HDFS中DataNode工作机制
1.DataNode工作机制
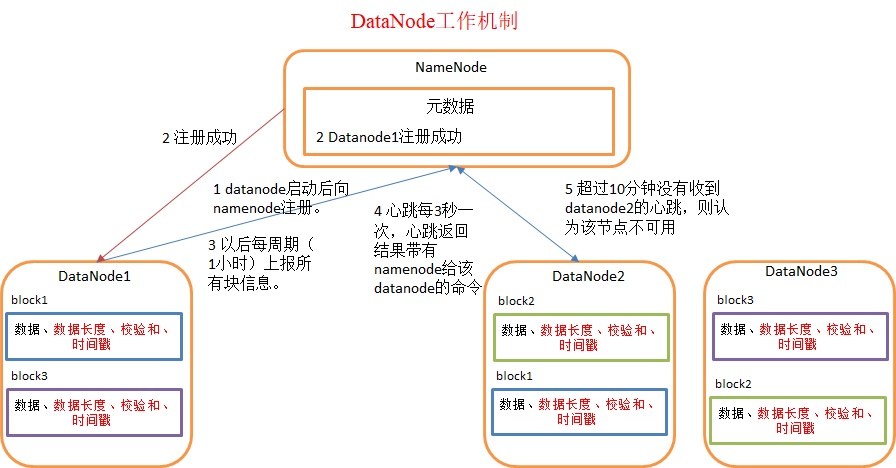
1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(包括数据块的长度,块数据的校验和,以及时间戳)。
2)DataNode启动后向namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器。
2.数据完整性
1)当DataNode读取block的时候,它会计算checksum
2)如果计算后的checksum,与block创建时值不一样,说明block已经损坏。
3)client读取其他DataNode上的block.
4)datanode在其文件创建后周期验证checksum
3.DataNode掉线时限参数设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
而默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name> dfs.heartbeat.interval </name>
<value>3</value>
</property>
1
)当DataNode读取block的时候,它会计算checksum
2)如果计算后的checksum,与block创建时值不一样,说明block已经损坏。
3)client读取其他DataNode上的block.
4)datanode在其文件创建后周期验证checksum
HDFS中DataNode工作机制的更多相关文章
- hdfs namenode/datanode工作机制
一. namenode工作机制 1. 客户端上传文件时,namenode先检查有没有同名的文件,如果有,则直接返回错误信息.如果没有,则根据要上传文件的大小以及block的大小,算出需要分成几个blo ...
- HDFS中NameNode工作机制
引言 NameNode: 存储元数据 管理整个HDFS集群 DataNode: 存储数据的block SecondaryNameNode: 辅助HDFS完成一些事情 NameNode和Secondar ...
- DataNode 工作机制
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_35641192/article/d ...
- Hadoop(五)—— HDFS NameNode、DataNode工作机制
一.NN与2NN工作机制 NameNode(NN) 1.当HDFS启动时,会加载日志(edits)和镜像文件(fsImage)到内存中. 2-4.当元数据的增删改查请求进来时,NameNode会先将操 ...
- HDFS中DataNode的心跳机制
DataNode心跳机制的作用讲解了DataNode的三个作用: register:当DataNode启动的时候,DataNode需要将自身的一些信息(hostname, version等)告诉Nam ...
- hdfs的datanode工作原理
datanode的作用: (1)提供真实文件数据的存储服务. (2)文件块(block):最基本的存储单位.对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序 ...
- Hadoop_10_HDFS 的 DataNode工作机制
1.DataNode的工作机制: 1.DataNode工作职责:存储管理用户的文件块数据 定期向namenode汇报自身所持有的block信息(通过心跳信息上报) (这点很重要,因为,当集群中发生某 ...
- Hadoop框架:DataNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.工作机制 1.基础描述 DataNode上数据块以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是数据块元数据包括长度.校验.时 ...
- HDFS成员的工作机制
NameNode工作机制 nn负责管理块的元数据信息,元数据信息为fsimage和edits预写日志,通过edits预写日志来更新fsimage中的元数据信息,每次namenode启动时,都会将磁盘中 ...
随机推荐
- amazon-aws 使用 SNS 发送短信
jar-maven <!-- https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-sns --> <depen ...
- 组件通信 $ref
(1)放在dom上表示获取当前dom元素, (2)放到组件上表示获取当前组件实例 (3)在v-for中获取的是集合 <!DOCTYPE html> <html lang=" ...
- 用C语音编写python的扩展模块,也就是python调c库
用C语音编写python的扩展模块,也就是python调c库 1.用C语言扩展Python的功能: http://www.ibm.com/developerworks/cn/linux/l-pyt ...
- linux C++ 通讯架构(一)nginx安装、目录、进程模型
nginx是C语言开发的,号称并发处理百万级别的TCP连接,稳定,热部署(运行时升级),高度模块化设计,可以用C++开发. 一.安装和目录 1.1 前提 epoll,linux内核版本为2.6或以上 ...
- 利用Django框架实现分页 demo
- 2,ActiveMQ-入门
ActiveMQ是Apache出品的,非常流行的消息中间件,可以说要掌握消息中间件,需要从ActiveMQ开始.首先去官网下载:ActiveMQ官网 一,ActiveMQ目录配置文件 1.1,Acti ...
- 牛飞盘队Cow Frisbee Team
老唐最近迷上了飞盘,约翰想和他一起玩,于是打算从他家的N头奶牛中选出一支队伍. 每只奶牛的能力为整数,第i头奶牛的能力为R i .飞盘队的队员数量不能少于 .大于N. 一支队伍的总能力就是所有队员能力 ...
- codevs 2039 骑马修栅栏 USACO x
题目描述 Description Farmer John每年有很多栅栏要修理.他总是骑着马穿过每一个栅栏并修复它破损的地方. John是一个与其他农民一样懒的人.他讨厌骑马,因此从来不两次经过一个栅栏 ...
- rf-idf的java实现
还存在的问题是,对于其中分词借助的库还存在问题 参考此篇链接 http://www.cnblogs.com/ywl925/archive/2013/08/26/3275878.html 具体代码部分: ...
- iOS Beta 升级或降级
https://sspai.com/post/45442 public beta网站上安装profile, 去手机看更新 developer beta, 登录开发者网站, downloads, 下载p ...