HDFS中DataNode工作机制
1.DataNode工作机制
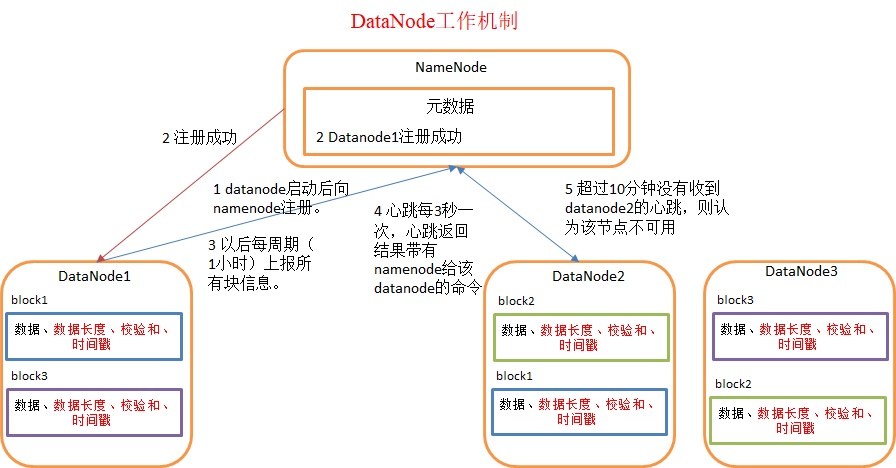
1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(包括数据块的长度,块数据的校验和,以及时间戳)。
2)DataNode启动后向namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器。
2.数据完整性
1)当DataNode读取block的时候,它会计算checksum
2)如果计算后的checksum,与block创建时值不一样,说明block已经损坏。
3)client读取其他DataNode上的block.
4)datanode在其文件创建后周期验证checksum
3.DataNode掉线时限参数设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
而默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name> dfs.heartbeat.interval </name>
<value>3</value>
</property>
1
)当DataNode读取block的时候,它会计算checksum
2)如果计算后的checksum,与block创建时值不一样,说明block已经损坏。
3)client读取其他DataNode上的block.
4)datanode在其文件创建后周期验证checksum
HDFS中DataNode工作机制的更多相关文章
- hdfs namenode/datanode工作机制
一. namenode工作机制 1. 客户端上传文件时,namenode先检查有没有同名的文件,如果有,则直接返回错误信息.如果没有,则根据要上传文件的大小以及block的大小,算出需要分成几个blo ...
- HDFS中NameNode工作机制
引言 NameNode: 存储元数据 管理整个HDFS集群 DataNode: 存储数据的block SecondaryNameNode: 辅助HDFS完成一些事情 NameNode和Secondar ...
- DataNode 工作机制
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_35641192/article/d ...
- Hadoop(五)—— HDFS NameNode、DataNode工作机制
一.NN与2NN工作机制 NameNode(NN) 1.当HDFS启动时,会加载日志(edits)和镜像文件(fsImage)到内存中. 2-4.当元数据的增删改查请求进来时,NameNode会先将操 ...
- HDFS中DataNode的心跳机制
DataNode心跳机制的作用讲解了DataNode的三个作用: register:当DataNode启动的时候,DataNode需要将自身的一些信息(hostname, version等)告诉Nam ...
- hdfs的datanode工作原理
datanode的作用: (1)提供真实文件数据的存储服务. (2)文件块(block):最基本的存储单位.对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序 ...
- Hadoop_10_HDFS 的 DataNode工作机制
1.DataNode的工作机制: 1.DataNode工作职责:存储管理用户的文件块数据 定期向namenode汇报自身所持有的block信息(通过心跳信息上报) (这点很重要,因为,当集群中发生某 ...
- Hadoop框架:DataNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.工作机制 1.基础描述 DataNode上数据块以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是数据块元数据包括长度.校验.时 ...
- HDFS成员的工作机制
NameNode工作机制 nn负责管理块的元数据信息,元数据信息为fsimage和edits预写日志,通过edits预写日志来更新fsimage中的元数据信息,每次namenode启动时,都会将磁盘中 ...
随机推荐
- RestTemplate 超级严重BUG之 restTemplate.getForEntity对于下载文件的地址请求 header不起作用
错误下载:RestTemplate restTemplate=new RestTemplate();HttpHeaders httpHeaders=new HttpHeaders();httpHead ...
- POJ1523 SPF 单点故障
POJ1523 题意很简单,求删除割点后原先割点所在的无向连通图被分成了几个连通部分(原题说prevent at least one pair of available nodes from bein ...
- Spring Cloud(1)相关概念
单点系统架构 传统项目架构 传统项目分为三层架构,将业务逻辑层.数据库访问层.控制层放入在一个项目中. 优点:适合于个人或者小团队开发,不适合大团队开发. 分布式项目架构 根据业务需求进行拆分成N个子 ...
- LeetCode--078--子集(python)
给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集). 说明:解集不能包含重复的子集. 示例: 输入: nums = [1,2,3]输出:[ [3], [1], [2], ...
- linux运维、架构之路-python2.6升级3.6
一.环境 1.系统 [root@m01 ~]# cat /etc/redhat-release CentOS release 6.9 (Final) [root@m01 ~]# uname -r -. ...
- iOS - 图片的显示模式
- php shuffle()函数 语法
php shuffle()函数 语法 作用:把数组中的元素按随机顺序重新排序:富瑞华 语法:shuffle(array) 参数: 参数 描述 array 必需.规定要使用的数组. 说明:若成功则返回 ...
- sh_05_超市买苹果
sh_05_超市买苹果 # 1. 定义苹果的单价 price = 8.5 # 2. 挑选苹果 weight = 7.5 # 3. 计算付款金额 money = weight * price # 4. ...
- 【BZOJ2460】元素(拟阵)
题意:给定n个物品,每个物品有属性x和价值y,要求从中选出一些使得价值和最大并且其中没有属性xor和为0的非空子集 n<=1000,x<=1e18,y<=1e4 思路:没有xor和为 ...
- Java 统计单词频数
输出单个文件中的 N 个英语单词出现的次数 定义双列集合,将单词不重复的读入一列中,另一列用来计数 import java.io.BufferedReader; import java.util.Ar ...