Python爬取《你好李焕英》豆瓣短评并基于SnowNLP做情感分析
爬取过程在这里:
Python爬取你好李焕英豆瓣短评并利用stylecloud制作更酷炫的词云图
本文基于前文爬取生成的douban.txt,基于SnowNLP做情感分析。
依赖库:
豆瓣镜像比较快:
pip install snownlp -i http://pypi.douban.com/simple/ --trusted-host=pypi.douban.com/simple

初识SnowNLP:
SnowNLP是一个常用的Python文本分析库,是受到TextBlob启发而发明的。由于当前自然语言处理库基本都是针对英文的,而中文没有空格分割特征词,Python做中文文本挖掘较难,后续开发了一些针对中文处理的库,例如SnowNLP、Jieba、BosonNLP等。
Snownlp主要功能包括:
- 中文分词(算法是Character-Based Generative Model)
- 词性标注(原理是TnT、3-gram 隐马)
- 情感分析
- 文本分类(原理是朴素贝叶斯)
- 转换拼音、繁体转简体
- 提取文本关键词(原理是TextRank)
- 提取摘要(原理是TextRank)、分割句子
- 文本相似(原理是BM25)
情感分析实战:
SnowNLP情感分析是基于情感词典实现的,其简单的将文本分为两类,积极和消极,返回值为情绪的概率,也就是情感评分在[0,1]之间,越接近1,情感表现越积极,越接近0,情感表现越消极。
下面对爬取的豆瓣电影《你好李焕英》评论进行情感分析。
情感各分数段出现频率
首先统计各情感分数段出现的评率并绘制对应的柱状图。
对douban.txt文件逐行进行情感倾向值计算,代码如下:
1 # -*- coding: utf-8 -*-
2 # -*- coding: utf-8 -*-
3 from snownlp import SnowNLP
4 import matplotlib.pyplot as plt
5 import numpy as np
6
7 source = open("douban.txt","r", encoding='utf8')
8 line = source.readlines()
9 sentimentslist = []
10 for i in line:
11 s = SnowNLP(i)
12 print(s.sentiments)
13 sentimentslist.append(s.sentiments)
14
15
16 plt.hist(sentimentslist, bins = np.arange(0, 1, 0.01), facecolor = 'g')
17 plt.xlabel('Sentiments Probability')
18 plt.ylabel('Quantity')
19 plt.title('Analysis of Sentiments')
20 plt.show()
输出结果如下图所示:

对应的情感倾向值如下(部分):

情感波动分析
接下来分析评论,每条评论的波动情况,代码如下所示:
1 # -*- coding: utf-8 -*-
2 # 区间[0,1]
3 from snownlp import SnowNLP
4
5 import matplotlib.pyplot as plt
6 import numpy as np
7
8 source = open("douban.txt","r", encoding='utf8')
9 line = source.readlines()
10 sentimentslist = []
11 for i in line:
12 s = SnowNLP(i)
13 print(s.sentiments)
14 sentimentslist.append(s.sentiments)
15
16
17 plt.plot(np.arange(0, 166, 1), sentimentslist, 'b-')
18 plt.xlabel('Number')
19 plt.ylabel('Sentiment')
20 plt.title('Analysis of Sentiments')
21 plt.show()
输出结果如下所示,接近1.0代表好评,可以看出好评率很高。

改进
将情感区间从[0, 1.0]转换为[-0.5, 0.5],这样的曲线更加直观,位于0以上的是积极评论,反之消极评论。
修改代码如下:
1 # -*- coding: utf-8 -*-
2 import matplotlib.pyplot as plt
3 import numpy as np
4
5 from snownlp import SnowNLP
6
7
8 #获取情感分数
9 source = open("douban.txt","r", encoding='utf8')
10 line = source.readlines()
11 sentimentslist = []
12 for i in line:
13 s = SnowNLP(i)
14 print(s.sentiments)
15 sentimentslist.append(s.sentiments)
16
17 #区间转换为[-0.5, 0.5]
18 result = []
19 i = 0
20 while i<len(sentimentslist):
21 result.append(sentimentslist[i]-0.5)
22 i = i + 1
23
24 #可视化画图
25
26 plt.plot(np.arange(0, 166, 1), result, 'r-')
27 plt.xlabel('Number')
28 plt.ylabel('Sentiment')
29 plt.title('Analysis of Sentiments')
30 plt.show()
绘制图形如下所示:
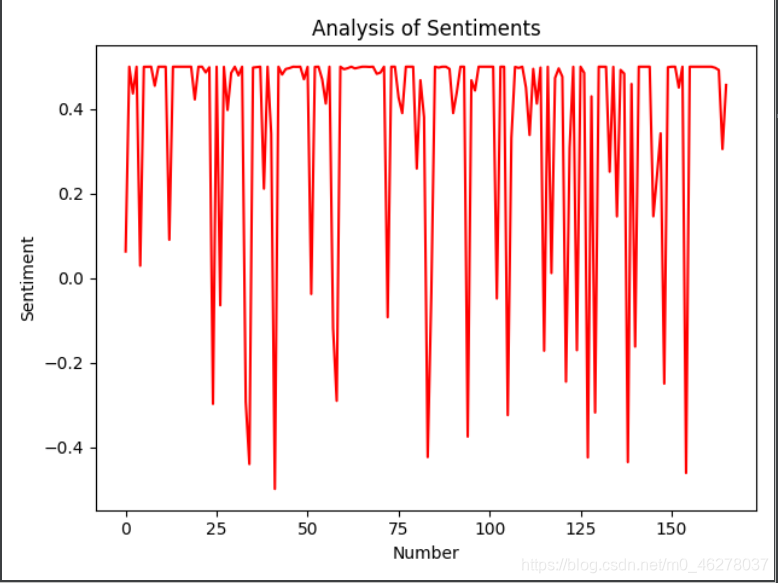
可以看到0以上好评的远远超出差评。
爬取猫眼电影,此刻的《你好李焕英》票房已经超过46忆!!!


Python爬取《你好李焕英》豆瓣短评并基于SnowNLP做情感分析的更多相关文章
- 我用Python爬取了李沧最近一年多的二手房成交数据得出以下结论
前言 去年年底,博主有购房的意愿,本来是打算在青岛市北购房,怎奈工作变动,意向转移到了李沧,坐等了半年以后,最终选择在红岛附近购置了期房. 也许一些知道青岛红岛的小伙伴会问我,为什么会跑到那鸟不拉屎的 ...
- Python爬取《冰雪奇缘2》豆瓣影评
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 刘铨@CCIS Lab PS:如有需要Python学习资料的小伙伴可 ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- python爬取《龙岭迷窟》的数据,看看质量剧情还原度到底怎么样
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:简单 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行 ...
- python爬取信息到数据库与mysql简单的表操作
python 爬取豆瓣top250并导入到mysql数据库中 import pymysql import requests import re url='https://movie.douban.co ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
随机推荐
- AlexeyAB DarkNet YOLOv3框架解析与应用实践(三)
AlexeyAB DarkNet YOLOv3框架解析与应用实践(三) ImageNet分类 您可以使用Darknet为1000级ImageNet挑战赛分类图像.如果你还没有安装Darknet,你应该 ...
- springboot2.x整合tkmapper
springboot整合tkmapper 1.导入pom依赖 1.1 导入springboot的parent依赖 <parent> <artifactId>spring-boo ...
- python+requests接口用例
本实例通过请求接口登录系统,获取了配置项的ID,并最终实现了对配置项的默认值进行修改 使用到的接口请求方法有:get(查询) ,post(新增),put(修改) 遇到的阻碍点见下面具体代码处的详解 编 ...
- DB2 SQL0805N解决和思考
一.报错现象 这是一个在使用 DB2数据库过程中比较常见的错误, 报错信息如下 Exception stack trace: com.ibm.db2.jcc.am.SqlException: DB2 ...
- WPF添加外边框,添加外边框虚线
<Border Background="LightBlue" BorderBrush="Black" BorderThickness="2&q ...
- Java知识复习(三)
Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?用contains来区分是否有重复的对象.还是都不用. 在比较时先调用hashCode方法, ...
- gRPC(2):四种基本通信模式
在 gRPC(1):入门及简单使用(go) 中,我们实现了一个简单的 gRPC 应用程序,其中双方通信是简单的请求-响应模式,没发出一个请求都会得到一个响应,然而,借助 gRPC 可以实现不同的通信模 ...
- Redis6使用指导(完整版)
一.Nosql与Redis概述 二.Redis6安装 三.常用五大数据类型 四.Redis6配置文件详解 五.Redis6的发布和订阅 六.Redis6新数据类型 七.Jedis操作Redis6(Ma ...
- 『心善渊』Selenium3.0基础 — 16、Selenium对iframe表单的操作
目录 1.什么是iframe表单 2.iframe表单操作流程 3.iframe表单操作常用方法 (1)进入表单 (2)多表单切换 4.表单操作示例 1.什么是iframe表单 实际上就是HTML页面 ...
- 广州小公司:List集合你是熟悉的,对吧?
<对线面试官>系列目前已经连载27篇啦!有深度风趣的系列! [对线面试官]Java注解 [对线面试官]Java泛型 [对线面试官] Java NIO [对线面试官]Java反射 & ...