HBase HA 集群环境搭建
安装准备
确定已安装并启动 HDFS(HA)集群
角色分配如下:
node-01: namenode datanode regionserver hmaster zookeeper
node-02: datanode regionserver zookeeper
node-03: datanode regionserver zookeeper
安装步骤
- SFTP 工具上传并解压 hbase 安装包 hbase-1.4.13-bin.tar.gz
[root@node-01 ~]# tar -zxvf hbase-1.4.13-bin.tar.gz -C /root/apps
[root@node-01 ~]# rm -rf hbase-1.4.13-bin.tar.gz
- 设置 HBase 环境变量
[root@node-01 hbase-1.4.13]# vim /etc/profile
#行尾添加
export HBASE_HOME=/root/apps/hbase-1.4.13
export PATH=$PATH:$HBASE_HOME/bin
[root@node-01 hbase-1.4.13]# source /etc/profile
- 修改 hbase-env.sh 配置文件
[root@node-01 ~]# cd /root/apps/hbase-1.4.13/conf/
[root@node-01 conf]# vim hbase-env.sh
#删除 27 行注释,设置 JDK 路径
export JAVA_HOME=/root/apps/jdk1.8.0_141/
# 46 行和 47 行添加注释(仅在 JDK 7 需要,JDK 8 不需要直接注释掉)
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize =128m -XX:ReservedCodeCacheSize=256m"
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX :MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
#删除 105 行注释,设置 HBase 日志文件路径
export HBASE_LOG_DIR=${HBASE_HOME}/logs
#删除 120 行注释,设置pid进程文件存储路径
export HBASE_PID_DIR=${HBASE_HOME}/pids
#删除 128 行注释,设置HBase不启用内置的zookeeper(使用外部zookeeper)
export HBASE_MANAGES_ZK=false
- 修改 hbase-site.xml 配置文件
[root@node-01 conf]# vi hbase-site.xml
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node-01:9000/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zookeeper的地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node-01:2181,node-02:2181,node-03:2181</value>
</property>
<!-- 指定 Hbaes 临时路径-->
<property>
<name>hbase.tmp.dir</name>
<value>/root/apps/hbase-1.4.13/tmp</value>
</property>
</configuration>
- 修改 regionservers 配置文件
# 指定要启动 RegionServer 集群主机
[root@node-01 conf]# vim regionservers
node-01
node-02
node-03
- 配置备份的 Master
[root@node-01 conf]# >backup-masters
[root@node-01 conf]# vim backup-masters
node-02
- 建立 Hadoop 的 core-site.xml、hdfs-site.xml 两个配置文件的软连接
[root@node-01 conf]# ln -s /root/apps/hadoop-3.2.1/etc/hadoop/core-site.xml core-site.xml
[root@node-01 conf]# ln -s /root/apps/hadoop-3.2.1/etc/hadoop/hdfs-site.xml hdfs-site.xml
- 将环境配置文件和 hbase 文件夹分别拷贝到 node-02 和 node-03
[root@node-01 conf]# cd /etc/
[root@node-01 etc]# scp profile node-02:$PWD
[root@node-01 etc]# scp profile node-03:$PWD
[root@node-02 hbase-1.4.13]# source /etc/profile
[root@node-03 hbase-1.4.13]# source /etc/profile
[root@node-01 etc]# cd /root/apps/
[root@node-01 apps]# scp -r hbase-1.4.13/ node-02:$PWD
[root@node-01 apps]# scp -r hbase-1.4.13/ node-03:$PWD
启动 HBase 集群
- 启动 HBase 集群必须先启动 zk 集群 和 HDFS 集群
[root@node-01 hbase-1.4.13]# zkCluster.sh start
[root@node-01 hbase-1.4.13]# start-dfs.sh
[root@node-02 hbase-1.4.13]# hdfs --daemon start datanode
[root@node-03 hbase-1.4.13]# hdfs --daemon start datanode
[root@node-01 hbase-1.4.13]# hdfs --daemon start zkfc
[root@node-02 hbase-1.4.13]# hdfs --daemon start zkfc
- 启动 HBase 的 Master(active) 和 regionserver
[root@node-01 bin]# start-hbase.sh
[root@node-01 conf]# jps
5152 HMaster
2930 DataNode
2788 NameNode
1625 QuorumPeerMain
5545 Jps
3165 JournalNode
5341 HRegionServer
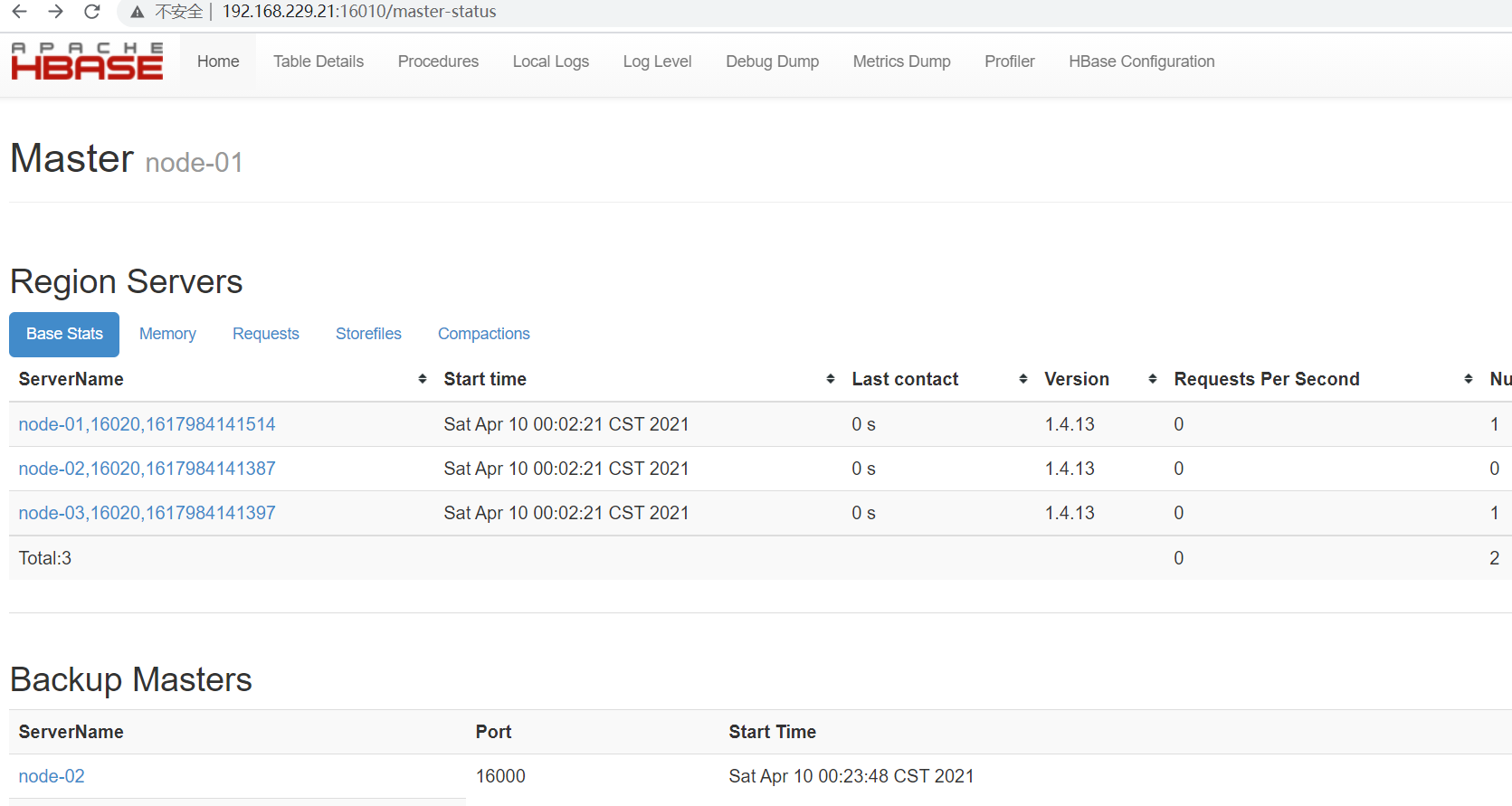
- 在浏览器中打开 HBase 的 Web UI 页面(端口:16010)
网址:192.168.229.21:16010(active)192.168.229.22:16010(backup)
HBase HA 集群环境搭建的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- HBase —— 集群环境搭建
一.集群规划 这里搭建一个3节点的HBase集群,其中三台主机上均为Regin Server.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002上部署备用的 ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- Ningx集群环境搭建
Ningx集群环境搭建 Nginx是什么? Nginx ("engine x") 是⼀个⾼性能的 HTTP 和 反向代理 服务器,也是⼀个 IMAP/ POP3/SMTP 代理服务 ...
- hadoop2集群环境搭建
在查询了很多资料以后,发现国内外没有一篇关于hadoop2集群环境搭建的详细步骤的文章. 所以,我想把我知道的分享给大家,方便大家交流. 以下是本文的大纲: 1. 在windows7 下面安装虚拟机2 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- starctf_2019_babyshell
starctf_2019_babyshell 有时shellcode受限,最好的方法一般就是勉强的凑出sys read系统调用来注入shellcode主体. 我们拿starctf_2019_babys ...
- Java性能优化的十条小技巧
1 System.nanoTime 测试性能时,System.nanoTime比System.currentTimeMills更精确,前者使用纳秒计时,且对系统影响更小. 具体来说: System.c ...
- kubernetes CRD
官方文档:https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions ...
- Compound Words UVA - 10391
You are to find all the two-word compound words in a dictionary. A two-word compound word is a wor ...
- Day14_83_反射机制获取某个特定属性的各部分
反射机制获取某个特定属性的各部分 * 通过属性名(变量名)来获取一个属性整体 例如: Field userNoField=c.getDeclaredField("userNo"); ...
- Git 简介与仓库使用
1. Git 简介 2. 远程仓库的使用 3. 本地仓库的使用 1. Git 简介 Git 是分布式版本控制系统,同一个 Git 仓库,可以分布到不同的机器上. 其原理是首先找一台电脑充当服务器的角色 ...
- 博客之初体验-----python初了解
---恢复内容开始--- 1.python2.x与python3.x的区别 (1) 2.x的默认编码是ASSIC码,不支持中文 (2) 3.x的默认编码是UNICODE,支持中文 (3) 2.x版本与 ...
- MySQL8安装教程及问题解决
目录 1.下载MySQL的zip文件,解压,在根目录(bin所在的目录)下创建my.ini文件 2.管理员模式打开命令提示符(shell或者说小黑窗),按以下命令操作. 3.不过......我这里密码 ...
- 1082 Read Number in Chinese
Given an integer with no more than 9 digits, you are supposed to read it in the traditional Chinese ...
- Python中如何生成requirements.txt文件
Python项目中一般都包含一个名为 requirements.txt 文件,用来记录当前项目所有的依赖包和版本号,在一个新环境下通过该文件可以更方便的构建项目所需要的运行环境. 生成requirem ...