A Neural Probabilistic Language Model (2003)论文要点
论文链接:http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
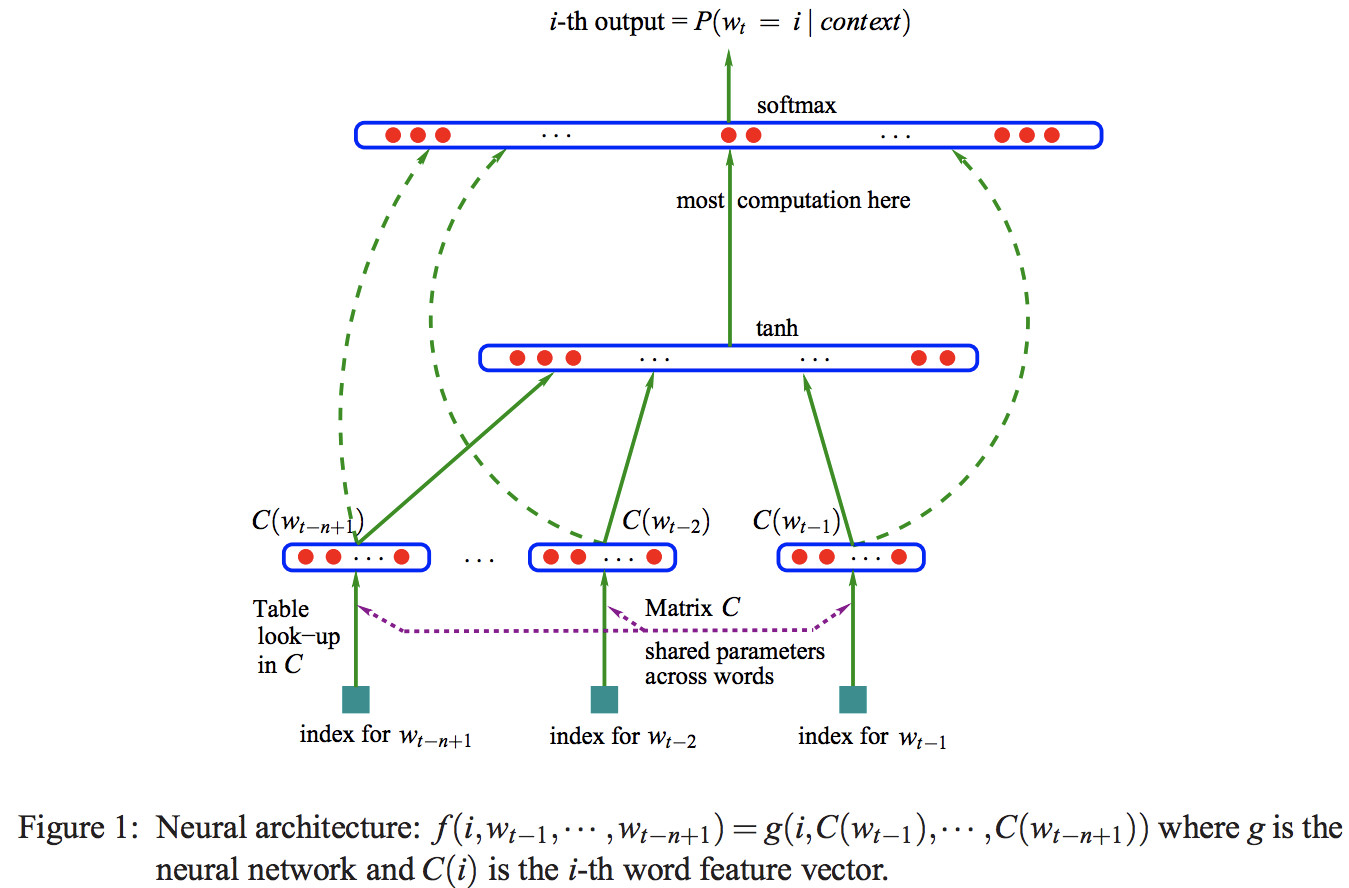
解决n-gram语言模型(比如tri-gram以上)的组合爆炸问题,引入词的分布式表示。
通过使得相似上下文和相似句子中词的向量彼此接近,因此得到泛化性。
相对而言考虑了n-gram没有的更多的上下文和词之间的相似度。
使用浅层网络(比如1层隐层)训练大语料。

feature vector维度通常在100以内,对比词典大小通常在17000以上。

C是全局共享的向量数组。
最大化正则log似然函数:
非归一化的log似然:

hidden units num = h
word feature vector dimension = m
context window width = n
output biases b: |V|
hidden layer biases d: h
hidden to output weights U: |V|*h
word feature vector to output weights W: |V|*(n-1)*m
hidden layer weights H: h*(n-1)*m
word reature vector group C: |V|*m
Note that in theory, if there is a weight decay on the weights W and H but not on C, then W and H could converge towards zero while C would blow up. In practice we did not observe such behavior when training with stochastic gradient ascent.
每次训练大部分参数不需要更新。
训练算法:



可改进点:
1. 分成子网络并行训练
2. 输出词典|V|改成树结构,预测每层的条件概率:计算量|V| -> log|V|
3. 梯度重视特别的样本,比如含有歧义词的样本
4. 引入先验知识(词性等)
5. 可解释性
6. 一词多义(一个词有多个词向量)
A Neural Probabilistic Language Model (2003)论文要点的更多相关文章
- A Neural Probabilistic Language Model
A Neural Probabilistic Language Model,这篇论文是Begio等人在2003年发表的,可以说是词表示的鼻祖.在这里给出简要的译文 A Neural Probabili ...
- pytorch ---神经网络语言模型 NNLM 《A Neural Probabilistic Language Model》
论文地址:http://www.iro.umontreal.ca/~vincentp/Publications/lm_jmlr.pdf 论文给出了NNLM的框架图: 针对论文,实现代码如下: # -* ...
- 从代码角度理解NNLM(A Neural Probabilistic Language Model)
其框架结构如下所示: 可分为四 个部分: 词嵌入部分 输入 隐含层 输出层 我们要明确任务是通过一个文本序列(分词后的序列)去预测下一个字出现的概率,tensorflow代码如下: 参考:https: ...
- Efficient Estimation of Word Representations in Vector Space (2013)论文要点
论文链接:https://arxiv.org/pdf/1301.3781.pdf 参考: A Neural Probabilistic Language Model (2003)论文要点 https ...
- NLP问题特征表达基础 - 语言模型(Language Model)发展演化历程讨论
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- 论文分享|《Universal Language Model Fine-tuning for Text Classificatio》
https://www.sohu.com/a/233269391_395209 本周我们要分享的论文是<Universal Language Model Fine-tuning for Text ...
- #论文阅读# Universial language model fine-tuing for text classification
论文链接:https://aclweb.org/anthology/P18-1031 对文章内容的总结 文章研究了一些在general corous上pretrain LM,然后把得到的model t ...
- 【论文翻译】KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships
KLMo:建模细粒度关系的知识图增强预训练语言模型 (KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Graine ...
- Recurrent Neural Network Language Modeling Toolkit代码学习
Recurrent Neural Network Language Modeling Toolkit 工具使用点击打开链接 本博客地址:http://blog.csdn.net/wangxingin ...
随机推荐
- 《Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization》课堂笔记
Lesson 2 Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization 这篇文章其 ...
- GCC 9.2 2019年8月12日 出炉啦
GNU 2019-08-12 发布了 GCC 9.2https://gcc.gnu.org/onlinedocs/9.2.0/ 有详细的说明 MinGW 上可用的 GCC 9.2 版本下载地址 [ m ...
- 给DBGrid动态赋值后,如何用程序指定某行某列为当前焦点?(100分)
哈哈,我弄出来了.在大富翁上搜索的.Form1.DBGrid1.SelectedIndex := 4;Form1.DBGrid1.SetFocus;这样就行了.谢谢你! --------------- ...
- Kafka集群安裝部署(自带Zookeeper)
kafka简介 kafka官网:http://kafka.apache.org/ kafka下载页面:http://kafka.apache.org/downloads kafka配置快速入门:htt ...
- Jmeter实现WebSocket协议的接口
1.下载websocket插件的jar包 网盘链接:https://pan.baidu.com/s/1FDcTHdQcDo6izgROMgB96w 密码:uags 该包下载完成后直接放在jmeter的 ...
- 利用fiddler+nginx模拟流量识别与转发
最近看到一些关于全链路压测的文章,全链路压测主要处理以下问题: 数据清洗压测流量标记,识别 压测流量标记的传递测试数据与线上数据隔离等等... 要实现全链路压测,必然要对原有的业务系统进行升级,要怎么 ...
- 从 SPIR-V 到 ISPC:将 GPU 计算转化为 CPU 计算
游戏行业越来越多地趋向于将计算工作转移到图形处理单元 (GPU) 中,导致引擎和/或工作室需要开发大量 GPU 计算着色器来处理不同的计算任务.但有时候在 CPU 上运行这些计算着色器非常方便,不必重 ...
- Android开发 所需组件配置
1 Unity中的Android Build Support下载 在Unity中的File>Building Settings>Android>Open Download Page, ...
- upload上传
1>使用apache第三方控件commons-fileupload实现上传(引入jar包),能够极大的简化实现上传文件的代码量 2>能够实现文件的上传功能,当我们的项目中需要上传图片,文档 ...
- Git_mergetool_tutorial(转载)
原文链接:https://gist.github.com/karenyyng/f19ff75c60f18b4b8149#table-of-content Table Of Content Skip t ...