《Flink SQL任务自动生成与提交》后续:修改flink源码实现kafka connector BatchMode
因为在一篇博文上看到介绍“汽车之家介绍flink数据平台”中提到“基于 SQL 的开发流程”。基于kafka connector,通过source,sink,transformation三条sql完成数据接入,逻辑转换处理,结果落地三步工作。出于兴趣,自己去简(粗)单(糙)实现了这其中的一个小功能。相关的博文在这里,相关的代码上传到github。
简单说,通过kafka connector用3条sql实现如图所示功能:
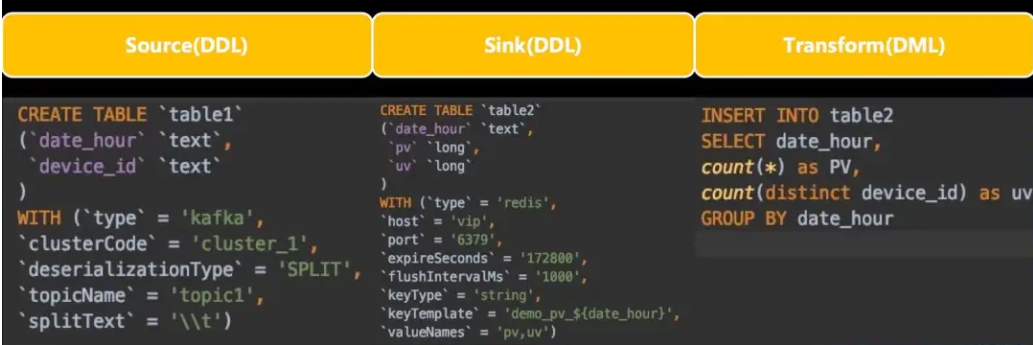
但是实现的过程中也遇到了两个问题。
问题
- 截止到目前最新的flink版本在kafka connector也只支持
inStreamingMode,并不支持inBatchMode。不能实现汽车之家通过kafka connector来实现每日的定时统计。
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/kafka/
如图,只支持unbounded无界数据流,不支持bounded有界数据即batchmode.

在sink的时候是只支持append模式,而在append模式下,不支持group by,因为使用了group by 会改行结果行。
那么按照汽车之家每日统计PV,UV的需求必然需要使用到group by.按目前flink的最新版本也是办不到的。
如果强行使用group by 将会抛出异常:
目前sink只支持append模式,如果使用了group by 等会改变结果行,会报错:AppendStreamTableSink doesn't support consuming update changes which is produced by node GroupAggregate
对于spark和flink这种绝对主流的大数据框架,稍微上点规模的公司应该都有维护自己的内部分支,基于自家的业务做一些定制化开发。汽车之家应该也不例外。
所以以上功能flink社区版不能做到,汽车之家应该是基于内部的实现。
以上是背景介绍。
基于该功能并不算特别复杂,花了两天业余时间实现了。
思路
kafka参数问题
要接入kafka,就要设置kafka连接信息,起始信息,以及
结束信息.开始信息可选参数如下:
参数名 参数值 scan.startup.mode 可选值:'earliest-offset', 'latest-offset', 'group-offsets', 'timestamp' and 'specific-offsets' scan.startup.specific-offsets 指定每个分区的偏移量,比如:'partition:0,offset:42;partition:1,offset:300' scan.startup.timestamp-millis 直接指定开始时间戳,long类型 依葫芦画瓢,去除
earliest-offset,结束信息可选参数可设置成:参数名 参数值 scan.endup.mode 可选值:'latest-offset', 'group-offsets', 'timestamp' and 'specific-offsets' scan.endup.specific-offsets 指定每个分区的偏移量,比如:'partition:0,offset:42;partition:1,offset:300' scan.sendup.timestamp-millis 直接指定结束时间戳,long类型 支持batchmode的问题
这里涉及到一个版本的问题。flink kafka connector API在最近几个版本变化挺大的。就内部实现而言,1.13和1.14也有不小的变化。
比如,判断当前任务是否有界时,1.13版本是直接写为
false

而在1.14版本变成了可动态判断并设置
public boolean isBounded() { return kafkaSource.getBoundedness() == Boundedness.BOUNDED; }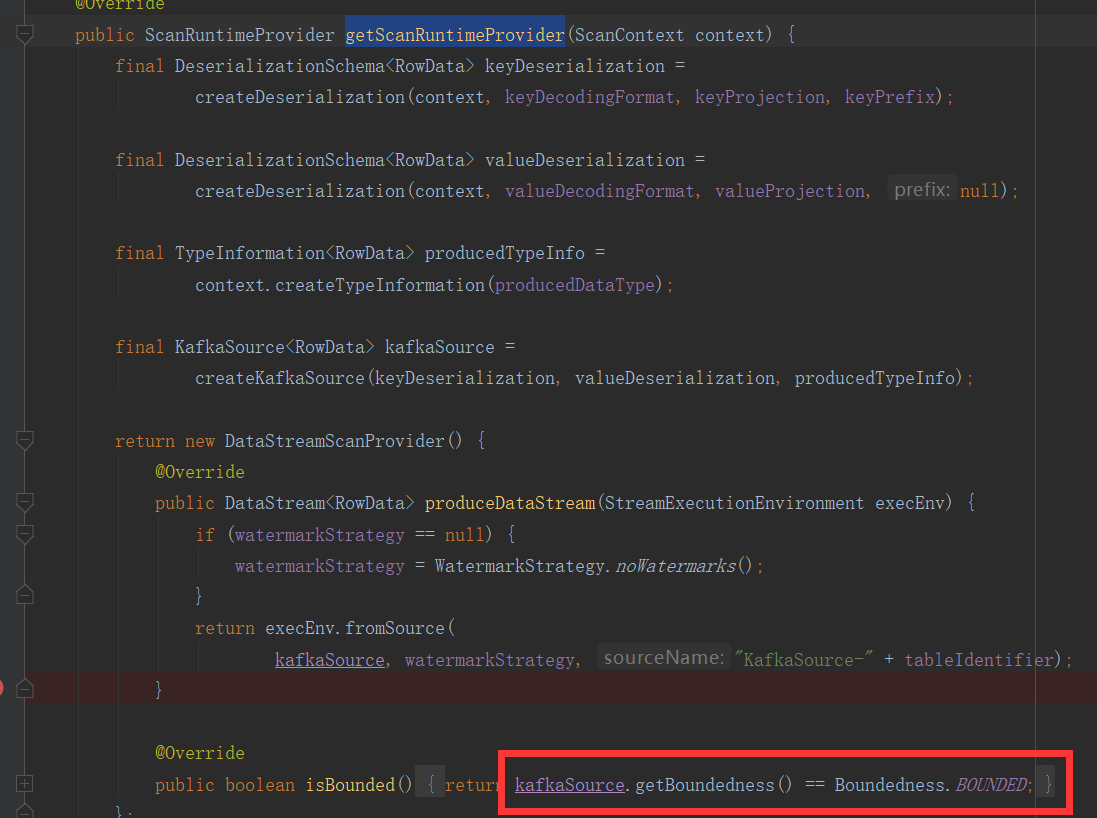
可以看到这里通过
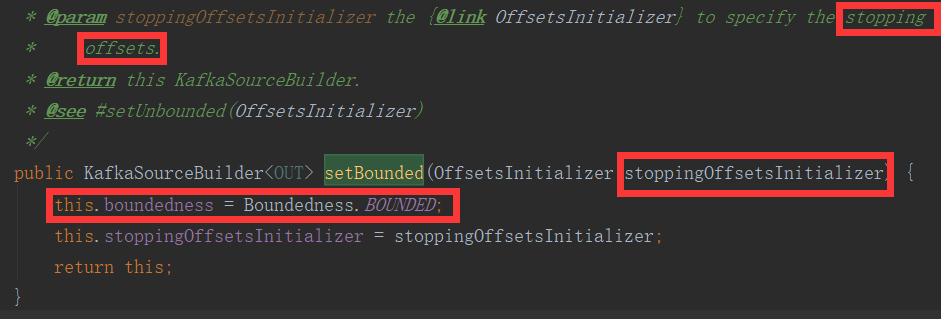
kafkaSource.getBoundedness()获取当前任务是否有界,点进KafkaSource,对于boundedness属性,既然有getter那必然有setter啊。果不其然,在
KafkaSourceBuilder类中提供了setBounded方法。这里还有意外惊喜,这个方法不但提供了设置bounded的功能,还能直接设置结束的参数。那么上一个
kafka参数问题解决了定义问题,而在这里就解决了设置的问题。
参数提交至kafkasource的问题
参数问题分为
定义和提交。定义在第1部份已经解决,提交就是第2部份的setBounded,但在哪里触发呢?在
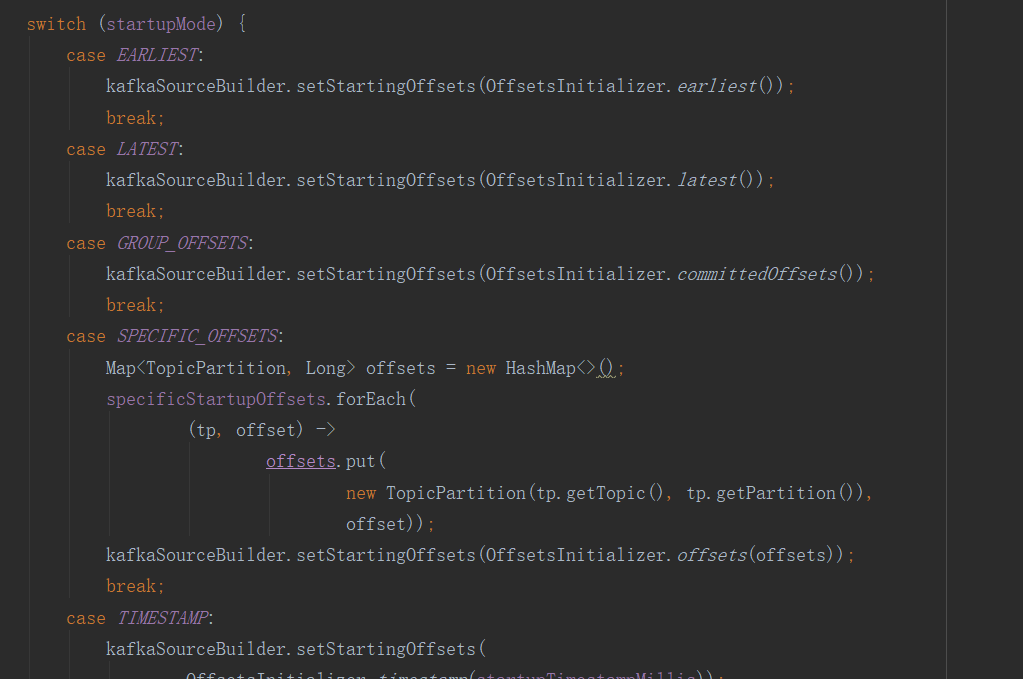
KafkaDynamicSource.createKafkaSource的方法里。这里可仿照switch(startupMode)写一个switch(endupuMode),在里面的分支去实现各种参数情况LATEST,TIMESTAMP,再在各个分支里设置kafka参数。在case分支我们可以仿照
kafkaSourceBuilder.setStartingOffsets实现一个kafkaSourceBuilder.setEndOffsets。在flink 1.13就得这么实现。但在flink 1.14,经过前面的分析得知setBounded可设置结束参数。一举两得。
group by支持问题
经过分析,我发现这个问题属于是庸人自扰。
AppendStreamTableSink doesn't support group by仅在streamingmode模式下,batchmode不存在改变结果行的问题,所以,只要改成了batchmode,天然的就不存在group by 异常问题。
实现
选定flink 1.14版本,fork,拉取到本地,新建分支。
目前scan.endup.mode 只支持latest-offset和timestamp两种方式。
具体实现细节,就不一一贴代码了,有凑字数之嫌。
有兴趣实现细节的,可以查看这两个commit记录。大致就是这些改动。完成代码:
编译
代码实现完毕,本地编译。
使用maven,常规操作。有两个注意的点:
flink使用了
spotless进行代码格式化检测。修改了源码重新编译如果代码格式不对,可能就是没换行或者少了多了一个空格,就通过不了。编译前,可以使用
'mvn spotless:apply自动校正。flink 使用了
Checkstyle,一些代码使用了import static,添加静态引入后进行编译时要注意。
测试
编译成功后,可部署成单点或者伪集群模式测试。
这里采用本地测试。
- 将
flink-connector-kafka_2.11-1.14.0.jar和flink-connector-kafka_2.11-1.14.0.xmlpom文件手动放入或者mvn install本地仓库。 - 我测试的时候,需手动引用kafka-clients依赖。这点我不保证。
确保将重新编译后的jar包引入项目
测试代码:
{
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()
.inBatchMode()
// .inStreamingMode()
.build();
TableEnvironment te = TableEnvironment.create(fsSettings);
String kafkaSql = "CREATE TABLE kafkatable (\n" +
" key STRING," +
" ts TIMESTAMP" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'xxx',\n" +
" 'properties.bootstrap.servers' = 'xxx.xx.xxx.xxx:9092',\n" +
" 'properties.group.id' = 'xxx',\n" +
// -- optional: valid modes are "earliest-offset",
// -- "latest-offset", "group-offsets",
// -- or "specific-offsets"
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'scan.endup.mode' = 'latest-offset',\n" +
// " 'scan.endup.mode' = 'timestamp',\n" +
// " 'scan.endup.timestamp-millis' = '1641974234163',\n" +
// " 'scan.endup.mode' = 'latest-offset',\n" +
// "'scan.startup.specific-offsets' = 'partition:0,offset:20'," +
// " 'connector.specific-offsets.0.partition' = '0',"+
// "'connector.specific-offsets.0.offset' = '1',"+
" 'format' = 'json',\n" +
" 'json.fail-on-missing-field' = 'false',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")";
te.executeSql(kafkaSql);
String sqlFile = "CREATE TABLE fs_table (\n" +
" dt VARCHAR,\n" +
" pv BIGINT,\n" +
" uv BIGINT" +
") WITH (\n" +
" 'connector'='filesystem',\n" +
" 'path'='d://path',\n" +
" 'format'='json',\n" +
" 'sink.partition-commit.delay'='1 s',\n" +
" 'sink.partition-commit.policy.kind'='success-file'\n" +
")";
te.executeSql(sqlFile);
te.executeSql("INSERT INTO fs_table\n" +
"SELECT\n" +
" 'as' as dt,\n" +
" COUNT(*) AS pv,\n" +
" COUNT(DISTINCT key) AS uv\n" +
"FROM kafkatable group by key\n").print();
}
测试代码的sql逻辑仅为测试。不要追究为什么count(*)是pv,随手写的。
测试代码
scan.endup.mode设置为latest-offset。如果要实现最开始的按天统计,如下设置。scan.startup.mode同理。
" 'scan.endup.mode' = 'timestamp',\n" +
" 'scan.endup.timestamp-millis' = '1641974234163',\n" +
这段代码测试通过inBatchMode引入kafka数据源,并将处理后的数据写入本地文件。
运行结果,测试通过。
完
《Flink SQL任务自动生成与提交》后续:修改flink源码实现kafka connector BatchMode的更多相关文章
- Flink SQL任务自动生成与提交
目录 起因 思路 实现 1.配置 2.界面如下 3.环境 问题 起因 事情的起因,是看到一篇公众号文章Apache Flink 在汽车之家的应用与实践,里面提到了"基于 SQL 的开发流程& ...
- Excel 数据导入SQL XML 自动生成表头
去出差的时候应客户要求要要将Excel 文件内的数据批量导入到数据库中,而且有各种不同种类的表格,如果每一个表格多对应一个数据表的话, 按照正常的方法应该是创建数据表,创建数据库中映射的数据模型,然后 ...
- Entity Framewrok 7beta7中不同版本sql server自动生成分页sql语句的问题
在EF中,使用linq进行分页是很方便的,假如我们有一个EMP表,结构如下: public class Emp { [Key] public Guid No { get; set; } public ...
- Springboot+Redisson自定义注解一次解决重复提交问题(含源码)
前言 项目中经常会出现重复提交的问题,而接口幂等性也一直以来是做任何项目都要关注的疑难点,网上可以查到非常多的方案,我归纳了几点如下: 1).数据库层面,对责任字段设置唯一索引,这是最直接有效 ...
- 学习 opencv---(6)玩转opencv源代码:生成opencv 工程解决方案与opencv 源码编译
在这篇中,我们探讨如何通过已安装的opencv选择不同的编译器类型,生成高度还原的OpenCV开发时的解决方案工程文件,欣赏OpenCV新版本中总计 六十六多万行的精妙源代码.我们可以对其源代码进行再 ...
- Android 二维码 生成和识别(附Demo源码)
今天讲一下目前移动领域很常用的技术——二维码.现在大街小巷.各大网站都有二维码的踪迹,不管是IOS. Android.WP都有相关支持的软件.之前我就想了解二维码是如何工作,最近因为工作需要使用相关技 ...
- 【转】Android 二维码 生成和识别(附Demo源码)--不错
原文网址:http://www.cnblogs.com/mythou/p/3280023.html 今天讲一下目前移动领域很常用的技术——二维码.现在大街小巷.各大网站都有二维码的踪迹,不管是IOS. ...
- 【转载】Redis 4.0 自动内存碎片整理(Active Defrag)源码分析
click原文链接原文链接:https://blog.csdn.net/zouhuajianclever/article/details/90669409阅读本文前建议先阅读此篇博客: Redis源码 ...
- Spring Framework自动装配setAutowireMode和Mybatis案例的源码探究
由前文可得知, Spring Framework的自动装配有两种方式:xml配置和注解配置: 自动装配的类型有: (1)xml配置中的byType根据类型查找(@Autowired注解是默认根据类型查 ...
随机推荐
- Java值引用和对象引用区别Demo
转自:http://blog.csdn.net/gundsoul/article/details/4927404 以前就知道JAVA对象分对象引用和值引用,并且还知道8种基础数据类型,即引用时是值引用 ...
- js--对象内部属性与 Object.defineProperty()
前言 JavaScript 中允许使用一些内部特性来描述属性的特征,本文来总结一下对象内部属性与 Object.defineProperty() 的相关知识. 正文 1.属性类型 js中使用某些内部属 ...
- 删除…Remove…(Power Query 之 M 语言)
删除行(表): 删除指定行:=Table.RemoveRows( 表, 起始行数, 删除的行数) 起始行数从0开始计 删除前面N-.Skip/RemoveFirstN 删除后面N-.RemoveLas ...
- LuoguP5139 z小f的函数 题解
Content 给定 \(T\) 个二次函数 \(y=ax^2+bx+c\),有若干次操作,有一个操作编号 \(p\),保证仅为以下这五种: 操作 \(1\):给定 \(k\),将函数图像向上移动 \ ...
- CF53C Little Frog 题解
Content 有一只小青蛙想游历 \(n\) 块土堆,它现在在 \(1\) 号土堆上,每次可以跳跃任意距离到达另外的一个土堆.它想让每次跳跃的距离都不相等,试找到这样的一个方案. 数据范围:\(1\ ...
- 如何把myeclipse的工程导入到svn服务器上
如何把myeclipse的工程导入到svn服务器上,按照如下步骤便可
- MySQL查看数据库连接数
mysql> show status like 'Threads%' -> ; +-------------------+-------+ | Variable_name | Value ...
- 【LeetCode】999. Available Captures for Rook 解题报告(C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 四方向搜索 日期 题目地址:https://leetc ...
- 【LeetCode】800. Similar RGB Color 解题报告(C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 遍历 日期 题目地址:https://leetcode ...
- 【LeetCode】486. Predict the Winner 解题报告(Python)
[LeetCode]486. Predict the Winner 解题报告(Python) 标签(空格分隔): LeetCode 作者: 负雪明烛 id: fuxuemingzhu 个人博客: ht ...