【论文阅读】Socially aware motion planning with deep reinforcement learning-annotated
前言:
摘要部分:
For robotic vehicles to navigate safely and efficiently in pedestrian-rich environments, it is important to model subtle human behaviors and navigation rules (e.g., passing on the right). However, while instinctive to humans, socially compliant navigation is still difficult to quantify due to the stochasticity in people’s behaviors. Existing works are mostly focused on using feature-matching techniques to describe and imitate human paths, but often do not generalize well since the feature values can vary from person to person, and even run to run. This work notes that while it is challenging to directly specify the details of what to do (precise mechanisms of human navigation), it is straightforward to specify what not to do (violations of social norms). Specifically, using deep reinforcement learning, this work develops a time-efficient navigation policy that respects common social norms. The proposed method is shown to enable fully autonomous navigation of a robotic vehicle moving at human walking speed in an environment with many pedestrians.
重点:点出人员嘈杂环境中的导航问题,现有的方法是:using feature-matching techniques去描述和模仿人的行驶路径,缺点很明显了:不可预知性较高;所以本文的方法是改变思路 从what to do到what not to do 界线就是violation of social norm,Using DRL 深度强化学习 开发了:time-effective navigation policy
I. Introduction 介绍
- [3]-[6]参考文献employs specific reactive rules for avoiding collision
缺点:并没有考虑人的实际行为方式 - [7][8]随后更成熟的运动模型被提出,也就是考虑并预测人的行为;不过在这个方式下,将导航分为了两步:首先是预测再规划路径
缺点:分开的操作为导致freezing robot 也就是找不到路,低效率的行驶 - 综上需要一种可以model the impact of the robot's motion on the nearby pedestrians
而现在对于cooperative socially compliant navigation可以被分为两个类别:model-based和learning-based
- 基于模型的 model-based:一般都是多参数可调的多机器人避障算法,为了区分human-human和human-robot交互的区别 通过在势场算法中添加用于控制type of intersection的参数,对the extended social forces model 进行了强化
显而易见的优势是:效率高,因为利用的是潜在的几何关系
但是缺点也因此而来:很难确定whether humans do follow such precise geometric rules,而且需要调整的参数也比较多,对于不同的行人就有不同的参数 - 基于学习的 learning-based:学习的方法目标是通过特征点匹配(比如行人的最小距离)去模仿人的行为 得出一种policy,使用IRL(反向RL)【这个...似乎没听过后面得查一下】然后从human demonstration里学习cost function 同时也有与周围行人joint trajectory的概率分布
对于于基于模型的优势:produce the paths that more closely resemble human behaviours
缺点:high computational cost,因为他需要计算并匹配路径特征 而这通常需要周围所有行人的路径信息和一些不可知的information(比如行人的目标);还有一点就是人的行为本来就具有随机性,不同的人不同的场景对于这个随机性都是有影响的
总结来说,现有的研究重点都在建模和复现the detailed mechanisms of social compliance,而对比下,人可以本能判断这个行为是否可取
首先我们需要明确 human navigation是time-effective通常遵循一些东西 例如靠右行驶,所以在这篇文章里我们将这个性质运用于强化学习的框架下 学习人是怎样去避障的方式
Contribution
- 引入socially aware collision avoidance with DRL 用来为强化学习的框架 explaining/inducing socially aware behaviours
- 开发系统神经网络结构(a symmetrical neural network structure) 适用于多机器人场景
- 演示了在人流量大的情况下 和人速度一样的车子运行情况 视频演示
II. Background 背景
A. Collision Avoidance with DRL
多机器人避障问题可以化为 a sequential decision making problem in a RL framework[14]【有空可以看一看】简单来讲就是:
- \(s_t\) 表示时间t下的状态
- \(u_t = v_t\) 表示时间t下的动作 在这里我们用\(v_t\)速度来表示动作
- \(\tilde{s}_t\) a nearby agent 状态
- \(\mathbf{s}_t=[s^o_t,s^h_t]\) 为了表达不确定性 状态分为observable和unobservable
- \(\mathbf{s}^o = [p_x,p_y,v_x,v_y,r] \in \reals^5\) 可观测状态有位置、速度、半径
- \(\mathbf{s}^h = [p_{gx},p_{gy},v_{pref},\psi]\) 不可观测状态有目标点、preferred speed、朝向
我们的目标是develop a policy \(\pi:(s_t,\tilde{s}^o_t)\mapsto u_t\) 从而最小化到达目标时间
\]
\qquad \begin{array}{ll}
\text { s.t. } & \left\|\mathbf{p}_{t}-\tilde{\mathbf{p}}_{t}\right\|_{2} \geq r+\tilde{r} \quad \forall t \\
& \mathbf{p}_{t_{g}}=\mathbf{p}_{g} \\
& \mathbf{p}_{t}=\mathbf{p}_{t-1}+\Delta t \cdot \pi\left(\mathbf{s}_{t-1}, \tilde{\mathbf{s}}_{t-1}^{o}\right) \\
& \tilde{\mathbf{p}}_{t}=\tilde{\mathbf{p}}_{t-1}+\Delta t \cdot \pi\left(\tilde{\mathbf{s}}_{t-1}, \mathbf{s}_{t-1}^{o}\right)
\end{array}
\end{aligned}\]
- \(\left\|\mathbf{p}_{t}-\tilde{\mathbf{p}}_{t}\right\|_{2} \geq r+\tilde{r}\) 是避障的约束
- \(\mathbf{p}_{t_{g}}=\mathbf{p}_{g}\) 到达目标点约束
- 最后两个公式是机器人的动力学公式
然后我们再将其变得更像RL的框架,首先是
- joint configuration \(\mathbf{s}^{jn} = [\mathbf{s},\tilde\mathbf{s}^o]\) 把已知nearby agent状态进行合并
- reward function \(R_{col}(\mathbf{s}^{jn},\mathbf{u})\) 当到达goal的时候给正值,撞到别人的时候给惩罚
- state transition model \(P(\mathbf{s}^{jh}_t.\mathbf{s}^{jh}_t|\mathbf{u}_t)\) 虽然这个是不知道的 也就是由其他 agents' motion due to its hidden intents \((\tilde{\mathbf{s} }^h)\)
最后就是两个强化学习的公式[不知道的建议可以进入强化学习书本进行基础学习]
\]
\gamma^{\Delta t \cdot v_{p r e f}} \int_{\mathbf{s}_{t+1}^{j n}} P\left(\mathbf{s}_{t}^{j n}, \mathbf{s}_{t+1}^{j n} \mid \mathbf{u}\right) V^{*}\left(\mathbf{s}_{t+1}^{j n}\right) d \mathbf{s}_{t+1}^{j n}
\]
比较棘手的是 \(\mathbf{s}^{jn}_t\)是连续、高维度向量,不太容易将其离散和在状态空间里枚举【对对对对!】 最近的工作一般都是利用 deep neural networks去表示高维度下的value function,[22][23]也直接将DRL运用于运动规划 但是他们专注于单个机器人在未知静止环境下的导航,而且一般计算的输入是传感器的数据(比如相机来的照片)
而我们的工作extend the collision avoidance with deep reinforcement learning framework (CADRL) 以在在多机器人系统中,识别与引入socially aware behaviours
B. Characterization of Social Norms
这是常见的social norms rule:
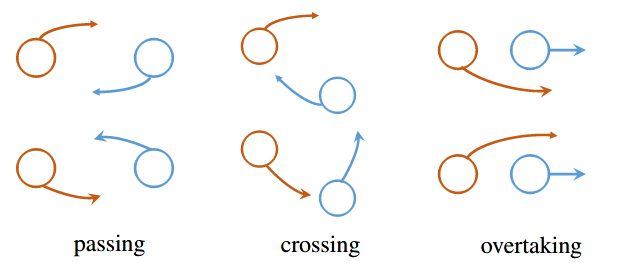
靠右行驶 passing,从左边超越 overtaking,
在对于social norms的定义中 直观上确实很难精确的确定细节转角等 when to turn and how much to turn with passing another one.
对比那些想量化人们行为的方法 本文则是将这些复杂 normative motion转为简单交互的结果。如果是两个采取同样避障策略的机器人在长廊相遇会保持同一条车道行驶,因此我们可以将social norms看成一种time-efficient, 互惠互利的避障原理
human navigation tends to be cooperative and time-efficient
所以CADRL就有这两个性质:
- min-time reward function
- reciprocity assumption \(\tilde\pi = \pi\)
图3展示了 CADRL整个协作的过程,因为 \(\mathbf{s}\) 是已知的,也就是一系列相关的 位置、速度、尺寸和目标点,所以一般是不会打破这个协作的默契。但是首先是agent都是CADRL下生成的,其次这个协作的行为是CADRL不能控制的 他是由value network的初始化和随机训练案例决定的 下一个部分我们会解决这个问题 去引导生成的行为是遵循人们的行为
III. Approach 方法
这一部分就是用DRL展示具有社会认知的multi-agents,首先要描述shaping normative behaviours在两个agents的环境中
A. Inducing Social Norms
回顾上面的强化学习optimal value function中,我们是将agent本身和其邻近的状态一起进行计算学习 \(\mathbf{s}^{jn} = [\mathbf{s},\tilde{\mathbf{s}}^o]\) scalar value that encodes the expected time to goal. 为了减少冗余 我们就使用local coordinate frame局部坐标系下的x轴指向目标,那么每一个agent的状态就可以参数化为:
其中
- \(d_g = \left\|\mathbf{p}_g-\mathbf{p}\right\|_2\) 是agent到目标之间的距离
- \(\tilde{d}_a = \left\|\mathbf{p}-\tilde{\mathbf{p}}\right\|_2\) 是与其他agent之间的距离
- \(\phi = tan^{-1}(\tilde{v}_y/\tilde{v}_x)\) 是agent的朝向问题
- \(\tilde{b}_{on}\) 是二进制flag表示这个agent是real or virtual
这一部分表明了social norms仅是解决这个问题的一种
【论文阅读】Socially aware motion planning with deep reinforcement learning-annotated的更多相关文章
- 论文阅读之: Hierarchical Object Detection with Deep Reinforcement Learning
Hierarchical Object Detection with Deep Reinforcement Learning NIPS 2016 WorkShop Paper : https://a ...
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- 论文笔记之:Playing Atari with Deep Reinforcement Learning
Playing Atari with Deep Reinforcement Learning <Computer Science>, 2013 Abstract: 本文提出了一种深度学习方 ...
- 论文笔记之:Human-level control through deep reinforcement learning
Human-level control through deep reinforcement learning Nature 2015 Google DeepMind Abstract RL 理论 在 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- 论文笔记之:Deep Reinforcement Learning with Double Q-learning
Deep Reinforcement Learning with Double Q-learning Google DeepMind Abstract 主流的 Q-learning 算法过高的估计在特 ...
随机推荐
- 在NVIDIA-Jetson平台上构建智能多媒体服务器
在NVIDIA-Jetson平台上构建智能多媒体服务器 Building a Multi-Camera Media Server for AI Processing on the NVIDIA Jet ...
- 使用TensorRT集成推理inference
使用TensorRT集成推理inference 使用TensorRT集成进行推理测试. 使用ResNet50模型对每个GPU进行推理,并对其它模型进行性能比较,最后与其它服务器进行比较测试. ResN ...
- Nucleus 实时操作系统中断(上)
Nucleus 实时操作系统中断(上) Interrupts in the Nucleus SE RTOS 所有现代微处理器和微控制器都有某种中断设施.这种能力对于提供许多应用程序所需的响应能力是必不 ...
- Python“九九乘法表”
用Python语言编程,使用双重循环语句输出"九九乘法表". for i in range(1, 10): # 控制行 for j in range(1, i+1): # 控制列 ...
- ConcurrentSkipListSet - 秒懂
疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 面试必备 + 面试必备 [博客园总入口 ] 疯狂创客圈 经典图书 : <Sprin ...
- NOIP模拟测试17「入阵曲·将军令·星空」
入阵曲 题解 应用了一种美妙移项思想, 我们先考虑在一维上的做法 维护前缀和$(sum[r]-sum[l-1])\%k==0$可以转化为 $sum[r]\% k==sum[l-1]\%k$开个桶维护一 ...
- Vue(6)v-on指令的使用
v-on 监听事件 可以用 v-on 指令监听 DOM 事件,并在触发时运行一些 JavaScript 代码.事件代码可以直接放到v-on后面,也可以写成一个函数.示例代码如下: <div id ...
- Kubernetes ConfigMap详解,多种方式创建、多种方式使用
我最新最全的文章都在南瓜慢说 www.pkslow.com,欢迎大家来喝茶! 1 简介 配置是程序绕不开的话题,在Kubernetes中使用ConfigMap来配置,它本质其实就是键值对.本文讲解如何 ...
- 快速串讲——JVM内存的区域划分
目的 快速定位JVM内存泄漏或者溢出等问题. 面试基础题,加分项. 文章持续更新,微信搜索「万猫学社」第一时间阅读,关注后回复「电子书」,免费获取12本Java必读技术书籍. 程序计数器(Progra ...
- 安聊服务端Netty的应用
Netty简介 Netty是一个面向网络编程的Java基础框架,它基于异步的事件驱动,并且内置多种网络协议的支持,可以快速地开发可维护的高性能的面向协议的服务器和客户端. 安聊简介 安聊是一个即时聊天 ...