Web Scraping using Python Scrapy_BS4 - using Scrapy and Python(2)
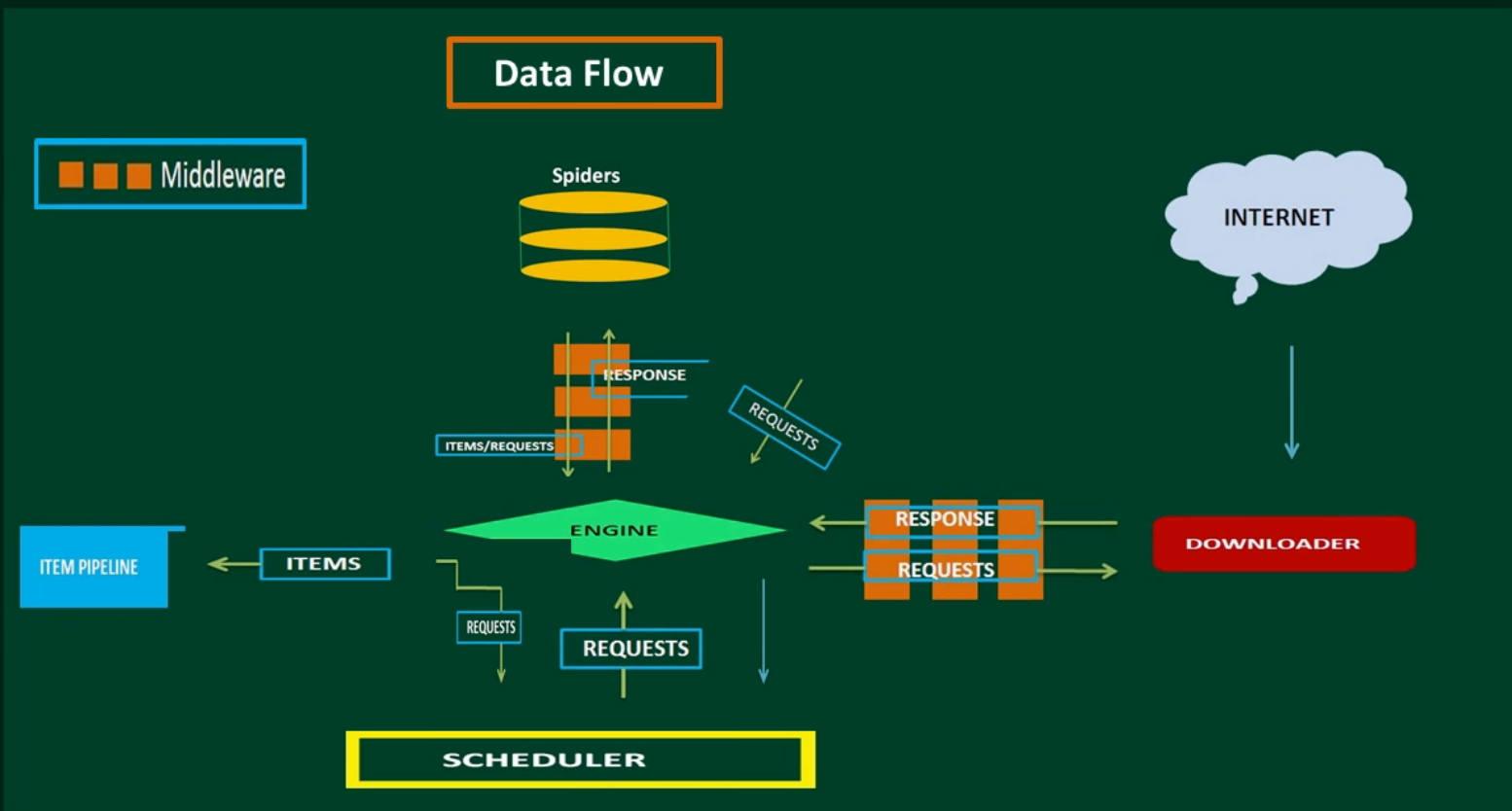
Scrapy Architecture
Creating a Spider.
Spiders are classes that you define that Scrapy uses to scrape(extract) information from a website(s).
import scrapy class QuoteSpider(scrapy.Spider):
name = "quote"
start_urls = [
'https://bluelimelearning.github.io/my-fav-quotes/'
] def parse(self, response):
for quote in response.css('div.quotes'):
yield{
'quote':quote.css('p.aquote::text').extract(),
'author':quote.css('p.author::text').extract_first(),
}

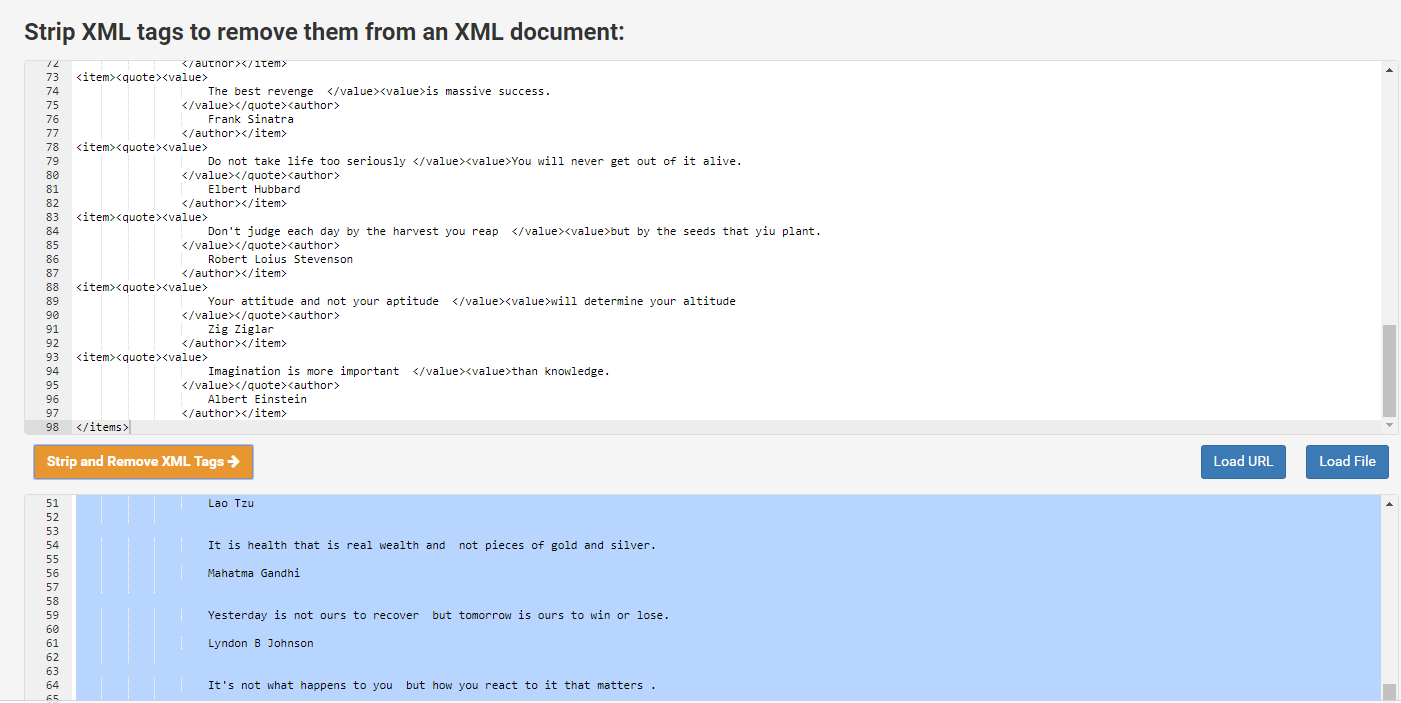
Running your spider and saving scrapped data.
scrapy runspider quotes_spiders.py -o quotes.xml


https://www.cleancss.com/strip-xml/
Scraping data with Scrapy Shell
scrapy shell "https://bluelimelearning.github.io/my-fav-quotes/"

response.css('title')

response.css('title::text').extract()

response.css('h1::text').extract()

quote = response.css("div.quotes")[]
aquote = quote.css("p.aquote::text").extract()
aquote

Web Scraping using Python Scrapy_BS4 - using Scrapy and Python(2)的更多相关文章
- Web Scraping using Python Scrapy_BS4 - using Scrapy and Python(1)
Create a new Scrapy project first. scrapy startproject projectName . Open this project in Visual Stu ...
- Web Scraping using Python Scrapy_BS4 - using BeautifulSoup and Python
Use BeautifulSoup and Python to scrap a website Lib: urllib Parsing HTML Data Web scraping script fr ...
- Web Scraping using Python Scrapy_BS4 - Software
Install the following software before web scraping. Visual Studio Code Python and Pip pip install vi ...
- Web Scraping using Python Scrapy_BS4 - Introduction
What is Web Scraping This is also referred to as web harvesting and web data extraction. This is the ...
- Web Scraping with Python
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- How To Crawl A Web Page with Scrapy and Python 3
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Web Scraping with Python读书笔记及思考
Web Scraping with Python读书笔记 标签(空格分隔): web scraping ,python 做数据抓取一定一定要明确:抓取\解析数据不是目的,目的是对数据的利用 一般的数据 ...
- <Web Scraping with Python>:Chapter 1 & 2
<Web Scraping with Python> Chapter 1 & 2: Your First Web Scraper & Advanced HTML Parsi ...
- Web scraping with Python (part II) « Jean, aka Sig(gg)
Web scraping with Python (part II) « Jean, aka Sig(gg) Web scraping with Python (part II)
随机推荐
- AIO,BIO,NIO,IO复用,同步,异步,阻塞和非阻塞
(1)什么是NIO(Non-blocked IO),AIO,BIO (2) 区别 (3)select 与 epoll,poll区别 1.什么是socket?什么是I/O操作? 什么是socket? 实 ...
- Oracle调用Java方法(上)如何使用LoadJava命令和如何将简单的Jar包封装成Oracle方法
最近在工作中遇到了遇到了一个需求需要将TIPTOP中的数据导出成XML并上传到FTP主机中,但是4GL这方面的文档比较少最终决定使用Oracle调用Java的方法,在使用的过程中发现有很多的坑,大部分 ...
- 看了Java的Class的源码,我自闭了
java源码之Class 源码的重要性不言而喻,虽然枯燥,但是也有拍案叫绝.这是我的源码系列第二弹,后续还会一直更新,欢迎交流.String源码可以看我的Java源码之String,如有不足,希望 ...
- git常用代码合集
git常用代码合集 1. Git init:初始化一个仓库 2. Git add 文件名称:添加文件到Git暂存区 3. Git commit -m “message”:将Git暂存区的代码提交到Gi ...
- springboot 2.X 集成redis
在实际开发中,经常会引入redis中间件做缓存,这里介绍springboot2.X后如何配置redis 1 Maven中引入redis springboot官方通过spring-boot-autoco ...
- 迷你图书管理系统 源代码 Java初级小项目
今天博主再给大家分享一个小项目:MiNi图书管理系统.用的是Java语言开发的,代码不多,大概260行左右吧,系统是实现图书的新增图书.删除图书.借阅图书.归还图书.查看图书等简单的功能(后附源代码) ...
- SpringBoot — HelloWorld开发部署
springboot官方推荐使用jdk1.8 一.配置pom.xml 二.Application.java 三.HelloController.java 四.项目运行: Application.jav ...
- es性能调优---写优化操作
ES 的默认配置,是综合了数据可靠性.写入速度.搜索实时性等因素.实际使用时,我们需要根据公司要求,进行偏向性的优化. 写优化 假设我们的应用场景要求是,每秒 300 万的写入速度,每条 500 字节 ...
- Illegal reflective access by org.apache.hadoop.security.authentication.util.KerberosUtil
在使用Java API操作HBase时抛出如下异常: Illegal reflective access by org.apache.hadoop.security.authentication.ut ...
- vs code 初始化vue项目框架
1.首先安装npm组件 下载地址:https://nodejs.org/en/ 安装完 2.配置环境变量 3.验证是否成功 node -v npm -v 4.替换npm 输入npm install ...