr/local/hadoop/etc/hadoop。
如果前面伪分布式搭建能够正常启动的话,在分布式搭建的过程中主要还是配置文件需要按照他博文中的写好,我就是在配置文件上有时候对应的不够好,这里主节点master的配置文件需要和slave从节点的配置文件一样,还有/etc/hosts文件用vim编辑记得在前面加上sudo
不然权限不够无法保存。
最后hadoop3的访问端口是 master:9870;hadoop2版本访问的端口是50070,怪不得访问超时,我还以为DataNode的问题,有时候DataNode无法启动,需要将所有节点的 tmp、logs文件夹强制删除,停止服务后需要重新格式化 ./bin/hdfs namenode -format .
中间的节点如果没有启动的话,需要去日志中查看错误,找到对应的错误在Goole,查看日志的命令
less less logs/hadoop-hadoop-namenode-master.log
tail -10 logs/hadoop-hadoop-namenode-master.log # 最后10行的日志信息
head -5 hadoop-hadoop-namenode-master.log # 查看前10行日志信息
在启动服务之前需要查看防火墙的状态(以下的命令是ubuntu的)
systemctl status firewalld.service
# 如果是开着的需要 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service # 禁止firewall开机启动
最后搭建成功的截图
master节点
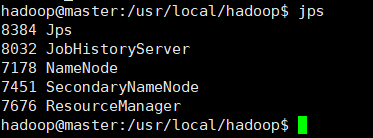
slave01
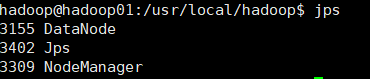
访问master:9870
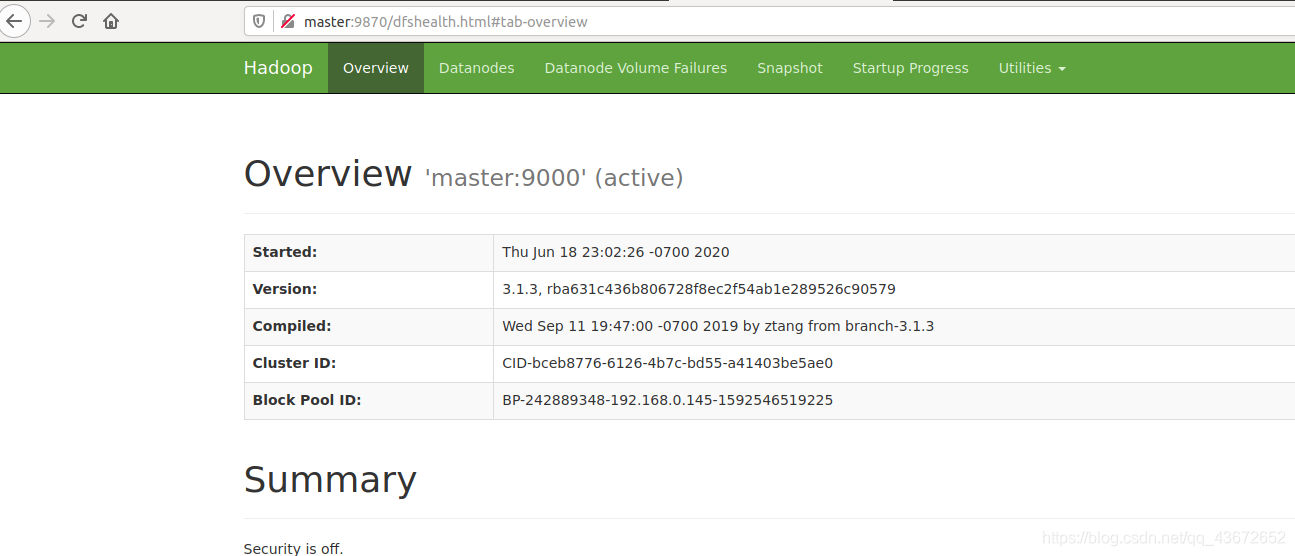
访问master:8088
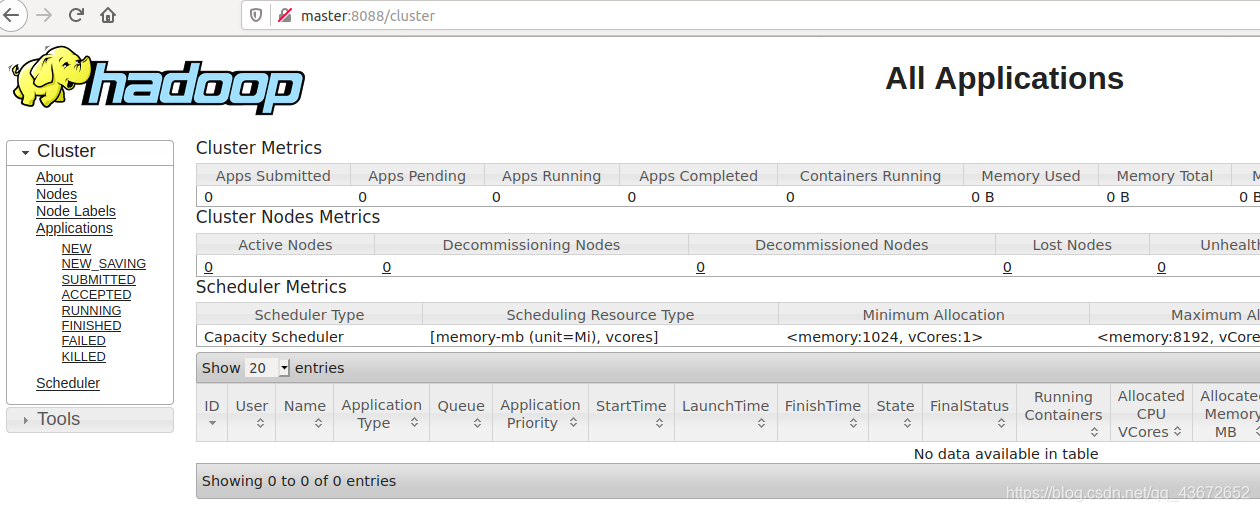
看间这头黄色的大象就代表搭建成功了。
ubuntu环境下搭建Hadoop集群中必须需要注意的问题的更多相关文章
- Linux下搭建Hadoop集群
本文地址: 1.前言 本文描述的是如何使用3台Hadoop节点搭建一个集群.本文中,使用的是三个Ubuntu虚拟机,并没有使用三台物理机.在使用物理机搭建Hadoop集群的时候,也可以参考本文.首先这 ...
- windows环境下搭建Redis集群
转载请注明出处,原文章地址: https://www.cnblogs.com/tommy-huang/p/6240083.html Redis集群: 如果部署到多台电脑,就跟普通的集群一样:因为Red ...
- linux系统centOS7下搭建redis集群中ruby版本过低问题的解决方法
问题描述: 在Centos7中,通过yum安装ruby的版本是2.0.0,但是如果有些应用需要高版本的ruby环境,比如2.2,2.3,2.4... 那就有点麻烦了,譬如:我准备使用redis官方给的 ...
- Linux下搭建Hadoop集群(Centos7.0)
Hadoop集群安装 概述 集群 cluster,将很多任务进程分布到多台计算机上:通过联合使用多台计算机的存储.计算能力完成更庞大的任务.为了实现无限量的存储和计算能力,在生产环境中必须使用集群来满 ...
- Windows环境下搭建Redis集群(Redis-x64-3.2.100)
一 .前期准备Redis.Ruby语言运行环境.Redis的Ruby驱动redis-xxxx.gem.创建Redis集群的工具redis-trib.rb 二.安装配置redisredis下载地址 ht ...
- RabbitMQ:Docker环境下搭建rabbitmq集群
RabbitMQ作为专业级消息队列:如何在微服务框架下搭建 使用组件 文档: https://github.com/bijukunjummen/docker-rabbitmq-cluster 下载镜像 ...
- CentOS7 环境下 在Hadoop集群安装Hive
1.下载Hive的tar.gz包:http://mirror.bit.edu.cn/apache/hive/ 2.放入CentOS 7 系统中并解压:tar -zxvf apache-hive-2.3 ...
- 虚拟机搭建Hadoop集群
安装包准备 操作系统:ubuntu-16.04.3-desktop-amd64.iso 软件包:VirtualBox 安装包:hadoop-3.0.0.tar.gz,jdk-8u161-linux-x ...
- 在搭建Hadoop集群环境时遇到的一些问题
最近在学习搭建hadoop集群环境,在搭建的过程中遇到很多问题,在这里做一些记录.1. SSH相关的问题 问题一: ssh: connect to host localhost port 22: Co ...
随机推荐
- AcWing 345. 牛站 Cow Relays
由于我太菜了,不会矩阵乘法,所以给同样不会矩阵乘法同学的福利 首先发现这题点很多边很少,实际上有用的点 \(<= 2 * T\)(因为每条边会触及两个点嘛) 所以我们可以把点的范围缩到 \(2 ...
- redis学习之——Redis事务(transactions)
Redis事务:可以一次执行多个命令,本质是一组命令的集合.一个事务中的,所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞. 常用命令:MULTI 开启事务 EXEC 提交事务 ...
- Angular学习知识点记录
问:版本直接跳转到Angular4? 答:为了遵循严格的版本策略.在angular2.x的时候,angular route的版本已经是版本3了.因此为了版本统一,angular直接从2跳到了4,.参考 ...
- Pytest学习(20)- allure之@allure.step()、allure.attach的详细使用
一.@allure.step的用法 可以理解为我们编写测试用例中的每一步操作步骤,而在allure中表示对每个测试用例进行非常详细的步骤说明 通过 @allure.step(),可以让测试用例在all ...
- uni-app中组件的使用
组件基本知识点: uniapp中:每个页面可以理解为一个单页面组件,这些单页面组件注册在pages.json里,在组件关系中可以看作父组件. 自定义可复用的组件,其结构与单页面组件类似,通常在需要的页 ...
- Goldengate搭建
OGG进程 捕获进程(源端):捕获online redo log或者archived log中增量事务日志 传输进程(源端):把目标端落地的trail文件通过配置的路由信息传输到目标端 网络传输:tc ...
- IOS开发中设置导航栏主题
/** * 系统在第一次使用这个类的时候调用(1个类只会调用一次) */ + (void)initialize { // 设置导航栏主题 UINavigationBar *navBar = [UINa ...
- 云图说 | 云上资源管控有神器!关于IAM,你想知道的都在这里!
摘要:统一身份认证(Identity and Access Management,简称IAM)是华为云上帮助您安全控制华为云资源访问权限的基础服务.通过本期云图说,您可以初步了解IAM的基本功能. 从 ...
- Erlang那些事儿之正儿八经的前言
说在前面,为啥要码这些,并不是因为喜欢它,恰恰相反,我非常讨厌Erlang(真香警告)这位二郎神(Erlang的谐音),讨厌它的语法,讨厌它不变的变量,讨厌它的一切. 曾经的我,一听到这个语言,我就打 ...
- hugging face-基于pytorch-bert的中文文本分类
1.安装hugging face的transformers pip install transformers 2.下载相关文件 字表: wget http://52.216.242.246/model ...