无所不能的embedding 3. word2vec->Doc2vec[PV-DM/PV-DBOW]
这一节我们来聊聊不定长的文本向量,这里我们暂不考虑有监督模型,也就是任务相关的句子表征,只看通用文本向量,根据文本长短有叫sentence2vec, paragraph2vec也有叫doc2vec的。这类通用文本embedding的应用场景有很多,比如计算文本相似度用于内容召回, 用于聚类给文章打标等等。前两章我们讨论了词向量模型word2vec和Fasttext,那最简单的一种得到文本向量的方法,就是直接用词向量做pooling来得到文本向量。这里pooling可以有很多种, 例如
- 文本所有单词,词向量 average pooling
- 文本所有单词,词向量 TF-IDF weighted average pooling
- 文本提取关键词,词向量 average pooling
- 文本提取关键词,词向量 weighted average pooling
想了解细节的可以看下REF[3,5],但基于word2vec的文本向量表达最大的问题,也是词袋模型的局限, 就是向量只包含词共现信息,忽略了词序信息和文本主题信息。这个问题在短文本上问题不大,但对长文本的影响会更大些。于是在word2vec发表1年后还是Mikolov大大,给出了文本向量的另一种解决方案PV-DM/PV-DBOW。下面例子的完整代码见 github-DSXiangLi-Embedding-doc2vec
模型
PV-DM 训练
在CBOW的基础上,PV-DM加入了paragraph-id,每个ID对应训练集一个文本,可以是一句话,一个段落或者一条新闻对应。paragraph-id和词一样通过embedding矩阵得到唯一的对应向量。然后以concat或者average pooling的方式和CBOW设定窗口内的单词向量进行融合,通过softmax来预测窗口中间词。

这个paragraaph-id具体做了啥嘞?这里需要回顾下word2vec的word embedding是如何通过back propogation得到的。不清楚的可以来这里回顾下哟无所不能的Embedding 1. Word2vec模型详解&代码实现
第一步hidden->output更新output embedding矩阵,在CBOW里h只是window_size内词向量的平均,而在PV-DM中,\(h\)包含了paragraph-id映射得到的文本向量,这个向量是整个paragraph共享的,所以在窗口滑动的时候会保留部分paragraph的主题信息,这部分信息会用于output embedidng的更新。
v_{w^{'}j}^{(new)} &= v_{w^{'}j}^{(old)} - \eta \cdot e_j \cdot h
\end{align}
\]
第二步input->hidden更新input embedding矩阵, 前一步学到的主题信息会反过来用于input embedding的更新,让同一个paragraph里的单词都学到部分主题信息。而paragraph-id本身对应的向量在每个滑动窗口都会被更新一次,更新用到之前paragraph的信息和窗口内的词向量信息。
v_{w_I}^{(new)} &= v_{w_I}^{(old)} - \eta \cdot \sum_{j=1}^V e_j \cdot v_{w^{'}j}
\end{align}
\]
之前有看到把paragraph-id对应向量的信息说成上下文信息,但感觉会有点高估PV-DM的效果,因为这里依旧停留在词袋模型,并没有考虑真正考虑到词序信息。只是通过不同paragraph对应不同的向量,来区分相同单词在不同主题内的词共现信息的差异,更近似于从概率到条件概率的改变。而paragrah-id对应的vector,感觉更多是以比较玄妙的方式得到的加权的word embedding。
PV-DBOW训练
PV-DBOW和Skip-gram的结构近似,skip-gram是中间词预测上下文, PV-DBOW则是用paragraph对应向量来预测文本中的任意词汇。和上面的PV-DM相比,也就是进一步省略了window内的词汇,所以优点就是训练所需内存占用会更少。
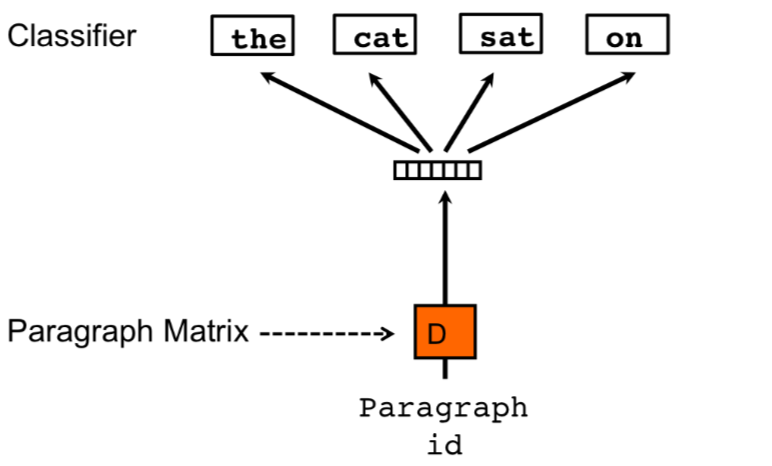
作者表示多数情况下PV-DM都要比PV-DBOW要好。不过二者一起使用,得到两个文本向量后做concat,再用于后续的监督学习效果最好。
模型预测
doc2vec和word2vec一个明显的区别,就是对样本外的文本向量是需要重新训练的。以PV-DM为例,在infer阶段,我们会把单词的input embedding,output embedding,以及bias都freeze,只对样本外的document embedding进行训练,因此doc2vec的预测部分是相对耗时的,因为也需要一定数量的epochs来保证样本外的document embedding收敛。这个特点部分降低了doc2vec在实际应用中的可用性。
Gensim实践
这里我们基于Gensim提供的word2vec和doc2vec模型,我们分别对搜狗新闻文本向量的建模,对比下二者在文本向量和词向量相似召回上的差异。
训练集测试集对比
上面提到Doc2vec用PV-DM训练会得到训练集的embedding,对样本外文本则需要重新训练得到预测值。基于doc2vec这个特点,我们来对比下同一个文本,训练的embedding和infer的 embedding是否存在差异。代码里我们默认样本内文本可以通过传入tag得到,这个和gensim的TaggedDocument逻辑一致,而样本外文本需要直接传入分词tokens。所以只需把训练样本从token传入,再按相似度召回最相似的文本即可。这里infer的epochs和训练epochs一致.

在以上的结果中,我们发现同一文本,样本内和样本外的cosine相似度高达0.98,虽然infer和训练embedding不完全一致,但显著高于和其他文本的相似度。这个测试不能用来衡量模型的准确性,但可以作为sanity check。
文本向量对比
我们对比下Doc2vec和Word2vec得到的文本向量,在召回相似文本上的表现。先看短文本,会发现word2vec和doc2vec表现相对一致,召回的相似文本一致,因为对短文本来说上下文信息的影响会小。

在长文本上(文本太长不方便展示,详见JupyterNotebook),word2vec和doc2vec差异较明显,但在随机选取的几个case上,并不能明显感知到doc2vec在长文本上的优势,当然这可能和模型参数选择有关。
对此更有说服力的应该是Google【Ref2】对几个文本向量模型在wiki和arivx数据集的召回对比,他们分别对比了LDA,doc2vec,average word embedding和BOW。 虽然doc2vec在两个数据集的准确度都是最高的。。。算了把accuracy放上来大家自己感受下吧。。。doc2vec的优势真的并不明显。。。再一看呦呵最佳embedding size=10000,莫名有一种大力出奇迹的感觉。。。
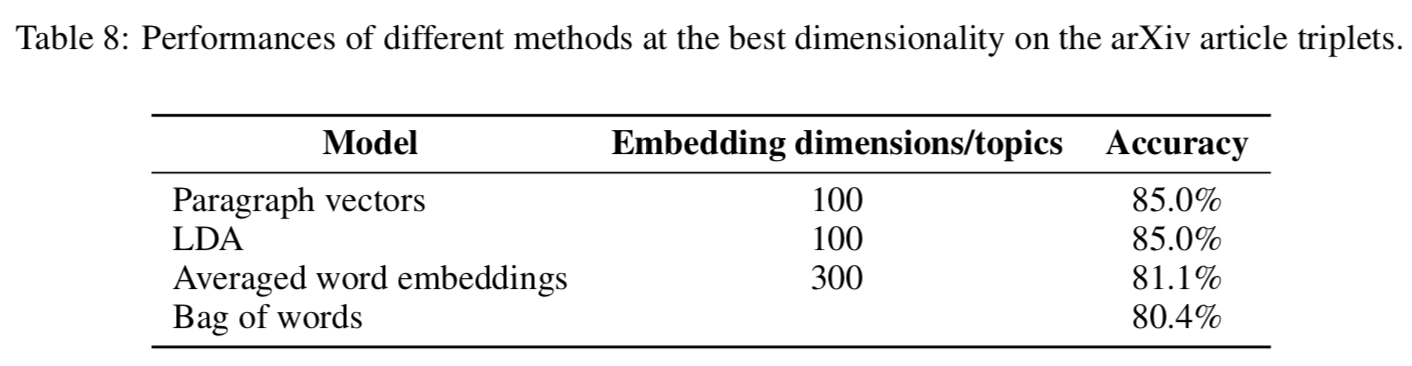
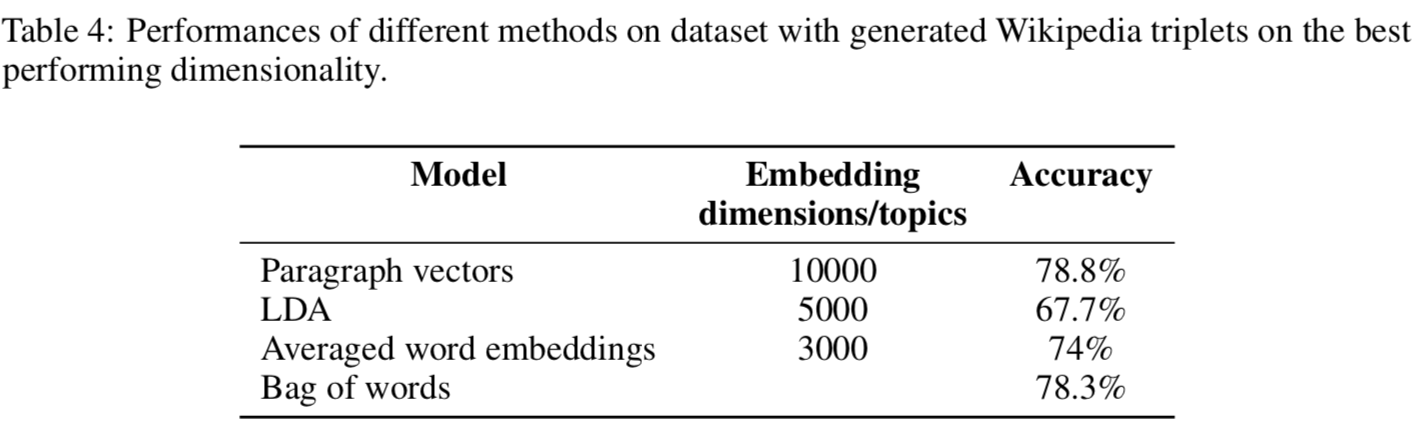
词向量对比
考虑我们用的PV-DM建模在训练文本向量的同时也会得到词向量,这里我们对比下在相同corpus,相同参数的word2vec和doc2vec得到的词向量的差异。
考虑北京今年雨水多到的让我以为到了江南,我们来看下下雨类词汇召回的top10相似的词,由上到下按词频从高到低排序。

比较容易发现对于高频词,Doc2vec和word2vec得到的词向量相似度会更接近,也比较符合逻辑因为高频词会在更多的doc中出现,因此受到document vector的影响会更小(被平均)。而相对越低频的词,doc2vec学到的词向量表达,会带有更多的主题信息。如果说word2vec是把语料里所有的document混在一起训练得到general的词向量表达,doc2vec更类似于学到conditional的词向量表达。所以脱离当前语料,doc2vec的词向量实用价值比较玄学,因为不太说的清楚它到底是学到的了啥。
整体看来PV-DM/DBOW没有特别眼前一亮的感觉,不过毕竟是14年的论文了,这只是文本表征的冰山一角,后面还能扯出一系列的encoder-decoder,transformer框架啥的。预知后事如何,咱慢慢往后瞧着~
无所不能的embedding系列
https://github.com/DSXiangLi/Embedding
无所不能的Embedding 1. Word2vec模型详解&代码实现
无所不能的Embedding 2. FastText词向量&文本分类
Reference
- Quoc V. Le and Tomas Mikolov. 2014. Distributed representations of sentences and documents. [Google]
- Andrew M Dai, Christopher Olah, Quov. 2015. Document Embedding with Paragraph Vectors[Google]
- Sanjeev Arora, Yingyu Liang, and Tengyu Ma. 2017. A simple but tough-to-beat baseline for sentence embeddings .
- Han Jey Lau and Timothy Baldwin. 2016. An Empirical Evaluation of doc2vec with Practical Insights into Document Embedding[IBM]
- Craig w. 2019. Improving a tf-idf weighted document vector embedding.tripAdvisor
- https://radimrehurek.com/gensim/models/doc2vec.html
- https://zhuanlan.zhihu.com/p/50443871
- https://www.bookstack.cn/read/huaxiaozhuan-ai/spilt.7.142adbd00f395138.md#fdu4nj
- https://supernlp.github.io/2018/11/26/sentreps/
- http://d0evi1.com/paragraph2vec/
无所不能的embedding 3. word2vec->Doc2vec[PV-DM/PV-DBOW]的更多相关文章
- 无所不能的Embedding 1 - Word2vec模型详解&代码实现
word2vec是google 2013年提出的,从大规模语料中训练词向量的模型,在许多场景中都有应用,信息提取相似度计算等等.也是从word2vec开始,embedding在各个领域的应用开始流行, ...
- 无所不能的Embedding 2. FastText词向量&文本分类
Fasttext是FaceBook开源的文本分类和词向量训练库.最初看其他教程看的我十分迷惑,咋的一会ngram是字符一会ngram又变成了单词,最后发现其实是两个模型,一个是文本分类模型[Ref2] ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- 情感分析的现代方法(包含word2vec Doc2Vec)
英文原文地址:https://districtdatalabs.silvrback.com/modern-methods-for-sentiment-analysis 转载文章地址:http://da ...
- Embedding和Word2Vec实战
在之前的文章中谈到了文本向量化的一些基本原理和概念,本文将介绍Word2Vec的代码实现 https://www.cnblogs.com/dogecheng/p/11470196.html#Word2 ...
- embedding与word2vec
embedding是指将目标向量化,常用于自然语言处理(如:Word2Vec).这种思想的意义在于,可以将语义问题转换为数值计算问题,从而使计算机能够便捷处理自然语言问题.如果采用传统的One-hot ...
- Word Embedding与Word2Vec
http://blog.csdn.net/baimafujinji/article/details/77836142 一.数学上的“嵌入”(Embedding) Embed这个词,英文的释义为, fi ...
- word2vec和word embedding有什么区别?
word2vec和word embedding有什么区别? 我知道这两个都能将词向量化,但有什么区别?这两个术语的中文是什么? from: https://www.zhihu.com/question ...
- 文本表征:SoW、BoW、TF-IDF、Hash Trick、doc2vec、DBoW、DM
原文地址:https://www.jianshu.com/p/2f2d5d5e03f8 一.文本特征 (一)基本文本特征提取 词语数量 常,负面情绪评论含有的词语数量比正面情绪评论更多. 字符数量 常 ...
随机推荐
- 安装Apache所踩的的坑
刚开始接触PHP等一些脚本语言,需要建立一个本地的服务器,变进行安装了Apache.在其中碰到了诸多问题,和大家一一分享一下. 一.刚解压完成后使用cmd面板进入解压完成的apache的bin目录下, ...
- 《神经网络的梯度推导与代码验证》之FNN(DNN)前向和反向过程的代码验证
在<神经网络的梯度推导与代码验证>之FNN(DNN)的前向传播和反向梯度推导中,我们学习了FNN(DNN)的前向传播和反向梯度求导,但知识仍停留在纸面.本篇章将基于深度学习框架tensor ...
- Oracle RAC与DG
RAC RAC: real application clustersrac RAC: real application clustersrac 单节点数据库:数据文件和示例文件一一对应 实例损坏时数据 ...
- uniapp 获取元素高度 距离顶部高度等
let _this=this let height="" const query = uni.createSelectorQuery() query.select('#u-drop ...
- 常见的开源 License
目录 什么是开源软件 什么是 license 商业许可证与开源许可证 对开发者的影响 开源许可证的类型 如何选择开源许可证 什么是开源软件 开放源代码的软件.假设有一天自我感觉代码能力不错,写了个小工 ...
- maven配置settings.xml【阿里云】
<?xml version="1.0" encoding="utf-8"?> <settings xmlns="http://mav ...
- leetcode刷题-53最大子序和
题目 给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和. 思路 动态规划:求整个数组的连续子数组的最大和,可以求出每个位置的连续子数组的最大和,返回 ...
- i春秋公益赛之signin
题目链接:https://buuoj.cn/challenges#gyctf_2020_signin 查看程序保护 只开了canary和NX保护,在IDA查看反编译出来的为代码时发现程序给了一个后门 ...
- springboot2.x基础教程:自动装配原理与条件注解
spring Boot采用约定优于配置的方式,大量的减少了配置文件的使用.该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置. 当springboot启动的时候,默认在容器中注入 ...
- 6.AVCodecContext和AVCodec
AVCodecContext AVCodecContext 结构表示程序运行的当前 Codec 使用的上下文,着重于所有 Codec 共有的属性(并且是在程序运行时才能确定其值)和关联其他结构的字段 ...