Hadoop中的排序和连接
MapReduce的全排序
主要是为了保证分区排序,即第一个分区的最后一个Key值小于第二个分区的第一个Key值
与普通的排序仅仅多一个自定义分区类MyPartitioner见自己所写的实验
(设置一个reducer任务也行,但是并行度不高)
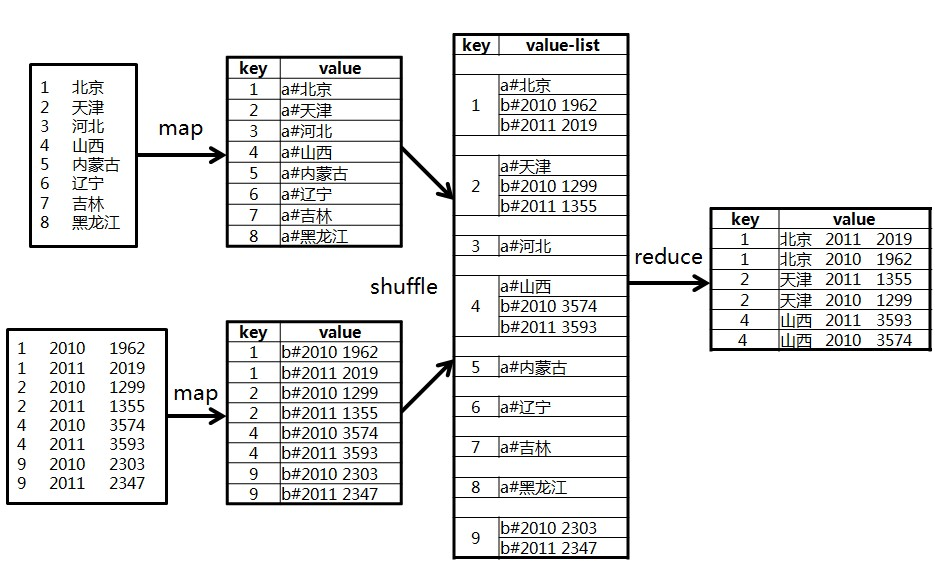
MapReduce的辅助排序
https://www.cnblogs.com/asker009/p/10412970.html
https://blog.csdn.net/eyeofeagle/article/details/82826747
MapReduce表连接操作之Map端join
https://blog.csdn.net/lzm1340458776/article/details/42971075
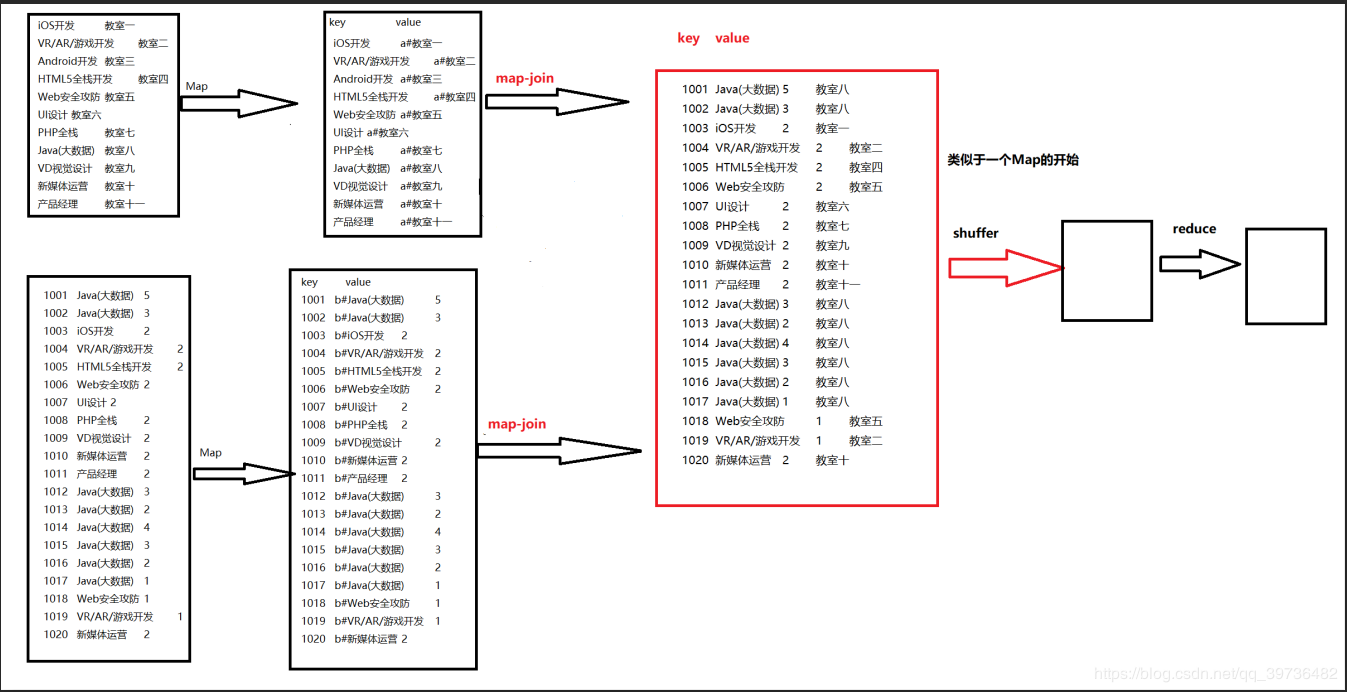
MapReduce表连接操作之Reduce端join
https://blog.csdn.net/lzm1340458776/article/details/42971485
MapReduce表连接之半连接SemiJoin
https://blog.csdn.net/lzm1340458776/article/details/43017425
PS:hadoop中的MapReduce框架里已经预定义了相关的接口,其中如Mapper类下的方法setup()和cleanup()。
- setup(),此方法被MapReduce框架仅且执行一次,在执行Map任务前,进行相关变量或者资源的集中初始化工作。若是将资源初始化工作放在方法map()中,导致Mapper任务在解析每一行输入时都会进行资源初始化工作,导致重复,程序运行效率不高!
- cleanup(),此方法被MapReduce框架仅且执行一次,在执行完毕Map任务后,进行相关变量或资源的释放工作。若是将释放资源工作放入方法map()中,也会导致Mapper任务在解析、处理每一行文本后释放资源,而且在下一行文本解析前还要重复初始化,导致反复重复,程序运行效率不高!
所以,建议资源初始化及释放工作,分别放入方法setup()和cleanup()中进行
Hadoop中的排序和连接的更多相关文章
- Hadoop中的各种排序
本篇博客是金子在学习hadoop过程中的笔记的整理,不论看别人写的怎么好,还是自己边学边做笔记最好了. 1:shuffle阶段的排序(部分排序) shuffle阶段的排序可以理解成两部分,一个是对sp ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- 2 weekend110的hadoop的自定义排序实现 + mr程序中自定义分组的实现
我想得到按流量来排序,而且还是倒序,怎么达到实现呢? 达到下面这种效果, 默认是根据key来排, 我想根据value里的某个排, 解决思路:将value里的某个,放到key里去,然后来排 下面,开始w ...
- Hadoop日记Day18---MapReduce排序分组
本节所用到的数据下载地址为:http://pan.baidu.com/s/1bnfELmZ MapReduce的排序分组任务与要求 我们知道排序分组是MapReduce中Mapper端的第四步,其中分 ...
- Hadoop中两表JOIN的处理方法(转)
1. 概述 在传统数据库(如:MYSQL)中,JOIN操作是非常常见且非常耗时的.而在HADOOP中进行JOIN操作,同样常见且耗时,由于Hadoop的独特设计思想,当进行JOIN操作时,有一些特殊的 ...
- [大牛翻译系列]Hadoop(1)MapReduce 连接:重分区连接(Repartition join)
4.1 连接(Join) 连接是关系运算,可以用于合并关系(relation).对于数据库中的表连接操作,可能已经广为人知了.在MapReduce中,连接可以用于合并两个或多个数据集.例如,用户基本信 ...
- Hadoop中两表JOIN的处理方法
Dong的这篇博客我觉得把原理写的很详细,同时介绍了一些优化办法,利用二次排序或者布隆过滤器,但在之前实践中我并没有在join中用二者来优化,因为我不是作join优化的,而是做单纯的倾斜处理,做joi ...
- hadoop中MapReduce多种join实现实例分析
转载自:http://zengzhaozheng.blog.51cto.com/8219051/1392961 1.在Reudce端进行连接. 在Reudce端进行连接是MapReduce框架进行表之 ...
- Hadoop中客户端和服务器端的方法调用过程
1.Java动态代理实例 Java 动态代理一个简单的demo:(用以对比Hadoop中的动态代理) Hello接口: public interface Hello { void sayHello(S ...
随机推荐
- Android中对Apk加固(加壳)续篇之---对Native层(so文件)进行加固
有人说Android程序用Java代码写的,再怎么弄都是不安全的,很容易破解的,现在晚上关于应用加固的技术也很多了,当然这些也可以用于商业发展的,梆梆加密和爱加密就是很好的例子,当然这两家加固的Apk ...
- Oracle dmp文件(表)导入与导出
dmp文件是作为oracle导入和导出表使用的文件格式dmp文件导出dmp文件导出用的比较多的一般是三种,他们分别是:1.导出整个数据库实例下的所有数据2.导出指定用户的所有表3.导出指定表. 打开命 ...
- Android 一键分享功能简单实现
import java.io.File;import java.util.ArrayList;import java.util.List; import android.content.Context ...
- mac的jvm调优工具
安装好JDK之后调优工具所在位置为: /System/Library/Frameworks/JavaVM.framework/Versions/Current/Commands/jvisualvm j ...
- php面试专题---13、AJAX基础内容考点
php面试专题---13.AJAX基础内容考点 一.总结 一句话总结: ajax对提升用户速度,缓解服务器压力方面也是很有可取之处的,毕竟传递的数据少了 1.AJAX基础概念? Asynchronou ...
- R python在无图形用户界面时保存图片
在用python的matplotlib,和R中自带的作图,如果想保存图片时,当你有图形用户界面时是没有问题的,但是当没有图形用户界面时,会报错: 在R中,解决办法: https://blog.csdn ...
- vue全局自定义指令-元素拖拽
小白我用的是vue-cli的全家桶,在标签中加入v-drap则实现元素拖拽, 全局指令我是写在main.js中 Vue.directive('drag', { inserted: function ( ...
- java.lang.IllegalArgumentException: object is not an instance of declaring class新发现
文章目录 背景 报错 解决 引申 背景 因为要将方法缓存起来提高性能 报错 java.lang.IllegalArgumentException: object is not an instance ...
- 学习:多项式算法----FWT
FWT也称快速沃尔什变换,是用来求多项式之间位运算的系数的.FWT的思想与FFT有异曲同工之妙,但较FFT来说,FWT比较简单. 前言 之前学习FFT(快速傅里叶变换)的时候,我们知道FFT是用来快速 ...
- 洛谷P3379 【模板】最近公共祖先(LCA)——LCA
给一手链接 https://www.luogu.com.cn/problem/P3379 算是lca的模板吧 #include<cstdio> #include<cstring> ...