【原】Spark中Job如何划分为Stage
版权声明:本文为原创文章,未经允许不得转载。
复习内容:
Spark中Job的提交 http://www.cnblogs.com/yourarebest/p/5342404.html
1.Spark中Job如何划分为Stage
我们在复习内容中介绍了Spark中Job的提交,下面我们看如何将Job划分为Stage。
对于JobSubmitted事件类型,通过 dagScheduler的handleJobSubmitted方法处理,方法源码如下:
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
//根据jobId生成新的Stage,详见1
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
...
Stage的提交及TaskSet(tasks)的提交
...
}
1.newResultStage方法如下, 根据jobId生成一个ResultStage
private def newResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
//根据jobid和rdd得到父Stages和StageId,详见2
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, jobId)
//根据父Stages和StageId生成ResultStage,详见4
val stage = new ResultStage(id, rdd, func, partitions, parentStages, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
2.getParentStagesAndId方法如下所示:
private def getParentStagesAndId(rdd: RDD[_], firstJobId: Int): (List[Stage], Int) = {
val parentStages = getParentStages(rdd, firstJobId),详见3
val id = nextStageId.getAndIncrement()
(parentStages, id)
}
3.getParentStages方法如下所示:
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
val parents = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
//将要遍历的RDD放到栈Stack中
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
dep match {
//判断rdd的依赖关系,如果是ShuffleDependency说明是宽依赖,详见4
case shufDep: ShuffleDependency[, , _] =>
parents += getShuffleMapStage(shufDep, firstJobId)
//是窄依赖
case _ =>
//遍历rdd的父RDD是否有父Stage存在
waitingForVisit.push(dep.rdd)
} } } }
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
//调用visit方法访问出栈的RDD
visit(waitingForVisit.pop())
}
parents.toList
}
4.getShuffleMapStage方法如下所示:
private def getShuffleMapStage(
shuffleDep: ShuffleDependency[, , _],
firstJobId: Int): ShuffleMapStage = {
shuffleToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) => stage
case None =>
// We are going to register ancestor shuffle dependencies,详见5
getAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
//根据firstJobId生成ShuffleMapStage,详见6
shuffleToMapStage(dep.shuffleId) = newOrUsedShuffleStage(dep, firstJobId)
}
// Then register current shuffleDep
val stage = newOrUsedShuffleStage(shuffleDep, firstJobId)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}
5.getAncestorShuffleDependencies方法如下:
private def getAncestorShuffleDependencies(rdd: RDD[_]): Stack[ShuffleDependency[, , _]] = {
val parents = new Stack[ShuffleDependency[, , _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
dep match {
case shufDep: ShuffleDependency[, , _] =>
if (!shuffleToMapStage.contains(shufDep.shuffleId)) {
parents.push(shufDep)
}
case _ =>
}
waitingForVisit.push(dep.rdd)
}
}
}
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents
}
6.newOrUsedShuffleStage方法如下所示,根据给定的RDD生成ShuffleMapStage,如果shuffleId对应的Stage已经存在与MapOutputTracker,那么number和位置输出的位置信息都可以从MapOutputTracker找到
private def newOrUsedShuffleStage(
shuffleDep: ShuffleDependency[, , _],
firstJobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
val numTasks = rdd.partitions.length
val stage = newShuffleMapStage(rdd, numTasks, shuffleDep, firstJobId, rdd.creationSite)
if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId)
val locs = MapOutputTracker.deserializeMapStatuses(serLocs)
for (i <- 0 until locs.length) {
stage.outputLocs(i) = Option(locs(i)).toList // locs(i) will be null if missing
}
stage.numAvailableOutputs = locs.count(_ != null)
} else {
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}
2.Stage描述
一个Stage是一组并行的tasks;一个Stage可以被多个Job共享;一些Stage可能没有运行所有的RDD的分区,比如first 和 lookup;Stage的划分是通过是否存在Shuffle为边界来划分的,Stage的子类有两个:ResultStage和ShuffleMapStage
对于窄依赖生成的是ResultStage,对于宽依赖生成的是ShuffleMapStage。当ShuffleMapStages执行完后,产生输出文件,等待reduce task去获取,同时,ShffleMapStages也可以通过DAGScheduler的submitMapStage方法独立作为job被提交
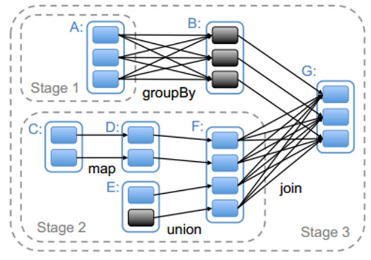
stage划分示意图
下一篇我们看Stage如何提交的。
【原】Spark中Job如何划分为Stage的更多相关文章
- 【Spark篇】--Spark中的宽窄依赖和Stage的划分
一.前述 RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖. Spark中的Stage其实就是一组并行的任务,任务是一个个的task . 二.具体细节 窄依赖 父RDD和子RDD parti ...
- 【原】Spark中Stage的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Job如何划分为Stage http://www.cnblogs.com/yourarebest/p/5342424.html 1 ...
- spark 中划分stage的思路
窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用,表现为 一个父RDD的分区对应于一个子RDD的分区 两个父RDD的分区对应于一个子RDD 的分区. 宽依赖指子RDD的每个分区都要依赖于父RD ...
- 【原】 Spark中Task的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Stage的提交 http://www.cnblogs.com/yourarebest/p/5356769.html Spark中 ...
- 【原】Spark中Job的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. Spark程序程序job的运行是通过actions算子触发的,每一个action算子其实是一个runJob方法的运行,详见文章 SparkContex源码 ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- 【原】 Spark中Worker源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Worker源码分析(一)http://www.cnblogs.com/yourarebest/p/5300202.html 4.receive方法, r ...
- Spark中Task,Partition,RDD、节点数、Executor数、core数目的关系和Application,Driver,Job,Task,Stage理解
梳理一下Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数.Executor数.core数目的关系. 输入可能以多个文件的形式存储在H ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
随机推荐
- 关于WPF中Popup控件的小记
在wpf开发中,常需要在鼠标位置处弹出一个“提示框”(在此就以“提示框”代替吧),通过“提示框”进行信息提示或者数据操作,如果仅仅是提示作用,使用ToolTip控件已经足够,但是有些是需要在弹出的框中 ...
- javascripct导图
分别归类为: 1 .javascript变量 2. javascript运算符 3. javascript数组 4. javascript流程语句 5. javascript字符串函数 6. java ...
- Mac OS X下GnuPlot的安装和配置(无法set term png等图片输出)
今天使用gitstats分析git repo的活动信息,发现其内部使用gnuplot,结果发现无法生成png图片,进入gnuplot的shell发现无法设置png格式输出.如下 gnuplot> ...
- 【Ubuntu12.04】安装搜狗输入法
我的系统版本是Ubuntu12.04 32位 卸载Ibus输入法 sudo apt-get remove ibus 注意: 安装ibus的命令是 sudo apt-get install fcitx ...
- asp.net mvc get controller name and action name
@{ var controller = @HttpContext.Current.Request.RequestContext.RouteData.Values["controller&qu ...
- OpenGL ES 3.0 基础知识
首先要了解OpenGL的图形管线有哪些内容,再分别去了解其中的相关的关系: 管线分别包括了顶点缓冲区/数组对象,定点着色器,纹理,片段着色器,变换反馈,图元装配,光栅化,逐片段操作,帧缓冲区.其中顶点 ...
- DB天气app冲刺第八天
---恢复内容开始--- 今天已经是第八天了冲刺,本来今天的ui设计已经基本成型了,今天下午设计什么的都弄好了,然后自己手贱clean了一下,可能是自己的程序的bug吧,调试没有错误,安装在模拟器上以 ...
- cmd命令查看端口和进程信息
在我们进行WEB开发时,往往会遇到socket连接到服务器出现无法响应的问题,归根结底就是网络通讯问题,或者端口未开启的问题,下面总结了一下找出原因的方法 1 看与服务器的连接:ping ip地址
- CSS 元素透明
1.HTML 元素透明 其实本身,CSS 实现元素透明是件容易事儿.直接上代码: opacity:.5 opacity 指的是不透明度,取值为 0~1 之间,1 表示完全不透明,0 表示完全透明. A ...
- C语言中随机数的生成
刚好在找这方面的资料,看到了一片不错的,就全文转过来了,省的我以后再找找不到. 在C语言中,可以通过rand函数得到一个“伪随机数”.这个数是一个整数,其值大于等于0且小于等于RAND_MAX.ran ...