SQL Server TVPs 批量插入数据
在SQL Server 中插入一条数据使用Insert语句,但是如果想要批量插入一堆数据的话,循环使用Insert不仅效率低,而且会导致SQL一系统性能问题。下面介绍SQL Server支持的两种批量数据插入方法:Bulk和表值参数(Table-Valued Parameters),高效插入数据。
新建数据库:
--Create DataBase
create database BulkTestDB;
go
use BulkTestDB;
go
--Create Table
Create table BulkTestTable(
Id int primary key,
UserName nvarchar(32),
Pwd varchar(16))
go
一.传统的INSERT方式
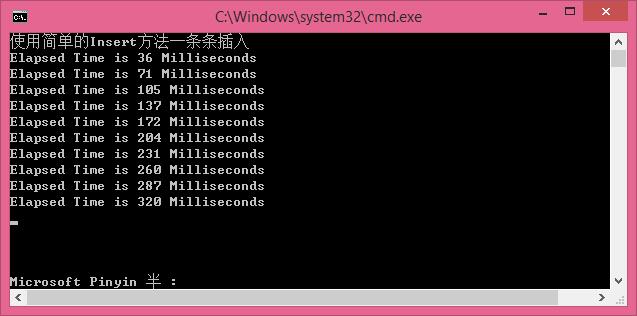
先看下传统的INSERT方式:一条一条的插入(性能消耗越来越大,速度越来越慢)
//使用简单的Insert方法一条条插入 [慢]
#region [ simpleInsert ]
static void simpleInsert()
{
Console.WriteLine("使用简单的Insert方法一条条插入");
Stopwatch sw = new Stopwatch();
SqlConnection sqlconn = new SqlConnection("server=.;database=BulkTestDB;user=sa;password=123456;");
SqlCommand sqlcmd = new SqlCommand();
sqlcmd.CommandText = string.Format("insert into BulkTestTable(Id,UserName,Pwd)values(@p0,@p1,@p2)");
sqlcmd.Parameters.Add("@p0", SqlDbType.Int);
sqlcmd.Parameters.Add("@p1", SqlDbType.NVarChar);
sqlcmd.Parameters.Add("@p2", SqlDbType.NVarChar);
sqlcmd.CommandType = CommandType.Text;
sqlcmd.Connection = sqlconn;
sqlconn.Open();
try
{
//循环插入1000条数据,每次插入100条,插入10次。
for (int multiply = ; multiply < ; multiply++)
{
for (int count = multiply * ; count < (multiply + ) * ; count++)
{ sqlcmd.Parameters["@p0"].Value = count;
sqlcmd.Parameters["@p1"].Value = string.Format("User-{0}", count * multiply);
sqlcmd.Parameters["@p2"].Value = string.Format("Pwd-{0}", count * multiply);
sw.Start();
sqlcmd.ExecuteNonQuery();
sw.Stop();
}
//每插入10万条数据后,显示此次插入所用时间
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
Console.ReadKey();
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}
#endregion
循环插入1000条数据,每次插入100条,插入10次,效率是越来越慢。
二.较快速的Bulk插入方式:
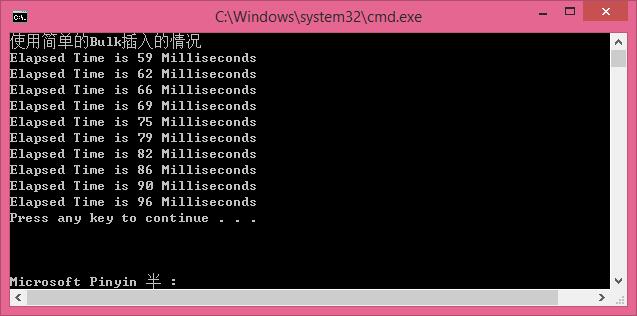
使用使用Bulk插入[ 较快 ]
//使用Bulk插入的情况 [ 较快 ]
#region [ 使用Bulk插入的情况 ]
static void BulkToDB(DataTable dt)
{
Stopwatch sw = new Stopwatch();
SqlConnection sqlconn = new SqlConnection("server=.;database=BulkTestDB;user=sa;password=123456;");
SqlBulkCopy bulkCopy = new SqlBulkCopy(sqlconn);
bulkCopy.DestinationTableName = "BulkTestTable";
bulkCopy.BatchSize = dt.Rows.Count;
try
{
sqlconn.Open();
if (dt != null && dt.Rows.Count != )
{
bulkCopy.WriteToServer(dt);
}
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
finally
{
sqlconn.Close();
if (bulkCopy != null)
{
bulkCopy.Close();
}
}
}
static DataTable GetTableSchema()
{
DataTable dt = new DataTable();
dt.Columns.AddRange(new DataColumn[] {
new DataColumn("Id",typeof(int)),
new DataColumn("UserName",typeof(string)),
new DataColumn("Pwd",typeof(string))
});
return dt;
}
static void BulkInsert()
{
Console.WriteLine("使用简单的Bulk插入的情况");
Stopwatch sw = new Stopwatch();
for (int multiply = ; multiply < ; multiply++)
{
DataTable dt = GetTableSchema();
for (int count = multiply * ; count < (multiply + ) * ; count++)
{
DataRow r = dt.NewRow();
r[] = count;
r[] = string.Format("User-{0}", count * multiply);
r[] = string.Format("Pwd-{0}", count * multiply);
dt.Rows.Add(r);
}
sw.Start();
BulkToDB(dt);
sw.Stop();
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
}
#endregion
循环插入1000条数据,每次插入100条,插入10次,效率快了很多。
三.使用简称TVPs插入数据
打开sqlserrver,执行以下脚本:
--Create Table Valued
CREATE TYPE BulkUdt AS TABLE
(Id int,
UserName nvarchar(32),
Pwd varchar(16)
)

成功后在数据库中发现多了BulkUdt的缓存表。
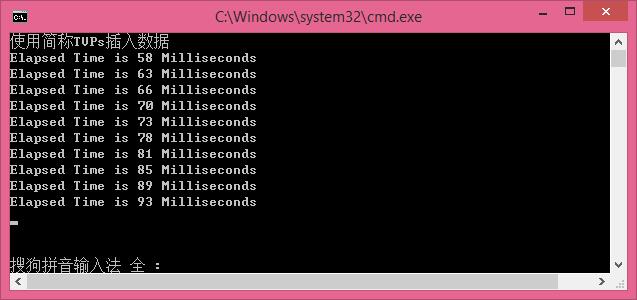
使用简称TVPs插入数据
//使用简称TVPs插入数据 [最快]
#region [ 使用简称TVPs插入数据 ]
static void TbaleValuedToDB(DataTable dt)
{
Stopwatch sw = new Stopwatch();
SqlConnection sqlconn = new SqlConnection("server=.;database=BulkTestDB;user=sa;password=123456;");
const string TSqlStatement =
"insert into BulkTestTable (Id,UserName,Pwd)" +
" SELECT nc.Id, nc.UserName,nc.Pwd" +
" FROM @NewBulkTestTvp AS nc";
SqlCommand cmd = new SqlCommand(TSqlStatement, sqlconn);
SqlParameter catParam = cmd.Parameters.AddWithValue("@NewBulkTestTvp", dt);
catParam.SqlDbType = SqlDbType.Structured;
catParam.TypeName = "dbo.BulkUdt";
try
{
sqlconn.Open();
if (dt != null && dt.Rows.Count != )
{
cmd.ExecuteNonQuery();
}
}
catch (Exception ex)
{
Console.WriteLine("error>" + ex.Message);
}
finally
{
sqlconn.Close();
}
}
static void TVPsInsert()
{
Console.WriteLine("使用简称TVPs插入数据");
Stopwatch sw = new Stopwatch();
for (int multiply = ; multiply < ; multiply++)
{
DataTable dt = GetTableSchema();
for (int count = multiply * ; count < (multiply + ) * ; count++)
{
DataRow r = dt.NewRow();
r[] = count;
r[] = string.Format("User-{0}", count * multiply);
r[] = string.Format("Pwd-{0}", count * multiply);
dt.Rows.Add(r);
}
sw.Start();
TbaleValuedToDB(dt);
sw.Stop();
Console.WriteLine(string.Format("Elapsed Time is {0} Milliseconds", sw.ElapsedMilliseconds));
}
Console.ReadLine();
}
#endregion
循环插入1000条数据,每次插入100条,插入10次,效率是越来越慢,后面测试,将每次插入的数据量增大,会更大的体现TPVS插入的效率。
PS:
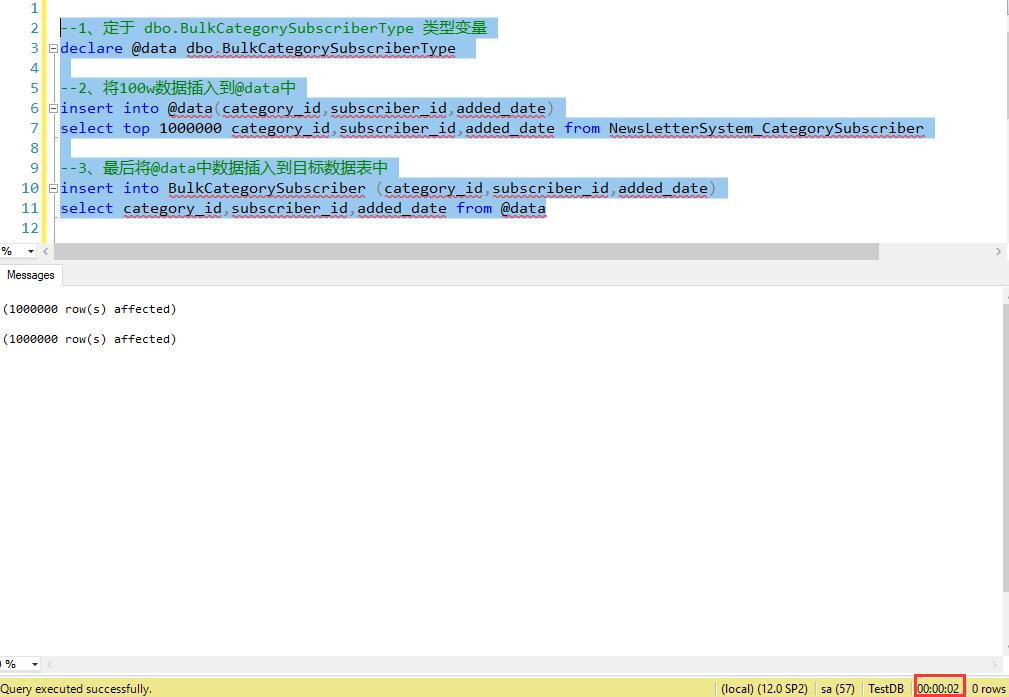
使用新特性TVPs插入100w数据 只需2秒,实例如下:
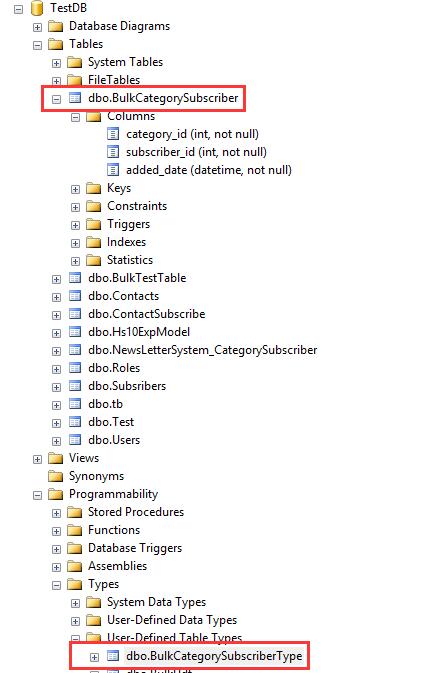
--创建表
CREATE TABLE BulkCategorySubscriber
(
[category_id] [int] NOT NULL,
[subscriber_id] [int] NOT NULL,
[added_date] [datetime] NOT NULL DEFAULT (getdate())
) --创建 type
--Create Table Valued
CREATE TYPE BulkCategorySubscriberType AS TABLE
(
[category_id] [int] NOT NULL,
[subscriber_id] [int] NOT NULL,
[added_date] [datetime] NOT NULL DEFAULT (getdate())
)
--1、定于 dbo.BulkCategorySubscriberType 类型变量
declare @data dbo.BulkCategorySubscriberType --2、将100w数据插入到@data中
insert into @data(category_id,subscriber_id,added_date)
select top 1000000 category_id,subscriber_id,added_date from NewsLetterSystem_CategorySubscriber --3、最后将@data中数据插入到目标数据表中
insert into BulkCategorySubscriber (category_id,subscriber_id,added_date)
select category_id,subscriber_id,added_date from @data
SQL Server TVPs 批量插入数据的更多相关文章
- SQL Server 2008 批量插入数据时报错
前几天在SQL Server 2008同步产品数据时,总是提示二进制文本被截断的错误,但是经过检查发现数据都符合格式要求. 百思不得其解,单独插入一条条数据则可以插入,但是批量导入则报错. 批量导入代 ...
- 使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历
原文:使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历 常常遇到需要向SQL Server插入批量数据,然后在存储过程中对这些数据进行进一步处理的情况.存储过 ...
- 使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历
使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历 原文:使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历 常常遇 ...
- 使用变量向SQL Server 2008中插入数据
QT通过ODBC连接数据库SQL Server 2008,进行数据插入时遇到的问题: 先把数据存入变量中,如何使用变量进行插入?插入语句该怎么写? QSqlQuery query(db); query ...
- SQL:数据库批量插入数据
测试中有些功能要求有足够的数据进行测试,当输入字段较多时通过页面添加很慢.业务只关联单个数据库表可以通过数据库批量插入数据 批量插入数据示例: declare @i int--声明变量 --变量初始化 ...
- 从TXT文本文档向Sql Server中批量导入数据
下面我们通过以下的简单的SQL语句即可实现数据的批量导入,代码如下: Bulk insert id From 'G:\文档\test.txt' With ( fieldterminator=',', ...
- sql server中批量插入与更新两种解决方案分享
若只是需要大批量插入数据使用bcp是最好的,若同时需要插入.删除.更新建议使用SqlDataAdapter我测试过有很高的效率,一般情况下这两种就满足需求了 bcp方式 复制代码 代码如下: /// ...
- SQL Server中批量替换数据
SQL Server数据库中批量替换数据的方法 SQL Server数据库操作中,我们可能会根据某写需要去批量替换数据,那么如何批量修改替换数据呢?本文我们就介绍这一部分内容,接下来就让我们一起来了解 ...
- sql server中批量插入与更新两种解决方案分享(存储过程)
转自http://www.shangxueba.com/jingyan/1940447.html 1.游标方式 SET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONG ...
随机推荐
- HTML基础-------HTML标签(1)
HTML标签(1) h系列(容器级双标签) h系列标签分为六个等级(h1,h2,h3,h4,h5,h6) 语义:给文本添加一个标题 标题重要程度逐级递减,一个页面只能有一个h1级的标签,并且大多数时候 ...
- JS去除掉字符串前后空格
1. 推荐使用jquery已封装好的方法,非常简单 $.trim(str) jquery的内部实现如下, function trim(str){ return str.replace(/^(\s|\u ...
- C++一些基本数据结构:字面常量、符号常量、枚举常量
常量:C++包括两种常量,字面常量和符号常量. 字面常量:指的是直接输入到程序中的值 比如:in myAge=26: myAge是一个int类型变量,而26是一个字面常量. 符号常量:指的是用名称表示 ...
- Android 获取验证码倒计时实现
Android 获取验证码倒计时实现 2017年10月24日 09:55:41 FBY展菲 阅读数:2002 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.cs ...
- python day08
ascii码转换成字符:ord(str) 字符串转换成ascii:chr(int) 三种字符串 1.普通字符串 --以字符作为输出单位 print(u'abc') 显示给用户看的字符串 2.二进制字符 ...
- 【续】5年后,我们为什么要从 Entity Framework 转到 Dapper 工具?
前言 上一篇文章收获了 140 多条评论,这是我们始料未及的. 向来有争议的话题都是公说公的理,婆说婆的理,Entity Framework的爱好者对此可以说是嗤之以鼻,不屑一顾,而Dapper爱好者 ...
- JS继承以及继承的几种实现方式总结
传统面向对象语言:继承是类与类之间的关系. 而在js中由于es6之前没有类的概念,所以继承是对象与对象之间的关系. 在js中,继承就是指使一个对象有权去访问另一个对象的能力. 比如:比如对象a能够访问 ...
- 2019-04-10 集成JasperReport
1. 报表的制作过程为 ① 制作.jrxml报表模板文件,并编译成.jasper ② 代码处理.jasper文件并填充数据进行输出 2. 一开始是打算使用iReport作为模板制作工具的,但是有以下局 ...
- react native 封装TextInput组件
上一篇 react-native文章提到了TextInput组件对安卓的适配问题,因此对该组件进行封装很有必要. 文章地址 react native定报预披项目知识点总结 TextInput介绍 官 ...
- [CIDR]calculate CIDR network capacity / 计算CIDR子网的网络容量
题目: 答案: 过程: 以B为例,192.168.9.140/27 /27 掩码是 8 8 8 111 00000 192.168.9.140是这个网段里的一个地址 140是 10001100 所以这 ...