【原】Spark中Job如何划分为Stage
版权声明:本文为原创文章,未经允许不得转载。
复习内容:
Spark中Job的提交 http://www.cnblogs.com/yourarebest/p/5342404.html
1.Spark中Job如何划分为Stage
我们在复习内容中介绍了Spark中Job的提交,下面我们看如何将Job划分为Stage。
对于JobSubmitted事件类型,通过 dagScheduler的handleJobSubmitted方法处理,方法源码如下:
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
//根据jobId生成新的Stage,详见1
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
...
Stage的提交及TaskSet(tasks)的提交
...
}
1.newResultStage方法如下, 根据jobId生成一个ResultStage
private def newResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
//根据jobid和rdd得到父Stages和StageId,详见2
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, jobId)
//根据父Stages和StageId生成ResultStage,详见4
val stage = new ResultStage(id, rdd, func, partitions, parentStages, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
2.getParentStagesAndId方法如下所示:
private def getParentStagesAndId(rdd: RDD[_], firstJobId: Int): (List[Stage], Int) = {
val parentStages = getParentStages(rdd, firstJobId),详见3
val id = nextStageId.getAndIncrement()
(parentStages, id)
}
3.getParentStages方法如下所示:
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
val parents = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
//将要遍历的RDD放到栈Stack中
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
dep match {
//判断rdd的依赖关系,如果是ShuffleDependency说明是宽依赖,详见4
case shufDep: ShuffleDependency[, , _] =>
parents += getShuffleMapStage(shufDep, firstJobId)
//是窄依赖
case _ =>
//遍历rdd的父RDD是否有父Stage存在
waitingForVisit.push(dep.rdd)
} } } }
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
//调用visit方法访问出栈的RDD
visit(waitingForVisit.pop())
}
parents.toList
}
4.getShuffleMapStage方法如下所示:
private def getShuffleMapStage(
shuffleDep: ShuffleDependency[, , _],
firstJobId: Int): ShuffleMapStage = {
shuffleToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) => stage
case None =>
// We are going to register ancestor shuffle dependencies,详见5
getAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
//根据firstJobId生成ShuffleMapStage,详见6
shuffleToMapStage(dep.shuffleId) = newOrUsedShuffleStage(dep, firstJobId)
}
// Then register current shuffleDep
val stage = newOrUsedShuffleStage(shuffleDep, firstJobId)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}
5.getAncestorShuffleDependencies方法如下:
private def getAncestorShuffleDependencies(rdd: RDD[_]): Stack[ShuffleDependency[, , _]] = {
val parents = new Stack[ShuffleDependency[, , _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
dep match {
case shufDep: ShuffleDependency[, , _] =>
if (!shuffleToMapStage.contains(shufDep.shuffleId)) {
parents.push(shufDep)
}
case _ =>
}
waitingForVisit.push(dep.rdd)
}
}
}
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents
}
6.newOrUsedShuffleStage方法如下所示,根据给定的RDD生成ShuffleMapStage,如果shuffleId对应的Stage已经存在与MapOutputTracker,那么number和位置输出的位置信息都可以从MapOutputTracker找到
private def newOrUsedShuffleStage(
shuffleDep: ShuffleDependency[, , _],
firstJobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
val numTasks = rdd.partitions.length
val stage = newShuffleMapStage(rdd, numTasks, shuffleDep, firstJobId, rdd.creationSite)
if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId)
val locs = MapOutputTracker.deserializeMapStatuses(serLocs)
for (i <- 0 until locs.length) {
stage.outputLocs(i) = Option(locs(i)).toList // locs(i) will be null if missing
}
stage.numAvailableOutputs = locs.count(_ != null)
} else {
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}
2.Stage描述
一个Stage是一组并行的tasks;一个Stage可以被多个Job共享;一些Stage可能没有运行所有的RDD的分区,比如first 和 lookup;Stage的划分是通过是否存在Shuffle为边界来划分的,Stage的子类有两个:ResultStage和ShuffleMapStage
对于窄依赖生成的是ResultStage,对于宽依赖生成的是ShuffleMapStage。当ShuffleMapStages执行完后,产生输出文件,等待reduce task去获取,同时,ShffleMapStages也可以通过DAGScheduler的submitMapStage方法独立作为job被提交
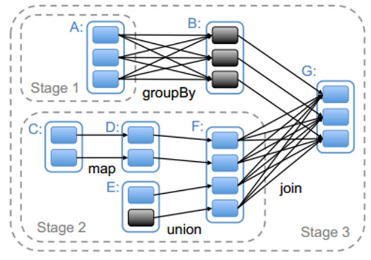
stage划分示意图
下一篇我们看Stage如何提交的。
【原】Spark中Job如何划分为Stage的更多相关文章
- 【Spark篇】--Spark中的宽窄依赖和Stage的划分
一.前述 RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖. Spark中的Stage其实就是一组并行的任务,任务是一个个的task . 二.具体细节 窄依赖 父RDD和子RDD parti ...
- 【原】Spark中Stage的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Job如何划分为Stage http://www.cnblogs.com/yourarebest/p/5342424.html 1 ...
- spark 中划分stage的思路
窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用,表现为 一个父RDD的分区对应于一个子RDD的分区 两个父RDD的分区对应于一个子RDD 的分区. 宽依赖指子RDD的每个分区都要依赖于父RD ...
- 【原】 Spark中Task的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Stage的提交 http://www.cnblogs.com/yourarebest/p/5356769.html Spark中 ...
- 【原】Spark中Job的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. Spark程序程序job的运行是通过actions算子触发的,每一个action算子其实是一个runJob方法的运行,详见文章 SparkContex源码 ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- 【原】 Spark中Worker源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Worker源码分析(一)http://www.cnblogs.com/yourarebest/p/5300202.html 4.receive方法, r ...
- Spark中Task,Partition,RDD、节点数、Executor数、core数目的关系和Application,Driver,Job,Task,Stage理解
梳理一下Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数.Executor数.core数目的关系. 输入可能以多个文件的形式存储在H ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
随机推荐
- Apache服务器部署ASP.NET网站
资源罗列: apache如何支持asp.net 用 Apache 发布 ASP.NET 网站
- PL/SQL — 集合及常用方法
PL/SQL中提供了常用的三种集合联合数组.嵌套表.变长数组,而对于这几个集合类型中元素的操作,PL/SQL提供了相应的函数或过程来操纵数组中的元素或下标.这些函数或过程称为集合方法.一个集合方法就是 ...
- uCGUI动态内存管理
动态内存的堆区 /* 堆区共用体定义 */ typedef union { /* 可以以4字节来访问堆区,也可以以1个字节来访问 */ ]; /* required for proper aligne ...
- 【intellij】异常信息汇总
Application Server was not connected before run configuration stop, reason: javax.management.Instanc ...
- Boost IPC Persistence Of Interprocess Mechanisms 例子
下面这一段摘抄自 Boost 1_55_0 的文档,显然标注了 每一个的生命期. One of the biggest issues with interprocess communication m ...
- userInteractionEnabled
NO -------是自身View下面的按钮之类的能点 YES------是View自身的按钮能点击,他下面的不能点击
- POJ3613 Cow Relays [矩阵乘法 floyd类似]
Cow Relays Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 7335 Accepted: 2878 Descri ...
- <六> jQuery 获得内容和属性
获得内容 三个简单实用的用于 DOM 操作的 jQuery 方法: text() - 设置或返回所选元素的文本内容 html() - 设置或返回所选元素的内容(包括 HTML 标记) val() - ...
- [Linux发行版] 常见Linux系统下载
本专题页汇总最受欢迎的Linux发行版基本介绍和下载地址,如果您是一位刚接触Linux的新手,这里的介绍可能对您有所帮助,如果您是以为Linux使用前辈,也可以在评论处留下您宝贵意见和经验,以便让更多 ...
- 浏览我的php网页时,出现的都是网页的代码
添加php模块 ,在apache/conf/httpd.conf,如果是windows下的话,添加如下代码,具体路径你根据具体情况设置#BEGIN PHP INSTALLER EDITS - REMO ...