JDBC 连接DRUID 连接池!
一、1.创建一个floder目录,【名称lib】
2. 导入mysql.jar包和 druid.jar 包。---------->bulid path
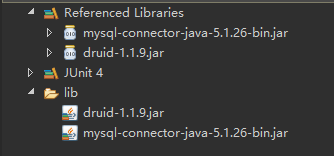
二、创建 sourcefolder 目录!【sourcefloder】
将配置文件放到里面(这种类型的文件夹和普通文件夹不一样,sourcefloder文件夹能将里面的东西编译到输出目录,而普通文件夹不会编译)
展示配置文件

三、通过连接池来连接JDBC,更改Util工具中的 getConnection!
四、总的展示。
package com.aaa.util; import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties; import javax.sql.DataSource; import com.alibaba.druid.pool.DruidDataSourceFactory; /**
* BaseDao 利用Druid连接池 连接数据库
*
* 通过连接池,不用每次都建立连接对象和关闭资源,节省资源。
* 需要
* 1.导入druid包
* 2.创建一个source floder文件夹 将配置文件 druid.properties 放在里面。
*/
public class BaseDAO { private static DataSource source=null;//注意这里是私有,静态变量。 static {//这里还是之前的加载驱动
Properties p = new Properties();
try {
//加载文件 得到一个 druid.properties 的文件。
p.load(BaseDAO.class.getClassLoader().getResourceAsStream("druid.properties")); //获取数据源
source=DruidDataSourceFactory.createDataSource(p); } catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} //建立连接
public static Connection getConnetion() {
try {
//利用连接池连接对象
Connection con = source.getConnection();
return con;
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
} // DML 增删改的通用
public static int exectueUpdate(String sql,Object...args) {
Connection con=null;
PreparedStatement ps=null; try {
con = BaseDAO.getConnetion();
ps=con.prepareStatement(sql); for (int i = 0; i < args.length; i++) {
ps.setObject(i+1, args[i]);
} int i = ps.executeUpdate(); return i; } catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
try {
if (ps!=null) {
ps.close();
}
if (con!=null) {
con.close();
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} return 0;
} //DQL 查询的通用
public static List<Map<String, Object>> executeQuery(String sql,Object...args) {
Connection con=null;
PreparedStatement ps=null;
ResultSet rs=null; try {
con = BaseDAO.getConnetion(); //注意这里是用source 来调用 getConnetion ,不再是通过BaseDAO
ps = con.prepareStatement(sql); for (int i = 0; i < args.length; i++) {
ps.setObject(i+1, args[i]);
} rs = ps.executeQuery(); int count = rs.getMetaData().getColumnCount(); List<Map<String, Object>> list=new ArrayList<>();
while (rs.next()) {
Map<String, Object>map=new HashMap<>(); for (int i = 0; i < count; i++) {
Object values = rs.getObject(i+1);
String countName = rs.getMetaData().getColumnLabel(i+1);
map.put(countName, values);
} list.add(map); // System.out.println(list);
}
for (Map<String, Object> map : list) {
System.out.println(map);
} return list;
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} return null;
}
}
JDBC 连接DRUID 连接池!的更多相关文章
- Spring整合JDBC和Druid连接池
我的博客名为黑客之谜,喜欢我的,或者喜欢未来的大神,点一波关注吧!顺便说一下,双十二快到了,祝大家双十二快乐,尽情的买买买~ 如果转载我的文章请标明出处和著名,谢谢配合. 我的博客地址为: https ...
- 常用的jdbc的Druid连接池配置
spring: datasource: username: root password: 888888 url: jdbc:mysql://localhost:3306/mybatis driver- ...
- Spring Boot (四): Druid 连接池密码加密与监控
在上一篇文章<Spring Boot (三): ORM 框架 JPA 与连接池 Hikari> 我们介绍了 JPA 与连接池 Hikari 的整合使用,在国内使用比较多的连接池还有一个是阿 ...
- java基础之JDBC八:Druid连接池的使用
基本使用代码: /** * Druid连接池及简单工具类的使用 */ public class Test{ public static void main(String[] args) { Conne ...
- druid连接池获取不到连接的一种情况
数据源一开始配置: jdbc.initialSize=1jdbc.minIdle=1jdbc.maxActive=5 程序运行一段时间后,执行查询抛如下异常: exception=org.mybati ...
- druid连接池配置
本人使用的是springMVC框架,以下是我的配置: step1,配置数据源(applicationContext-resource.xml中): <bean id="cc_ds&qu ...
- 使用druid连接池的超时回收机制排查连接泄露问题
在工程中使用了druid连接池,运行一段时间后系统出现异常: Caused by: org.springframework.jdbc.CannotGetJdbcConnectionException: ...
- Druid连接池
Druid 连接池简介 Druid首先是一个数据库连接池.Druid是目前最好的数据库连接池,在功能.性能.扩展性方面,都超过其他数据库连接池,包括DBCP.C3P0.BoneCP.Proxool.J ...
- 使用MyBatis集成阿里巴巴druid连接池(不使用spring)
在工作中发现mybatis默认的连接池POOLED,运行时间长了会报莫名其妙的连接失败错误.因此采用阿里巴巴的Druid数据源(码云链接 ,中文文档链接). mybatis更多数据源参考博客链接 . ...
随机推荐
- 1016 - Brush (II)
1016 - Brush (II) PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: 32 MB Afte ...
- 倍福CX5120嵌入式控制器使用教程
1.新建工程 新建TwinCAT XAE Project 2.连接设备 点击SYSTEM,再点击"Change Target..." 在弹出的"choose Targt ...
- [Elasticsearch] ES聚合场景下部分结果数据未返回问题分析
背景 在对ES某个筛选字段聚合查询,类似groupBy操作后,发现该字段新增的数据,聚合结果没有展示出来,但是用户在全文检索新增的筛选数据后,又可以查询出来, 针对该问题进行了相关排查. 排查思路 首 ...
- [高数]高数部分-Part II 导数与微分
Part II 导数与微分 回到总目录 Part II 导数与微分 一元函数微分的定义 一元函数定义注意点 基本求导公式 基本求导方法 复合函数求导 隐函数求导 对数求导法 反函数求导 参数方程求导 ...
- centos一步一步搭建tendermint
一.必要条件 1.安装go 请根据官方文档安装:https://golang.org/doc/install 要特别注意的是: /etc/profile 添加以下内容: export GOPATH=/ ...
- rsync配置文件讲解
1.安装rysnc 一般在安装系统时rsync是安装上(yum安装) 2. vim /etc/xinetd.d/rsync 在这个路径下有配置文件 service rsync { disabl ...
- MySQL存储过程入门基础
创建存储过程无参语法: delimiter // create procedure 函数名() begin 业务逻辑 end // call 函数名() 通过函数名调用存储过程 创建存储过程有参与法: ...
- VMware桥接模式连接局域网和互联网
第一步:确认本地网关地址 第二步选择桥接模式: 我比较幸运,桥接到"自动",就已经连接成功.不用逐个试错. 修改 ifcfg-ens33 和 新建 ifcfg-br0 [root@ ...
- MongoDB之几种情况下的索引选择策略
一.MongoDB如何选择索引 如果我们在Collection建了5个index,那么当我们查询的时候,MongoDB会根据查询语句的筛选条件.sort排序等来定位可以使用的index作为候选索引:然 ...
- kafka时间轮简易实现(二)
概述 上一篇主要介绍了kafka时间轮源码和原理,这篇主要介绍一下kafka时间轮简单实现和使用kafka时间轮.如果要实现一个时间轮,就要了解他的数据结构和运行原理,上一篇随笔介绍了不同种类的数据结 ...