写一个python 爬虫爬取百度电影并存入mysql中
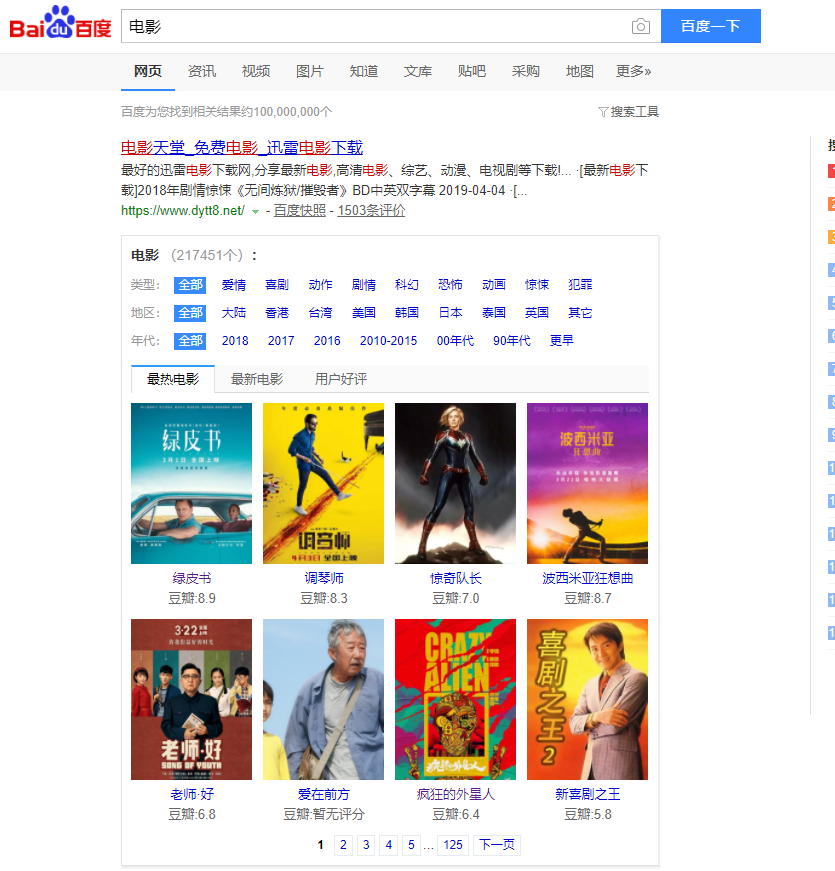
目标是利用python爬取百度搜索的电影
在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接
首先我们先在mysql中建表
create table liubo4(
id int not null auto_increment,
score VARCHAR(50) DEFAULT 0,
name VARCHAR(50) DEFAULT 0,
Pic VARCHAR(200) DEFAULT 0,
dianyingurl VARCHAR(200) DEFAULT 0,
leixing VARCHAR(50) DEFAULT 0,
niandai VARCHAR(50) DEFAULT 0,
diqu VARCHAR(50) DEFAULT 0,
PRIMARY KEY (id))
其中 图片地址列和电影地址列的 字段名要设置长一点 否则插入时不够,最好为每一列设置默认值。

我们在切换页数时会发现,浏览器地址栏中是没有变化的,这就使得无法直接用地址栏的url变化和xpath来获取标签进行爬取。
那么我们就用另外一种-----解析json字符串。
首先打开f12
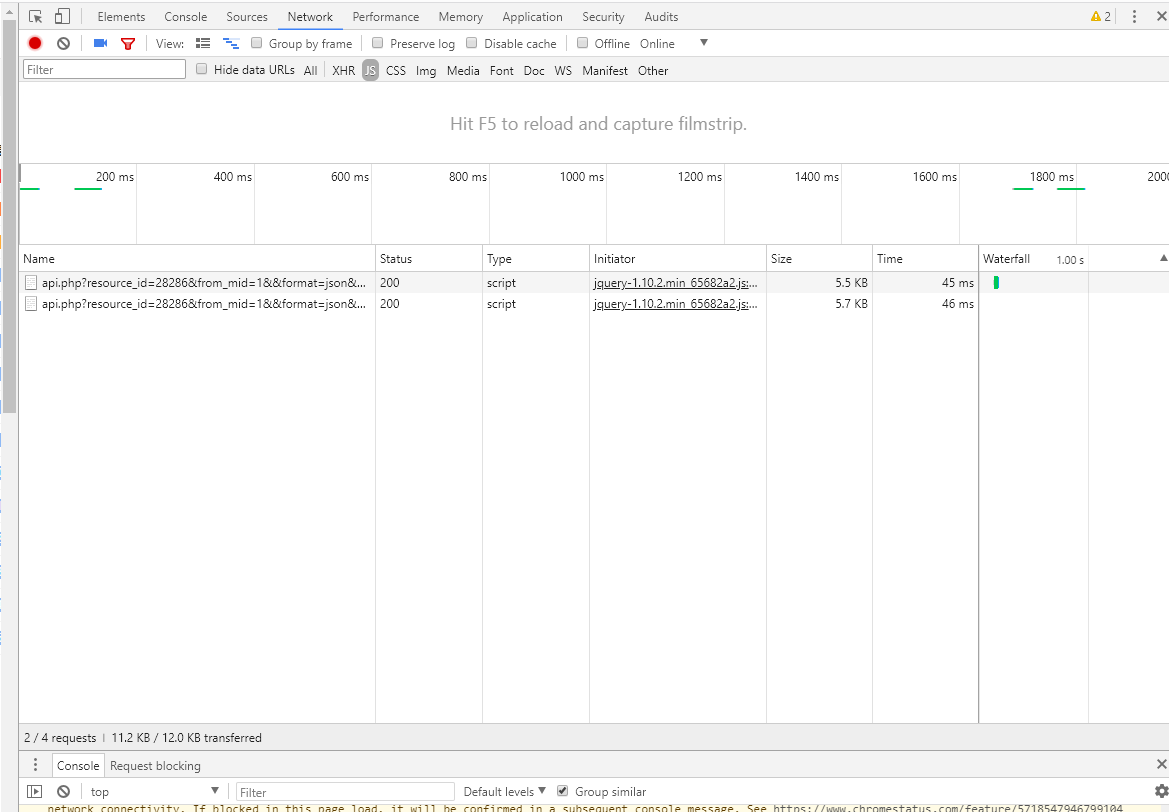


我们在切换页数时,会出现两个记录。
点开1.2两个行的行踪记录,能看到他们的Request URL
仔细看会发现这两个request的url主要不同在在于:第二页比第一页的pn多了8,那么我们就可以根据这个规律,在python中利用for 循环来请求125页的爬取。
找到了页面的规律,我们再去寻找具体的标签。
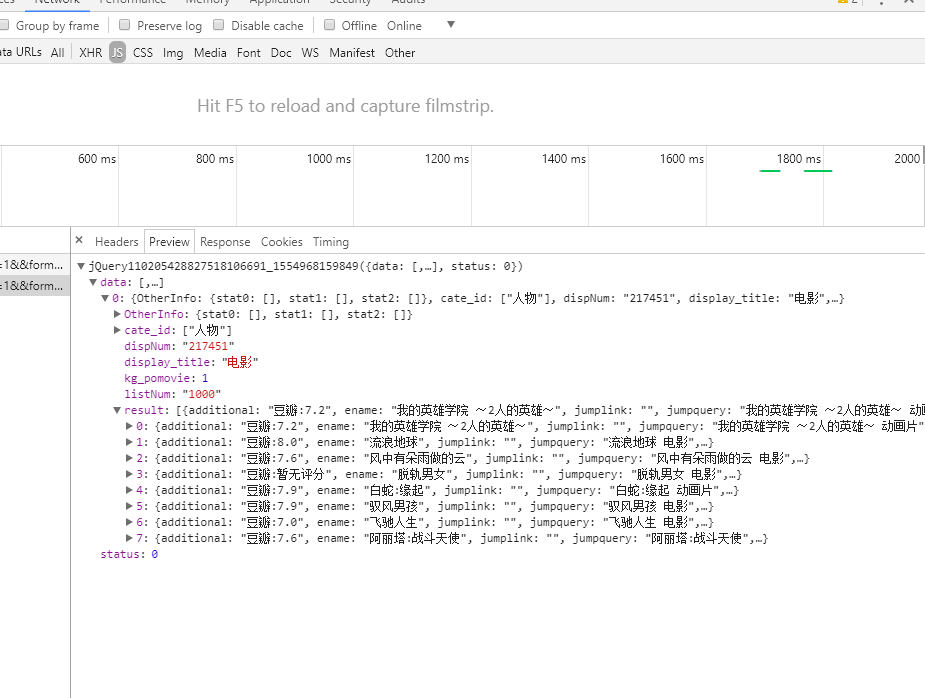
我们可以看到我们需要的 评分 名字 都被分别存放在 1.[data]-[result]-[additional] 2.[data]-[result]-[ename] 之中 。 而且每一页八部电影,分别被存在在result中的排序0-7。
那么图片url和电影url在哪呢 我们直接打开request url

在json字符串中 我们可以找到 picurl 而电影名字点开一部电影可以发现前部分的域名都是一样的 再加上不同的电影名字。
代码
import requests
import json
import re
import os
import pickle
import pymysql db = pymysql.connect('localhost', 'root', '', 'languid')连接mysql
urlbase = "https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28286&from_mid=1&&format=json&ie=utf-8&oe=utf-8&query=%E7%94%B5%E5%BD%B1&sort_key=16&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn="
urllist =[]
for i in range(1,125):
url = urlbase+str(8*i)
urllist.append(url) listxixi=[]
for uri in urllist:
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36)"}
response = requests.get(uri,headers=headers).text
json_str = json.loads(response) 解析json字符串
aa=json_str['data'][0]['result'][0]['additional']
bb=json_str['data'][0]['result'][0]['ename']
cc=json_str['data'][0]['result'][0]['kg_pic_url']
dd='https://www.baidu.com/s?rsv_idx=1&tn=44004473_1_oem_dg&wd='+json_str['data'][0]['result'][0]['ename']
listxixi.append([aa, bb, cc, dd])
cursor =db.cursor()
sql = "insert into liubo4(name,score,Pic,dianyingurl) Values(%s,%s,%s,%s)"#这里使用格式化字符串,用占位符
cursor.executemany(sql ,listxixi)
db.commit()
db.close()
这里使用insert语句中的 executemany 批量插入到mysql中 。首先要创建一个list 然后再插入mysql。
然后用第二种遍历commit 逐条提交
import requests
import json
import re
import os
import pickle
import pymysql db = pymysql.connect('localhost', 'root', '', 'languid')
urlbase = "https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28286&from_mid=1&&format=json&ie=utf-8&oe=utf-8&query=%E7%94%B5%E5%BD%B1&sort_key=16&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn="
urllist =[]
for i in range(1,124):
url = urlbase+str(8*i)
urllist.append(url)
for uri in urllist:
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36)"}
response = requests.get(uri,headers=headers).text
json_str = json.loads(response)
aa=json_str['data'][0]['result'][0]['additional']
bb=json_str['data'][0]['result'][0]['ename']
cc=json_str['data'][0]['result'][0]['kg_pic_url']
dd='https://www.baidu.com/s?rsv_idx=1&tn=44004473_1_oem_dg&wd='+json_str['data'][0]['result'][0]['ename']
cursor = db.cursor()
sql = "insert into liubo3(score,name,Pic,dianyingurl,leixing,niandai,diqu) VALUES ('%s','%s','%s','%s','犯罪','大陆','2016')" %(aa,bb,cc,dd)
cursor.execute(sql)
db.commit()
这里的标签中的类型、地区、年代是直接写死的 ,暂且没有找到好的办法去寻找规律。
附上一个用beautifulsoup简单爬取标签的代码
import requests
from bs4 import BeautifulSoup
import pymysql
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36)"}
url='https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=44004473_1_oem_dg&wd=%E7%94%B5%E5%BD%B1&rsv_pq=c30325e3000821d1&rsv_t=a23ejDCMhrNpbUK9fSZYvGt62pChqFxtcBIduHebPB%2BFDC%2BPosF8jTkgd1ZiL4KWiuTzBg5rtwY&rqlang=cn&rsv_enter=1&rsv_sug3=5&rsv_sug1=4&rsv_sug7=100'
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text,'lxml')
#xml = soup.find_all('p',class_='op_exactqa_tag_stat0')
#ddd = soup.find_all ('p',class_='op_exactqa_tag_stat1')
ccc = soup.find_all('p',class_='op_exactqa_tag_stat2')
leixin =[]
for name in ccc:
niandai=name.get_text()
db = pymysql.connect('localhost', 'root', '', 'languid')
cursor = db.cursor()
sql = "insert into liubo2(niandai)VALUES ('%s')"%(niandai)
cursor.execute(sql)
db.commit()
但是爬取到表中是整个list传入到表格,还没有学习透彻。
在整个爬虫制作过程中,学习网上爬取豆瓣电影的xpath办法失败了。
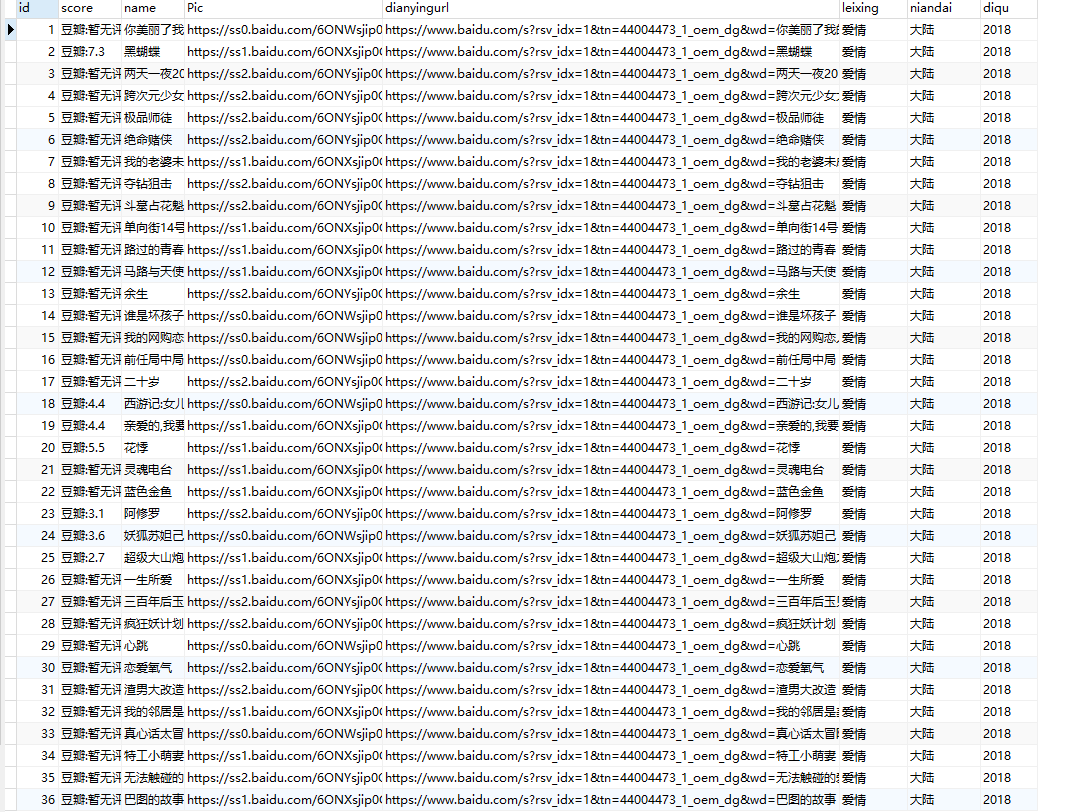
存入到mysql中的构架。
将爬取到的数据写入txt或者csv中
with open('wozuishuai5.txt', 'a+') as f:
f.write('\n'+aa+'\n'+bb+'\n'+cc+'\n'+dd)
写一个python 爬虫爬取百度电影并存入mysql中的更多相关文章
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- Python爬虫爬取百度贴吧的帖子
同样是参考网上教程,编写爬取贴吧帖子的内容,同时把爬取的帖子保存到本地文档: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urlli ...
- Python爬虫爬取百度贴吧的图片
根据输入的贴吧地址,爬取想要该贴吧的图片,保存到本地文件夹,仅供参考: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urllib2i ...
- python爬虫-爬取豆瓣电影数据
#!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:27# 文件 :spider_05.py# IDE :PyChar ...
- Python爬虫爬取百度翻译之数据提取方法json
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统 说明:本例为实现输入中文翻译为英文的小程序,适合Python爬虫的初学者一起学习,感兴趣的可以做英文翻译为中文的 ...
随机推荐
- Java 静态内部类的加载时机
参考文章:[https://www.cnblogs.com/maohuidong/p/7843807.html] 前言: 在看单例模式的时候,在网上找帖子看见其中有一种(IoDH) 实现单例的方式,其 ...
- springboot+shiro 一个项目部署多个,session名冲突问题
问题 前几天遇到一个比较奇怪的问题, 一个项目部署多个,端口不同.启动之后在同一浏览器中进行登录,后一个登录的会把前一个登录的挤掉,导致只能登录一个. 原因 是因为sessionid相同,然后修改了s ...
- synchronized和lock有什么区别?
一.原始构成 synchronized是关键字属于JVM层面,monitorenter(底层是通过monitor对象来完成,其实wait/notify等方法也依赖monitor对象只有在同步代码块和同 ...
- [算法]浅谈求n范围以内的质数(素数)
汗颜,数学符号表达今天才学会呀-_-# 下面是百度百科对质数的定义 质数(prime number)又称素数,有无限个. 质数定义为在大于1的自然数中,除了1和它本身以外不再有其他因数. 求质数的方法 ...
- python——redis
redis简介 redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sor ...
- 命令行中的python一行流
优点是比那些古怪的脚本要易读 python -c 'import os, sys; [os.rename(a, a[0].upper()+a[1:]) for a in sys.argv[1:]]' ...
- 常用API接口签名验证参考
项目中常用的API接口签名验证方法: 1. 给app分配对应的key.secret2. Sign签名,调用API 时需要对请求参数进行签名验证,签名方式如下: a. 按照请求参数名称将所有请求参数按照 ...
- win10更改无线网卡的MAC地址
https://blog.csdn.net/qq_31778495/article/details/80932472 前段时间电脑蹭网被禁了MAC地址,故寻找修改MAC地址的方法. 本机配置: win ...
- 处理 Vue 单页面应用 SEO
由于在vue单页应用中title只设定在入口文件index.html,如果切换路由,title怎么更换? 在路由router中设置meta: { path:'/chooseBrand', compon ...
- Apache Hadoop 2.9.2 的HDFS High Available模式部署
Apache Hadoop 2.9.2 的HDFS High Available 模式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道,当NameNode进程挂掉后,可 ...