Flink sql 之AsyncIO与LookupJoin的几个疑问 (源码分析)
本文源码基于flink 1.14
被同事问到几个关于AsyncIO和lookUp维表的问题所以翻了下源码,从源码的角度解惑这几个问题
对于AsyncIO不了解的可以看看之前写的这篇 《Flink中异步AsyncIO的实现 (源码分析)》
问题一:AsyncIO 有(排序 / 非排序) 模式,非排序模式数据会乱序,那水印waterMarker会乱序吗 ???
不想看源码的先直接给出答案
:不会乱序,接收到水印数据后非排序模式会,直接往下游发送waterMarker
问题二:LookUp维表join分为同步和Async, 上面异步非排序,数据会乱序水印不会,那sql的维表异步join数据会乱序吗 ???
:不会乱序,源码中默认都是AsyncIO的排序(Ordered)模式
ok上源码
问题一:AsyncIO水印会乱序吗?
来看一下异步io对应的StreamOperator的源码 org.apache.flink.streaming.api.operators.async.AsyncWaitOperator
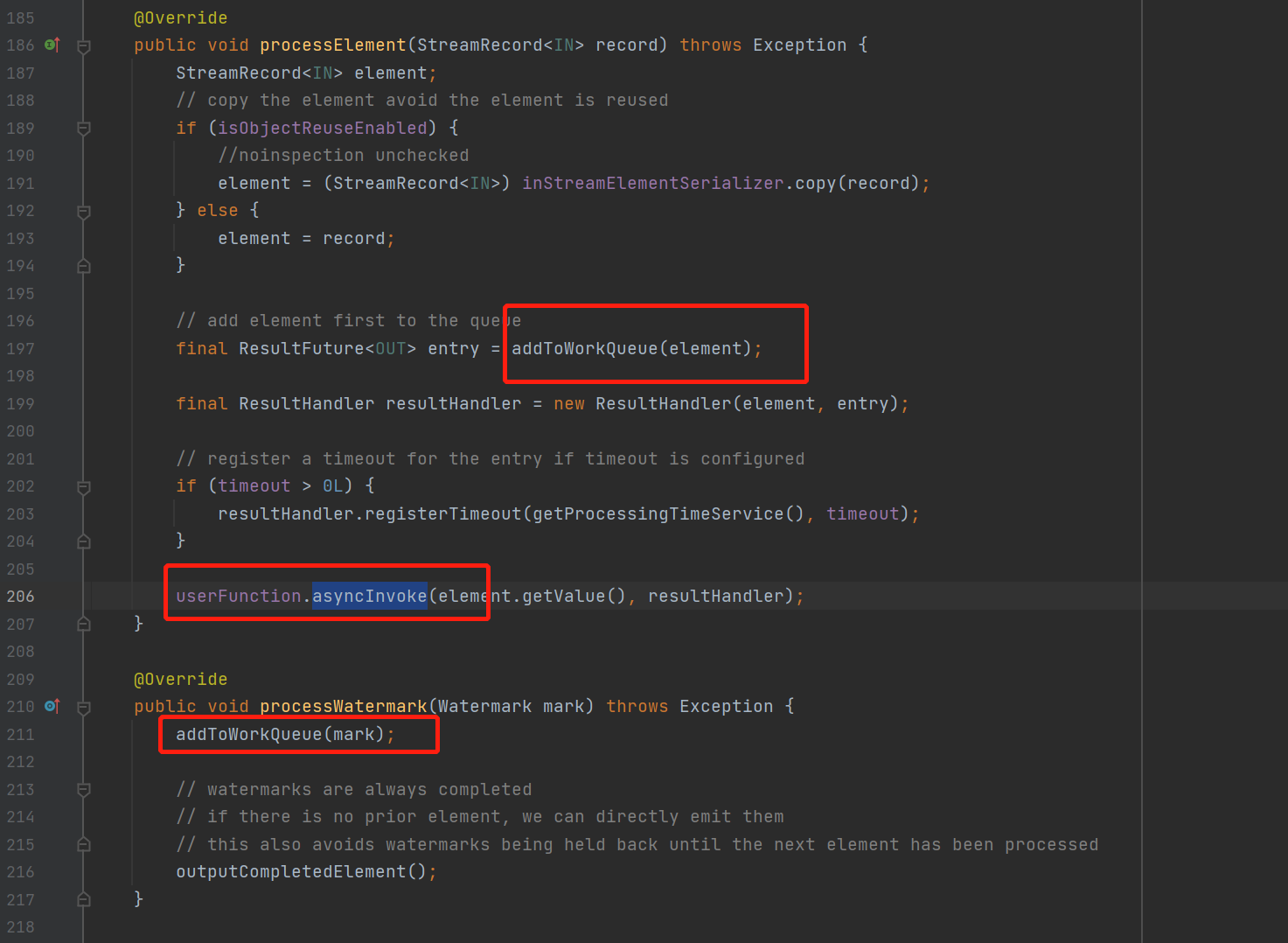
异步io接收到数据以后,加入到queue里面,然后调用用户写的UserFunction
异步io接收到水印以后,同样加入到queue里面
那继续看addToWorkQueue方法接收到水印以后

加入具体的queue
继续,这里只看非排序的unordered

也是一样直接加addWtaermark()
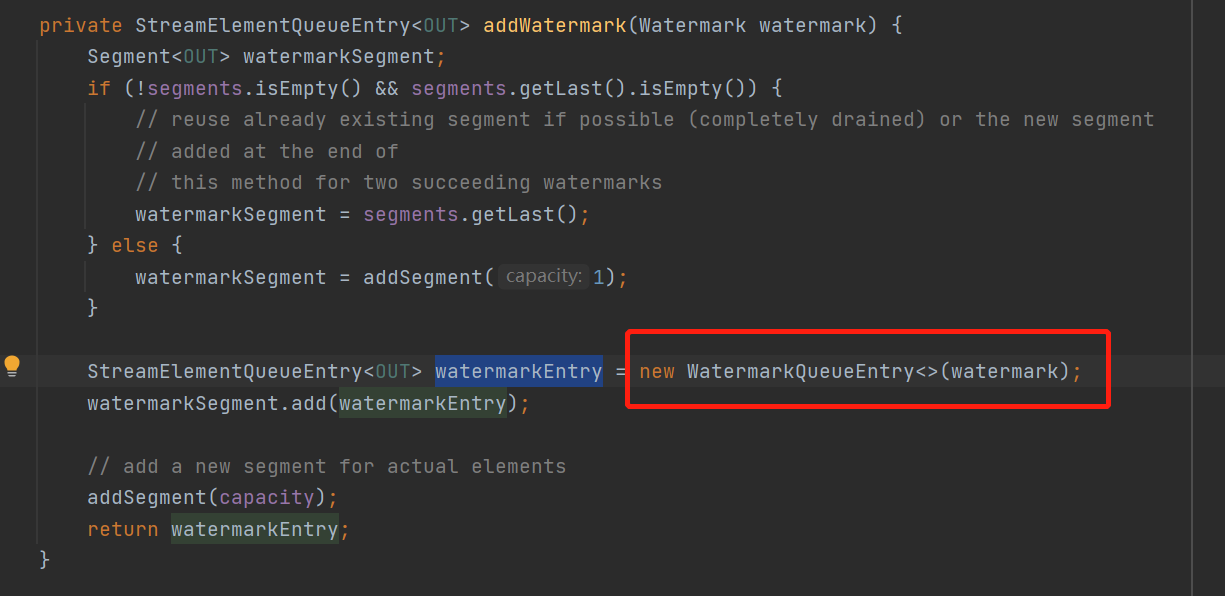
将水印包装成一个WatermarkQueueEntry对象直接放queue
ok那来看下这个watermarkQueueEntry类

可以看到当水印进入queue以后直接就是已完成的了,就可以直接往下游发送,管你其他异步处理的数据完成没完成,水印已经往下发了
问题二:LookUp维表异步join会导致数据乱序吗?
看下关于lookup的calcite的对应规则

调用链不看了,有点长来看最后生成的,execNode物理的relNode执行节点StreamExecLookupJoin
来看下它抽象类 CommonExecLookupJoin的translateToPlanInternal方法
最后走到 createAsyncLookupJoin 来看下如何生成AsyncIO的function的
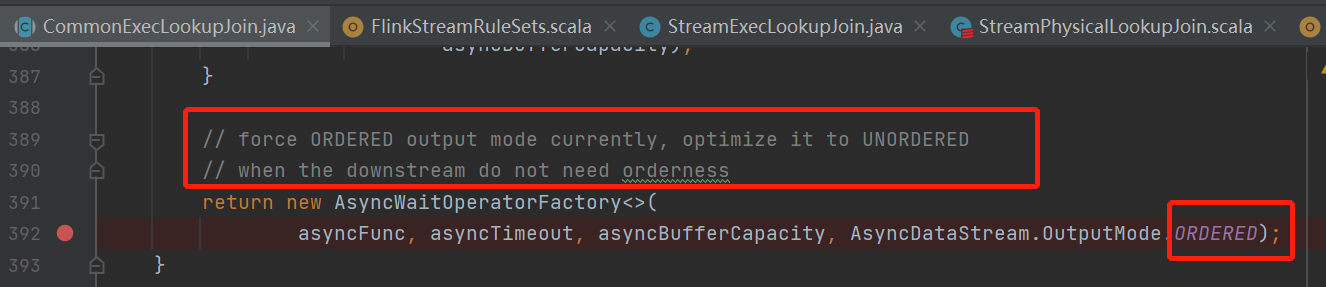
ok 用的ordered模式的异步io,维表关联的数据尽管是异步去join的,但是往下游发的时候还是按顺序的
不会乱序
Flink sql 之AsyncIO与LookupJoin的几个疑问 (源码分析)的更多相关文章
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版)
[源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版) 目录 [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码 ...
- MyCat源码分析系列之——SQL下发
更多MyCat源码分析,请戳MyCat源码分析系列 SQL下发 SQL下发指的是MyCat将解析并改造完成的SQL语句依次发送至相应的MySQL节点(datanode)的过程,该执行过程由NonBlo ...
- MyBatis源码分析-SQL语句执行的完整流程
MyBatis 是支持定制化 SQL.存储过程以及高级映射的优秀的持久层框架.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.MyBatis 可以对配置和原生Map使用简 ...
- Flink源码分析 - 源码构建
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483692&idx=1&sn=18cddc1ee ...
- MyBatis 源码分析 - SQL 的执行过程
* 本文速览 本篇文章较为详细的介绍了 MyBatis 执行 SQL 的过程.该过程本身比较复杂,牵涉到的技术点比较多.包括但不限于 Mapper 接口代理类的生成.接口方法的解析.SQL 语句的解析 ...
- 第十一篇:Spark SQL 源码分析之 External DataSource外部数据源
上周Spark1.2刚发布,周末在家没事,把这个特性给了解一下,顺便分析下源码,看一看这个特性是如何设计及实现的. /** Spark SQL源码分析系列文章*/ (Ps: External Data ...
- 第十篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 query
/** Spark SQL源码分析系列文章*/ 前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的. 那么基于以上存储结构,我们查询cache在 ...
- 第九篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 cache table
/** Spark SQL源码分析系列文章*/ Spark SQL 可以将数据缓存到内存中,我们可以见到的通过调用cache table tableName即可将一张表缓存到内存中,来极大的提高查询效 ...
随机推荐
- nginx 添加ssl证书
第一步: 获取linux的证书格式 .crt .key 第二步: 在nginx中default.conf中再添加一个server 第三步: 内容举例如下: server { #这里开始 liste ...
- 自学 Java开发(Java后台开发|Java后端开发)的书籍推荐
java编程思想java并发编程实战深入理解java虚拟机函数式编程思维tcp/ip详解鸟哥的linux私房菜spring mvc +mybatis开发从入门到精通spring技术内幕elastics ...
- Python turtle.right与turtle.setheading的区别
一.概念 turtle.right与turtle.left用法一致,我们以turtle.right为例进行讲述. turtle.right(angle)向右旋转angle角度. turtle.seth ...
- 鸿蒙内核源码分析(消息队列篇) | 进程间如何异步传递大数据 | 百篇博客分析OpenHarmony源码 | v33.02
百篇博客系列篇.本篇为: v33.xx 鸿蒙内核源码分析(消息队列篇) | 进程间如何异步传递大数据 | 51.c.h .o 进程通讯相关篇为: v26.xx 鸿蒙内核源码分析(自旋锁篇) | 自旋锁 ...
- P5369-[PKUSC2018]最大前缀和【状压dp】
正题 题目链接:https://www.luogu.com.cn/problem/P5369 题目大意 一个数列\(a\)的权值定义为\(max\{\sum_{i=1}^ka_i\}(k\in[1,n ...
- Jmeter压测学习2---提取token,并关联参数
注意:我是根据我司的项目写的,这里作为一个笔记使用,不要照搬. 一般登录操作,都会有个token,我们要提取token作为参数,用于后面的操作. 接口的登录是返回一个json数据,token值在返回的 ...
- disruptor笔记之七:等待策略
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- python测试开发工具库汇总(转载)
Web UI测试自动化 splinter - web UI测试工具,基于selnium封装. selenium - web UI自动化测试. mechanize- Python中有状态的程序化Web浏 ...
- xmake v2.5.8 发布,新增 Pascal/Swig 程序和 Lua53 运行时支持
xmake 是一个基于 Lua 的轻量级跨平台构建工具,使用 xmake.lua 维护项目构建,相比 makefile/CMakeLists.txt,配置语法更加简洁直观,对新手非常友好,短时间内就能 ...
- 一文读懂 Serverless,将配置化思想复用到平台系统中
作者 | 春哥大魔王 来源 | Serverless 公众号 写在前面 在 SaaS 领域 Salesforce 是佼佼者,其 CRM 的概念已经扩展到了 Marketing.Sales.Servic ...