如何利用 JuiceFS 的性能工具做文件系统分析和调优
JuiceFS 是一款面向云原生环境设计的高性能 POSIX 文件系统,在 AGPL v3.0 开源协议下发布。作为一个云上的分布式文件系统,任何存入 JuiceFS 的数据都会按照一定规则拆分成数据块存入对象存储(如 Amazon S3),相对应的元数据则持久化在独立的数据库中。这种结构决定了 JuiceFS 的存储空间可以根据数据量弹性伸缩,可靠地存储大规模的数据,同时支持在多主机之间共享挂载,实现跨云跨地区的数据共享和迁移。
从 v0.13 发布以来, JuiceFS 新增了多项与性能监测和分析相关的功能,从某种程度上说,开发团队希望 JuiceFS 既能提供大规模分布式计算场景下的出色性能,也能广泛地覆盖更多日常的使用场景。
本文我们从单机应用入手,看依赖单机文件系统的应用是否也可以用在 JuiceFS 之上,并分析它们的访问特点进行针对性的调优。
测试环境
接下来的测试我们会在同一台亚马逊云服务器上进行,配置情况如下:
- 服务器配置:Amazon c5d.xlarge: 4 vCPUs, 8 GiB 内存, 10 Gigabit 网络, 100 GB SSD
- JuiceFS:使用本地自建的 Redis 作为元数据引擎,对象存储使用与服务器相同区域的 S3。
- EXT4:直接在本地 SSD 上创建
- 数据样本:使用 Redis 的源代码作为测试样本
测试项目一:Git
常用的 git 系列命令有 clone、status、add、diff 等,其中 clone 与编译操作类似,都涉及到大量小文件写。这里我们主要测试 status 命令。
分别将代码克隆到本地的 EXT4 和 JuiceFS,然后执行 git status 命令的耗时情况如下:
- Ext4:0m0.005s
- JuiceFS:0m0.091s
可见,耗时出现了数量级的差异。如果单从测试环境的样本来说,这样的性能差异微乎其微,用户几乎是察觉不到的。但如果使用规模更大的代码仓库时,二者的性能差距就会逐渐显现。例如,假设两者耗时都乘以 100 倍,本地文件系统需要约 0.5s,尚在可接受范围内;但 JuiceFS 会需要约 9.1s,用户已能感觉到明显的延迟。为搞清楚主要的耗时点,我们可以使用 JuiceFS 客户端提供的 profile 工具:
$ juicefs profile /mnt/jfs
在分析过程中,更实用的方式是先记录日志,再用回放模式:
$ cat /mnt/jfs/.accesslog > a.log
# 另一个会话:git status
# Ctrl-C 结束 cat
$ juicefs profile --interval 0 a.log
结果如下:

这里可以清楚地看到有大量的 lookup 请求,我们可以通过调整 FUSE 的挂载参数来延长内核中元数据的缓存时间,比如使用以下参数重新挂载文件系统:
$ juicefs mount -d --entry-cache 300 localhost /mnt/jfs
然后我们再用 profile 工具分析,结果如下:
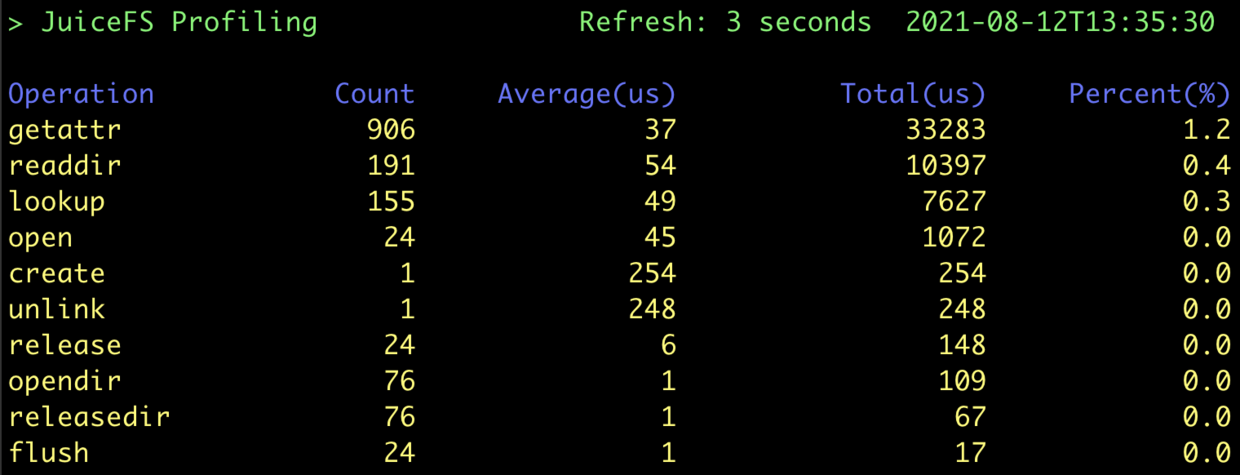
可以看到,lookup 请求减少了很多,但都转变成了 getattr 请求,因此还需要属性的缓存:
$ juicefs mount -d --entry-cache 300 --attr-cache 300 localhost /mnt/jfs
此时测试发现 status 命令耗时下降到了 0m0.034s,profile 工具结果如下:
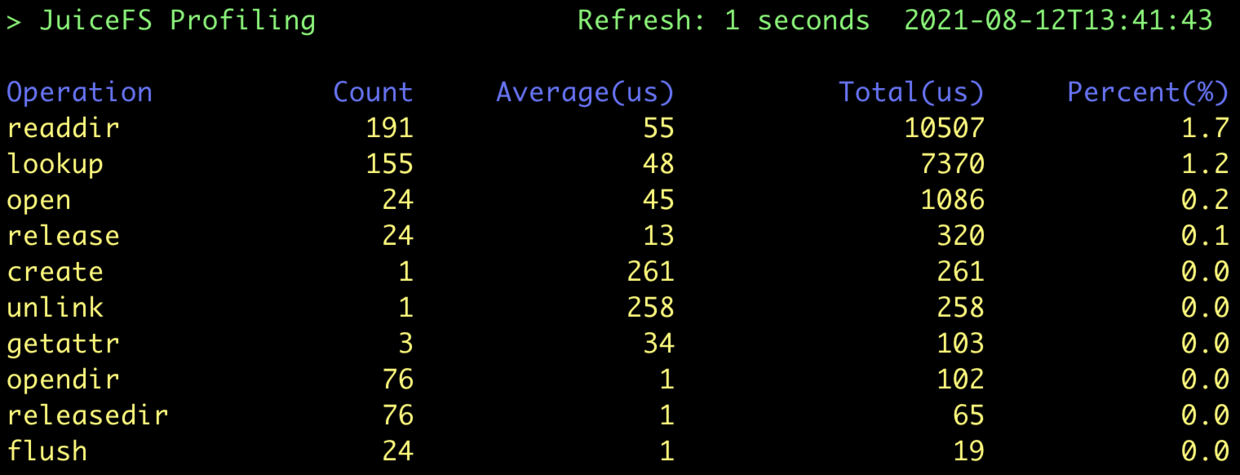
可见一开始最耗时的 lookup 已经减少了很多,而 readdir 请求变成新的瓶颈点。我们还可以尝试设置 --dir-entry-cache,但提升可能不太明显。
测试项目二:Make
大型项目的编译时间往往需要以小时计,因此编译时的性能显得更加重要。依然以 Redis 项目为例,测试编译的耗时为:
- Ext4:0m29.348s
- JuiceFS:2m47.335s
我们尝试调大元数据缓存参数,整体耗时下降约 10s。通过 profile 工具分析结果如下:
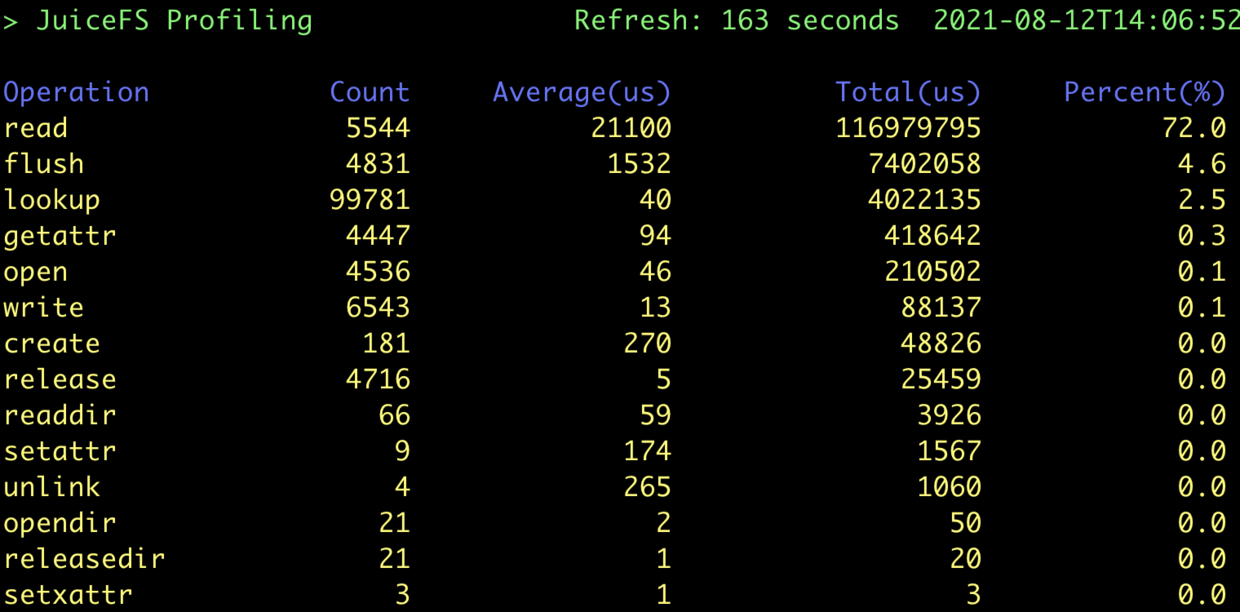
显然这里的数据读写是性能关键,我们可以使用 stats 工具做进一步的分析:
$ juicefs stats /mnt/jfs
其中一段结果如下:
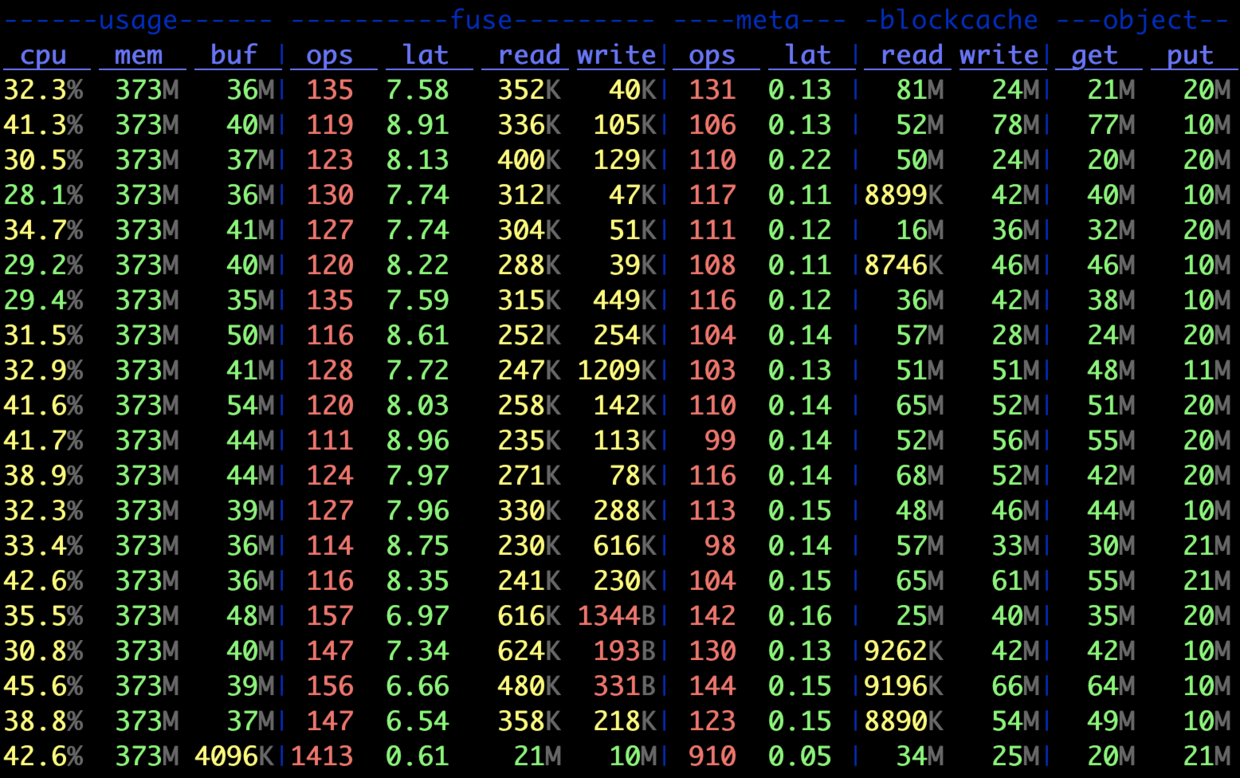
从上图可见 fuse 的 ops 与 meta 接近,但平均 latency 远大于 meta,因此可以判断出主要的瓶颈点在对象存储侧。不难想象,编译前期产生了大量的临时文件,而这些文件又会被编译的后几个阶段读取,以通常对象存储的性能很难直接满足要求。好在 JuiceFS 提供了数据 writeback 模式,可以在本地盘上先建立写缓存,正好适用于编译这种场景:
$ juicefs mount -d --entry-cache 300 --attr-cache 300 --writeback localhost /mnt/jfs
此时编译总耗时下降到 0m38.308s,已经与本地盘非常接近了。后阶段的 stats 工具监控结果如下:
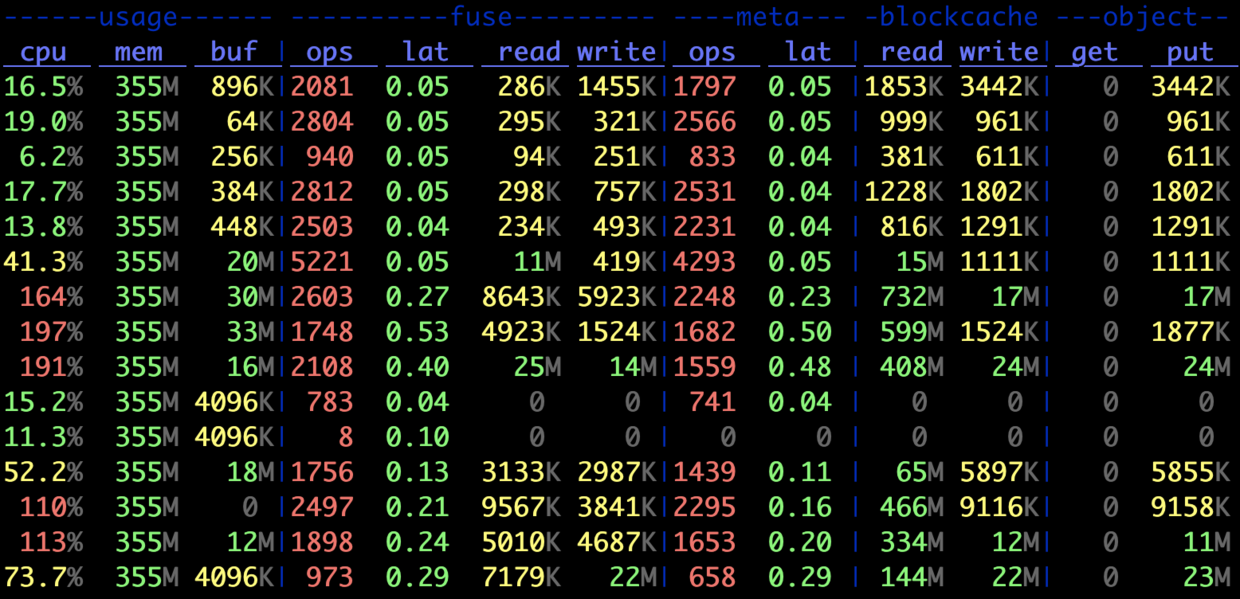
可见,读请求基本全部在 blockcache 命中,而不再需要去访问对象存储;fuse 和 meta 侧的 ops 统计也得到了极大提升,与预期吻合。
总结
本文以本地文件系统更擅长的 Git 仓库管理和 Make 编译任务为切入点,评估这些任务在 JuiceFS 存储上的性能表现,并使用 JuiceFS 自带的 profile 与 stats 工具进行分析,通过调整文件系统挂载参数做针对性的优化。
毫无疑问,本地文件系统与 JuiceFS 等分布式文件系统存在着天然的特征差异,二者面向的应用场景也截然不同。本文选择了两种特殊的应用场景,只是为了在差异鲜明的情境下介绍如何为 JuiceFS 做性能调优,旨在抛砖引玉,希望大家举一反三。如果你有相关的想法或经验,欢迎在 JuiceFS 论坛或用户群分享和讨论。
推荐阅读
知乎 x JuiceFS:利用 JuiceFS 给 Flink 容器启动加速
项目地址: Github (https://github.com/juicedata/juicefs)如有帮助的话欢迎关注我们哟! (0ᴗ0✿)
如何利用 JuiceFS 的性能工具做文件系统分析和调优的更多相关文章
- 面试官:怎么做JDK8的内存调优?
面试官:怎么做JDK8的内存调优? 看着面试官真诚的眼神,心中暗想看起来年纪轻轻却提出如此直击灵魂的问题.擦了擦额头上汗,我稍微调整了一下紧张的情绪,对面试官说: 在内存调优之前,需要先了解JDK8的 ...
- Linux 进程级开启最大文件描述符 调优
开启最大文件数 系统可以开启的最大文件描述符(可同时开启最多的文件数),最大开启65535,可根据需求进行调优. 查看系统当前可开启最大文件描述符数 ulimit -n [root@localhost ...
- Linux性能优化从入门到实战:16 文件系统篇:总结磁盘I/O指标/工具、问题定位和调优
(1)磁盘 I/O 性能指标 文件系统和磁盘 I/O 指标对应的工具 文件系统和磁盘 I/O 工具对应的指标 (2)磁盘 I/O 问题定位分析思路 (3)I/O 性能优化思路 Step 1:首先采用 ...
- Linux性能优化之磁盘I/O调优
I/O指标已介绍,那么如何查看系统的这些指标呢? 一.根据工具查性能 二.根据性能找工具 三.磁盘I/O观察实例 iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的 使用率 . I ...
- spark性能优化-JVM虚拟机垃圾回收调优
1 2 3 4
- mysql性能瓶颈分析、性能指标、指标搜集方法与性能分析调优工具
本文主要讲解mysql的性能瓶颈分析.性能指标.性能指标信息的搜集工具与方法.分析调优工具的使用. 文章尚未完成. 性能瓶颈: 慢.写速度比读速度慢很多 主要的性能指标: 访问频度, 并发连接量, ...
- 成为Java GC专家(5)—Java性能调优原则
并不是每个程序都需要调优.如果一个程序性能表现和预期一样,你不必付出额外的精力去提高它的性能.然而,在程序调试完成之后,很难马上就满足它的性能需求,于是就有了调优这项工作.无论哪种编程语言,对应用程序 ...
- ElasticSearch中的JVM性能调优
ElasticSearch中的JVM性能调优 前一段时间被人问了个问题:在使用ES的过程中有没有做过什么JVM调优措施? 在我搭建ES集群过程中,参照important-settings官方文档来的, ...
- Spark性能调优-基础篇
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
随机推荐
- 洛谷4755 Beautiful Pair (分治)
题目描述 小D有个数列 \(a\),当一个数对 \((i,j)(i\le j)\) 满足\(a_i\)和\(a_j\)的积 不大于 \(a_i \cdots a_j\) 中的最大值时,小D认为这个数对 ...
- 微服务网关Ocelot加入IdentityServer4鉴权-.NetCore(.NET5)中使用
Consul+Ocelot+Polly在.NetCore中使用(.NET5)-Consul服务注册,服务发现 Consul+Ocelot+Polly在.NetCore中使用(.NET5)-网关Ocel ...
- java---String 和 StringBuffer
Java-String和StringBuffer类 Java String 类 字符串在Java中属于对象,Java提供String类来创建和操作字符串. 创建字符串 创建字符串常用的方法如下: ...
- 痞子衡嵌入式:超级下载算法RT-UFL v1.0在IAR EW for Arm下的使用
痞子衡主导的"学术"项目 <RT-UFL - 一个适用全平台i.MXRT的超级下载算法设计> v1.0 版发布近 4 个月了,部分客户已经在实际项目开发调试中用上了这个 ...
- 半天撸一个简易版mybatis
为什么需要持久层框架? 首先我们先看看使用原生jdbc存在的问题? public static void main(String[] args) { Connection connection = n ...
- vue3.x移动端页面基于vue-router的路由切换动画
移动端页面切换一般都具有动画,我们既然要做混合开发,做完之后还是不能看起来就像一个网页,所以我们基于vue-router扩展了一个页面切换push和pop的动画.这是一篇比较硬核的帖子,作者花了不少精 ...
- Convolutional Neural Network-week1编程题(TensorFlow实现手势数字识别)
1. TensorFlow model import math import numpy as np import h5py import matplotlib.pyplot as plt impor ...
- SpringBoot加密配置属性
一.背景 在系统中的运行过程中,存在很多的配置属性,比如: 数据库配置.阿里云配置 等等,这些配置有些属性是比较敏感的,是不应直接以明文的方式出现在配置文件中,因此对于这些配置我们就需要加密来处理. ...
- 广域网(ppp协议、HDLC协议)
文章转自:https://blog.csdn.net/weixin_43914604/article/details/105028759 学习课程:<2019王道考研计算机网络> 学习目的 ...
- 深入理解 Linux的进程,线程,PID,LWP,TID,TGID
转载:https://www.linuxidc.com/Linux/2019-03/157819.htm 在Linux的top和ps命令中,默认看到最多的是pid (process ID),也许你也能 ...