Python爬虫爬取百度翻译之数据提取方法json
工具:Python 3.6.5、PyCharm开发工具、Windows 10 操作系统
说明:本例为实现输入中文翻译为英文的小程序,适合Python爬虫的初学者一起学习,感兴趣的可以做英文翻译为中文的功能,如单词查询功能等。推荐使用谷歌浏览器或火狐浏览器检查元素。使用之前需要先安装模块:pip install request pip install json。
数据提取方法:json
1、数据交换格式,看起来像Python类型(列表,字典)的字符串
2、使用json之前需要导入
3、json.loads
(1)、把json字符串转化为Python类型
(2)、json.loads(json字符串)
4、json.dumps
(1)、把Python类型转化为json字符串
(2)、json.dumps({})
(3)、json.dumps(ret1,ensure_ascii=False,indent=2)
ensure_ascii让中文显示成中文
indent:能够让下一行在上一行的基础上空格
代码:
import requests
import json
url = "https://fanyi.baidu.com/basetrans" query_str = input("请输入要翻译的中文:") data = {
"query":query_str,
"from":"zh",
"to":"en"} headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1", "Referer": "https://fanyi.baidu.com/?aldtype=16047&tpltype=sigma"
} response = requests.post(url,data=data,headers=headers) html_str = response.content.decode()#json字符串 #json数据交换格式,使用json之前需要导入
#把json字符串转化为Python类型
dict_ret = json.loads(html_str)
#print(dict_ret)
#print(type(dict_ret))
ret = dict_ret["trans"][0]["dst"]
print("翻译结果是:",ret)
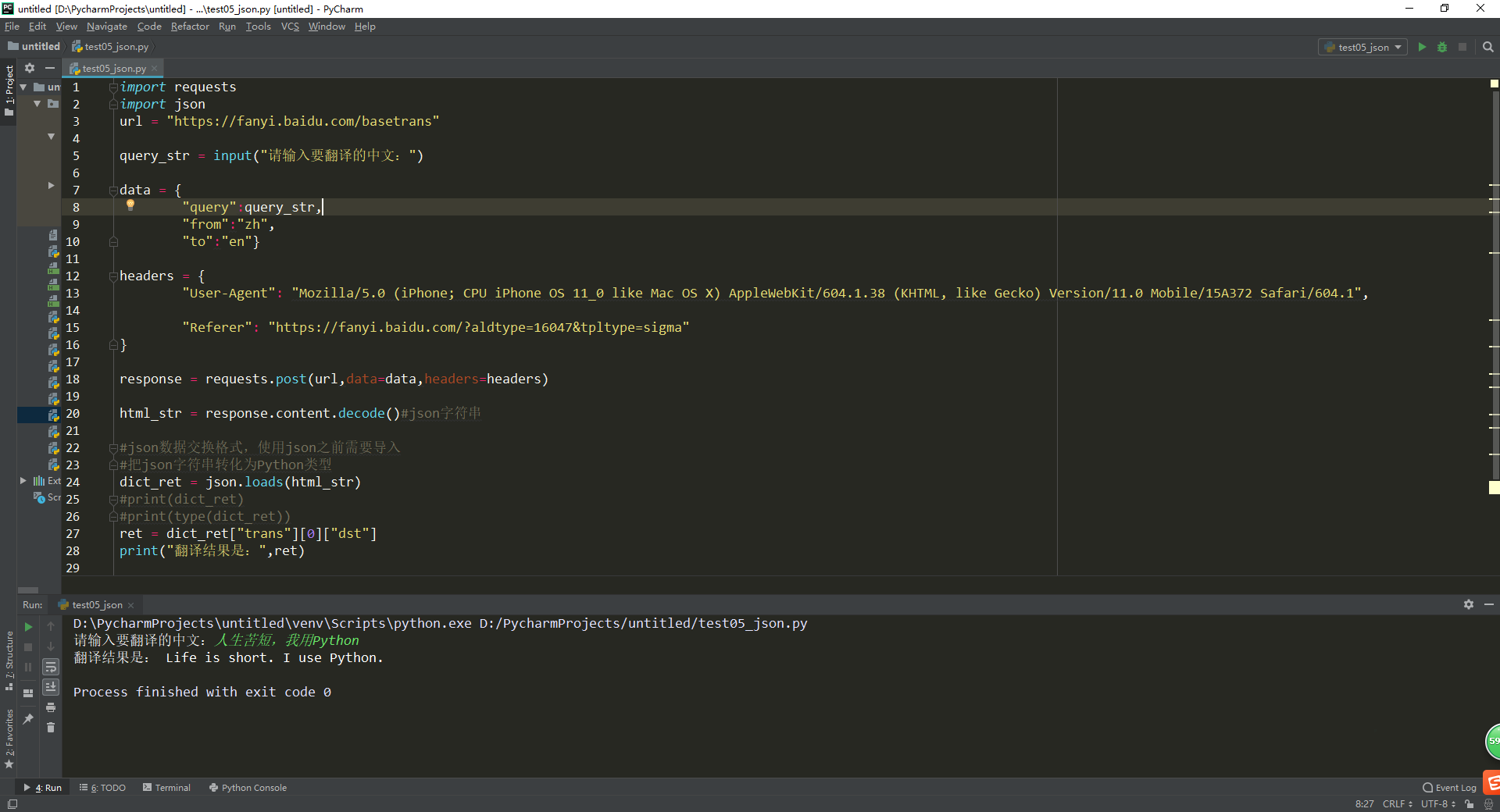
运行效果:
Python爬虫爬取百度翻译之数据提取方法json的更多相关文章
- python --爬虫--爬取百度翻译
import requestsimport json class baidufanyi: def __init__(self, trans_str): self.lang_detect_url = ' ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- Python爬虫爬取百度贴吧的帖子
同样是参考网上教程,编写爬取贴吧帖子的内容,同时把爬取的帖子保存到本地文档: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urlli ...
- Python爬虫爬取百度贴吧的图片
根据输入的贴吧地址,爬取想要该贴吧的图片,保存到本地文件夹,仅供参考: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urllib2i ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- Python爬虫-爬取百度贴吧帖子
这次主要学习了替换各种标签,规范格式的方法.依然参考博主崔庆才的博客. 1.获取url 某一帖子:https://tieba.baidu.com/p/3138733512?see_lz=1&p ...
随机推荐
- 什么是PDM?
PDM的含义 PDM的中文名称为产品数据管理(Product Data Management). PDM是一门用来管理所有与产品相关信息(包括零件信息.配置.文档.CAD文件.结构.权限信息等)和所有 ...
- HTTP协议安全头部X-Content-Type-Options引入的问题
前段时间测试MM反馈了一个问题,在富文本编辑器里上传的图片无法正常呈现.因为Jackie在本机的环境上没有观察类似的现象,而恰好那天测试环境的某个重要配项被改错了,于是Jackie想当然的归类为配置项 ...
- 基于CAS的SSO单点登录-实现ajax跨域访问的自动登录(也相当于超时重连)
先补课,以下网址可以把CAS环境搭起来. [JA-SIG CAS服务环境搭建]http://linliangyi2007.iteye.com/blog/165307 [JA-SIG CAS业务架构介绍 ...
- Linux --防火墙(一)
基本组成 表: filter:用来对数据包进行过滤,根据具体的规则要求决定如何处理一个数据包.表内包含三个链,即INOUT.FORWARD.OUTPUT nat表:主要用来修改数据包的IP地址.端口号 ...
- Android下最小化程序到后台代码
procedure TForm1.Button4Click(Sender: TObject); var Intent: JIntent; begin Intent := TJIntent. ...
- GCO团队合作
队名:GCO 队员: B20150304116谢冰媛 (组长) B20150304401王粲 B20150304115钟玺琛 B20150304226梁天海 ...
- 【转载】#440 - A Class Can Implement More than One Interface
It's possible for a class to implement more than one interface. For example, a Cow class might imple ...
- Android(java)学习笔记15:匿名内部类实现多线程
1. 使用匿名内部类实现多线程 二话不说,首先利用代码体现出来,给大家直观的感觉: package cn.itcast_11; /* 4 * 匿名内部类的格式: 5 * new 类名或者接口名() { ...
- c++一些总结
1.if和else if后面并没有要求一定要接else(即以else来结尾),可以直接if语句然后接其他语句,也可以if语句之后加else if语句再接其他语句
- ROS indigo安装完成后运行小乌龟示例程序
安装ROS成功后,在Beginner Tutorials中有一个简单的示例程序. 在Terminal中运行以下命令:$ roscore新开一个terminal,运行以下命令,打开小乌龟窗口:$ ros ...