Spark SQL 之 RDD、DataFrame 和 Dataset 如何选择
引言
Apache Spark 2.2 以及以上版本提供的三种 API - RDD、DataFrame 和 Dataset,它们都可以实现很多相同的数据处理,它们之间的性能差异如何,在什么情况下该选用哪一种呢?
RDD
从一开始 RDD 就是 Spark 提供的面向用户的主要 API。从根本上来说,一个 RDD 就是你的数据的一个不可变的分布式元素集合,在集群中跨节点分布,可以通过若干提供了转换和处理的底层 API 进行并行处理。
在正常情况下都不推荐使用 RDD 算子
- 在某种抽象层面来说,使用 RDD 算子编程相当于直接使用最底层的 Java API 进行编程
- RDD 算子与 SQL、DataFrame API 和 DataSet API 相比,更偏向于如何做,而非做什么,这样优化的空间很少
- RDD 语言不如 SQL 语言友好
仅在一些特殊情况下可以使用 RDD
- 你希望可以对你的数据集进行最基本的转换、处理和控制;
- 你的数据是非结构化的,比如流媒体或者字符流;
- 你想通过函数式编程而不是特定领域内的表达来处理你的数据;
- 你不希望像进行列式处理一样定义一个模式,通过名字或字段来处理或访问数据属性(更高层次抽象);
- 你并不在意通过 DataFrame 和 Dataset 进行结构化和半结构化数据处理所能获得的一些优化和性能上的好处;
可能你会问:RDD 是不是快要降级成二等公民了?是不是快要退出历史舞台了?
答案是非常坚决的:不!
我们可以通过简单的 API 方法调用在 DataFrame 或 Dataset 与 RDD 之间进行无缝切换,事实上 DataFrame 和 Dataset也正是基于 RDD 提供的。
DataFrame
与 RDD 相似,DataFrame 也是数据的一个不可变分布式集合。但与 RDD 不同的是,数据都被组织到有名字的列中,就像关系型数据库中的表一样。设计 DataFrame 的目的就是要让对大型数据集的处理变得更简单,它让开发者可以为分布式的数据集指定一个模式,进行更高层次的抽象。它提供了特定领域内专用的 API 来处理你的分布式数据,并让更多的人可以更方便地使用 Spark,而不仅限于专业的数据工程师。
Spark 2.0 中,DataFrame 和 Dataset 的 API 融合到一起,完成跨函数库的数据处理能力的整合。在整合完成之后,开发者们就不必再去学习或者记忆那么多的概念了,可以通过一套名为 Dataset 的高级并且类型安全的 API 完成工作。
Dataset
相对于RDD,Dataset 提供了强类型支持,也是在 RDD 的每行数据加了类型约束
- 假设RDD中的两行数据长这样:
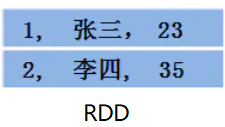
- 那么 Dataset 中的数据长这样:
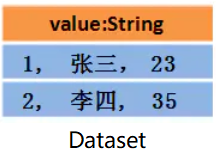
- 或者长这样(每行数据是个 Object ):

Dataset API 的优点
在 Spark 2.0 里,DataFrame 和 Dataset 的统一 API 会为 Spark 开发者们带来许多方面的好处
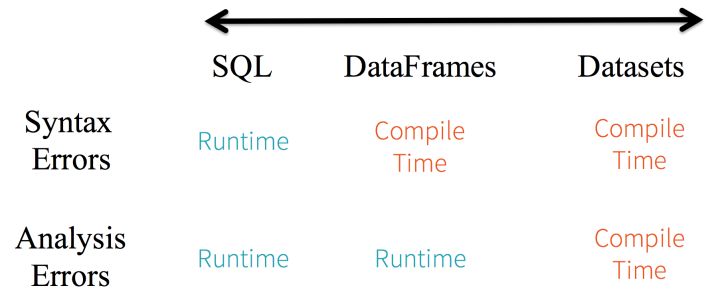
1、静态类型与运行时类型安全
从 SQL 的最小约束到 Dataset 的最严格约束,把静态类型和运行时安全想像成一个图谱。比如,如果你用的是 Spark SQL 的查询语句,要直到运行时你才会发现有语法错误(这样做代价很大),而如果你用的是 DataFrame 和 Dataset,你在编译时就可以捕获错误(这样就节省了开发者的时间和整体代价)。也就是说,当你在 DataFrame 中调用了 API 之外的函数时,编译器就可以发现这个错。不过,如果你使用了一个不存在的字段名字,那就要到运行时才能发现错误了。
图谱的另一端是最严格的 Dataset。因为 Dataset API 都是用 lambda 函数和 JVM 类型对象表示的,所有不匹配的类型参数都可以在编译时发现。而且在使用 Dataset 时,你的分析错误也会在编译时被发现,这样就节省了开发者的时间和代价。
所有这些最终都被解释成关于类型安全的图谱,内容就是你的 Spark 代码里的语法和分析错误。在图谱中,Dataset 是最严格的一端,但对于开发者来说也是效率最高的。
2、关于结构化和半结构化数据的高级抽象和定制视图
把 DataFrame 当成 Dataset[Row] 的集合,就可以对你的半结构化数据有了一个结构化的定制视图。比如,假如你有个非常大量的用 JSON 格式表示的物联网设备事件数据集。因为 JSON 是半结构化的格式,那它就非常适合采用 Dataset 来作为强类型化的 Dataset[DeviceIoTData] 的集合。
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ",
"ip": "80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": "Poland",
"latitude": 53.080000, "longitude": 18.620000, "scale": "Celsius",
"temp": 21, "humidity": 65, "battery_level": 8, "c02_level": 1408,
"lcd": "red", "timestamp" :1458081226051}
你可以用一个Scala Case Class来把每条JSON记录都表示为一条DeviceIoTData,一个定制化的对象。
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2:
String, cca3: String, cn: String, device_id: Long, device_name: String,
humidity: Long, ip: String, latitude: Double, lcd: String, longitude: Double,
scale:String, temp: Long, timestamp: Long)
接下来,我们就可以从一个JSON文件中读入数据。
// read the json file and create the dataset from the
// case class DeviceIoTData
// ds is now a collection of JVM Scala objects DeviceIoTData
val ds = spark.read
.json(“/databricks-public-datasets/data/iot/iot_devices.json”)
.as[DeviceIoTData]
上面的代码其实可以细分为三步:
- Spark 读入 JSON,根据模式创建出一个 DataFrame 的集合;
- 在这时候,Spark 把你的数据用“DataFrame = Dataset[Row]” 进行转换,变成一种通用行对象的集合,因为这时候它还不知道具体的类型;
- 然后,Spark 就可以按照类 DeviceIoTData 的定义,转换出 “Dataset[Row] -> Dataset[DeviceIoTData]” 这样特定类型的 Scala JVM 对象了。
许多和结构化数据打过交道的人都习惯于用列的模式查看和处理数据,或者访问对象中的某个特定属性。将 Dataset 作为一个有类型的 Dataset[ElementType] 对象的集合,你就可以非常自然地又得到编译时安全的特性,又为强类型的JVM对象获得定制的视图。而且你用上面的代码获得的强类型的Dataset[T]也可以非常容易地用高级方法展示或处理。
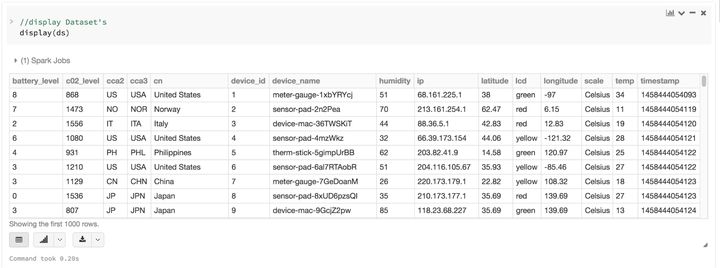
3、方便易用的结构化API
虽然结构化可能会限制你的 Spark 程序对数据的控制,但它却提供了丰富的语义,和方便易用的特定领域内的操作,后者可以被表示为高级结构。事实上,用 Dataset 的高级 API 可以完成大多数的计算。
比如,它比用 RDD 数据行的数据字段进行 agg、select、sum、avg、map、filter或groupBy等操作简单得多,只需要处理Dataset 类型的 DeviceIoTData 对象即可。
用一套特定领域内的 API 来表达你的算法,比用 RDD 来进行关系代数运算简单得多。
4、性能与优化
除了上述优点之外,你还要看到使用 DataFrame 和 Dataset API 带来的空间效率和性能提升。原因有如下两点:
- DataFrame 和 Dataset API 都是基于 Spark SQL 引擎构建的,它使用 Catalyst 来生成优化后的逻辑和物理查询计划。所有R、Java、Scala或Python的DataFrame/Dataset API,所有的关系型查询的底层使用的都是相同的代码优化器,因而会获得空间和速度上的效率。尽管有类型的 Dataset[T] API 是对数据处理任务优化过的,无类型的 Dataset[Row](别名DataFrame)却运行得更快,适合交互式分析。

- Spark 作为一个编译器它可以理解 Dataset 类型的 JVM 对象,它会使用编码器来把特定类型的 JVM 对象映射成Tungsten 的内部内存表示。结果,Tungsten 的编码器就可以非常高效地将 JVM 对象序列化或反序列化,同时生成压缩字节码,这样执行效率就非常高了。
该什么时候使用 DataFrame 或 Dataset 呢?
- 如果你需要丰富的语义、高级抽象和特定领域专用的 API,那就使用 DataFrame 或 Dataset;
- 如果你的处理需要对半结构化数据进行高级处理,如filter、map、aggregation、average、sum、SQL查询、列式访问或使用 lambda 函数,那就使用 DataFrame 或 Dataset;
- 如果你想在编译时就有高度的类型安全,想要有类型的JVM对象,用上Catalyst优化,并得益于Tungsten生成的高效代码,那就使用Dataset;
- 如果你想在不同的Spark库之间使用一致和简化的API,那就使用DataFrame或Dataset;
- 如果你是R语言使用者,就用DataFrame;
- 如果你是Python语言使用者,就用DataFrame,在需要更细致的控制时就退回去使用RDD;
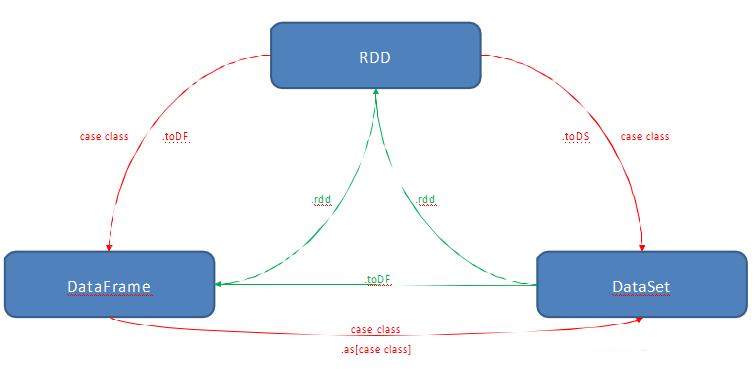
注意:只需要简单地调用一下.rdd,就可以无缝地将 DataFrame 或 Dataset 转换成 RDD,如下:
// select specific fields from the Dataset, apply a predicate
// using the where() method, convert to an RDD, and show first 10
// RDD rows
val deviceEventsDS = ds.select($"device_name", $"cca3", $"c02_level")
.where($"c02_level" > 1300)
// convert to RDDs and take the first 10 rows
val eventsRDD = deviceEventsDS.rdd.take(10)
总结
在什么时候该选用 RDD、DataFrame 或 Dataset 看起来好像挺明显。前者可以提供底层的功能和控制,后者支持定制的视图和结构,可以提供高级和特定领域的操作,节约空间并快速运行。
DataFrame 和 Dataset,或 RDD API,按你的实际需要和场景选一个来用吧!
Spark SQL 之 RDD、DataFrame 和 Dataset 如何选择的更多相关文章
- [Spark SQL] SparkSession、DataFrame 和 DataSet 练习
本課主題 DataSet 实战 DataSet 实战 SparkSession 是 SparkSQL 的入口,然后可以基于 sparkSession 来获取或者是读取源数据来生存 DataFrameR ...
- spark的数据结构 RDD——DataFrame——DataSet区别
转载自:http://blog.csdn.net/wo334499/article/details/51689549 RDD 优点: 编译时类型安全 编译时就能检查出类型错误 面向对象的编程风格 直接 ...
- Spark SQL中 RDD 转换到 DataFrame (方法二)
强调它与方法一的区别:当DataFrame的数据结构不能够被提前定义.例如:(1)记录结构已经被编码成字符串 (2) 结构在文本文件中,可能需要为不同场景分别设计属性等以上情况出现适用于以下方法.1. ...
- Spark SQL中 RDD 转换到 DataFrame
1.people.txtsoyo8, 35小周, 30小华, 19soyo,882./** * Created by soyo on 17-10-10. * 利用反射机制推断RDD模式 */impor ...
- RDD, DataFrame or Dataset
总结: 1.RDD是一个Java对象的集合.RDD的优点是更面向对象,代码更容易理解.但在需要在集群中传输数据时需要为每个对象保留数据及结构信息,这会导致数据的冗余,同时这会导致大量的GC. 2.Da ...
- Spark之 SparkSql、DataFrame、DataSet介绍
SparkSql SparkSql是专门为spark设计的一个大数据仓库工具,就好比hive是专门为hadoop设计的一个大数据仓库工具一样. 特性: .易整合 可以将sql查询与spark应用程序进 ...
- spark SQL、RDD、Dataframe总结
- DataFrame 转换为Dataset
写在前面: A DataFrame is a Dataset organized into named columns. A Dataset is a distributed collection o ...
- spark结构化数据处理:Spark SQL、DataFrame和Dataset
本文讲解Spark的结构化数据处理,主要包括:Spark SQL.DataFrame.Dataset以及Spark SQL服务等相关内容.本文主要讲解Spark 1.6.x的结构化数据处理相关东东,但 ...
随机推荐
- Linux Nvidia显卡驱动安装
1 概述 因为某些需要需要在Linux上安装显卡驱动,这里记录一下安装过程. 2 环境 Manjaro RTX 2060 3 下载驱动安装包 到官网上搜索下载即可,可以戳这里: 选择自己的显卡型号即可 ...
- 一文吃透jQuery选择器!
1 jQuery选择器 jQuery选择器用于选择DOM元素进行相应操作,允许通过多种方式选择,包括标签名,属性名,类名,id等对元素进行选择,基于CSS选择器.jQuery中所有的选择器都以$符号开 ...
- Azure data studio 跨平台数据库管理工具试用
最近折腾 azure sql database 的时候发现了微软的一款新的数据库管理工具: azure data studio.从名字上看 azure data studio 好像是专门为 azure ...
- linux中[gcc -shared -fPIC]的含义
linux在gcc编译时加上 -shared 参数时,目的是使源码编译成动态库 .so 文件: 而-fPIC的作用是 告知编译器 生成位置无关代码(编译产生的代码没有绝对位置,只有相对位置):从而可以 ...
- 浅入Kubernetes(11):了解 Service 和 Endpoint
目录 Srevice Service 的创建及现象 Service 定义 Endpoint slices 创建 Endpoint.Service Service 创建应用 创建 Endpoint 浅入 ...
- Day11_49_HashTable
HashTable * HashTable是较早期的使用Hash算法的一种容器结构,现在基本已被淘汰,单线程多使用HashMap,多线程使用ConcurrentHashMap. * HashTable ...
- B - Tempter of the Bone(DFS+剪枝)
The doggie found a bone in an ancient maze, which fascinated him a lot. However, when he picked it u ...
- B - 抽屉 POJ - 2356 (容斥原理)
The input contains N natural (i.e. positive integer) numbers ( N <= 10000 ). Each of that numbers ...
- 2- MySQL客户端工具Workbench的使用及数据库的操作
数据库增删改查快速入门 查看数据库: show databases; 选在数据库:use 数据库名: 创建数据库:create database db_name; 删除数据库:drop databa ...
- 07- HTTP协议详解及Fiddler抓包
HTTP协议简介-超文本传输协议 HTTP协议是请求/响应协议:客户端发送请求到服务器,服务器响应该请求.当前版本为1.1版本. HTTP协议特点 1.简单快速:客户向服务器请求服务时,只需传送请求方 ...