Databend 设计概述 | 白皮书
Databend 是一个开源的、完全面向云架构的新式数仓,它提供快速的弹性扩展能力,并结合云的弹性、简单性和低成本,使 Data Cloud 构建变得更加容易。
Databend 把数据存储在像 AWS S3 ,Azure Blob 这些云上的存储系统,可以使不同的计算节点挂载同一份数据,从而做到较高的弹性,实现对资源的精细化控制。
Databend 在设计上专注以下能力:
- 弹性 在 Databend 中,存储和计算资源可以按需、按量弹性扩展。
- 安全 Databend 中数据文件和网络传输都是端到端加密,并在 SQL 级别提供基于角色的权限控制。
- 易用 Databend 兼容 ANSI SQL,并可以使用 MySQL 和 ClickHouse 客户端接入,几乎无学习成本。
- 成本 Databend 处理查询非常高效,用户只需要为使用的资源付费。
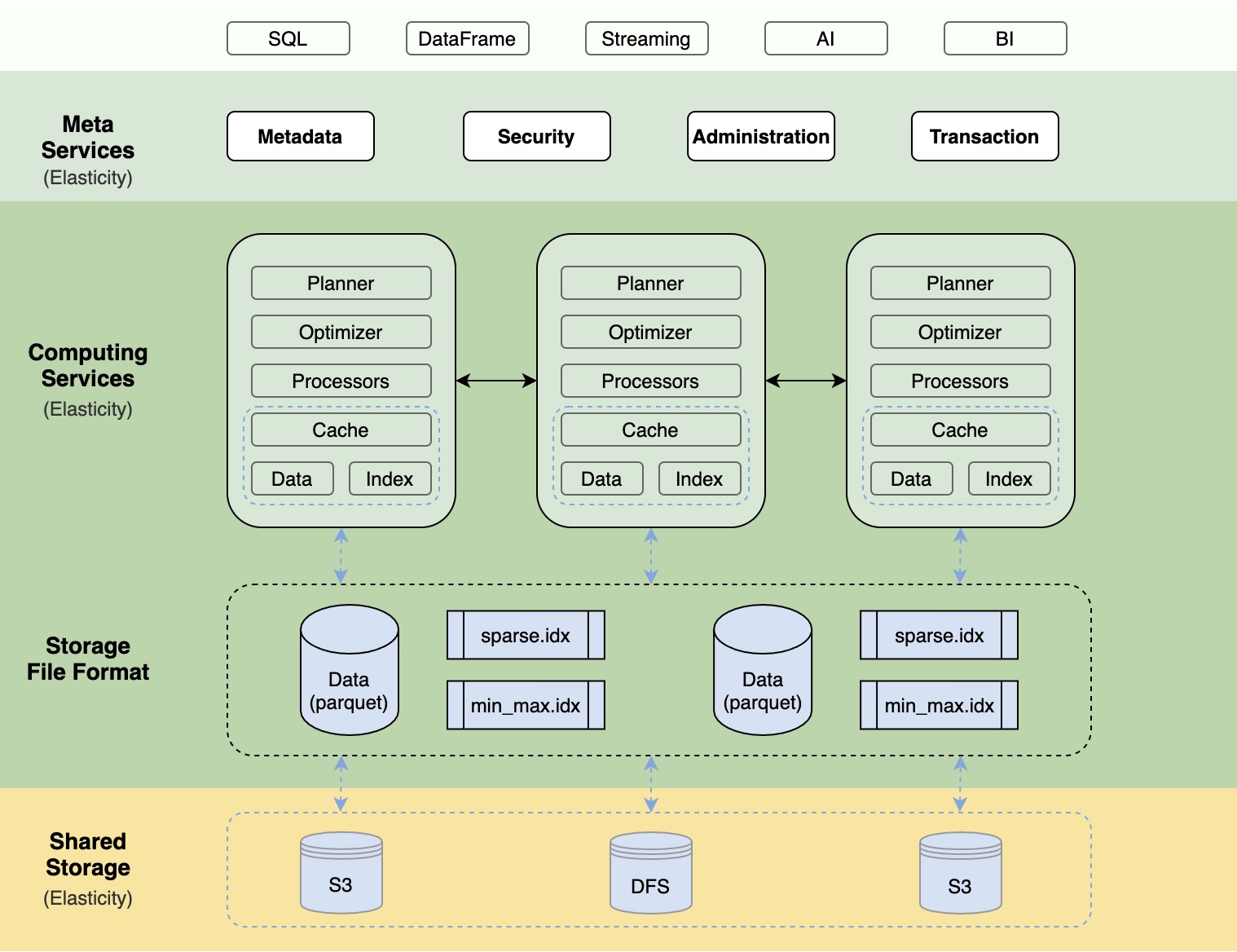
上图是 Databend 的整体架构图,整个系统主要由三大部分组成:Meta service layer、Compute Layer 和 Storage Layer。
1、Meta Service Layer
- Meta Service 是一个多租户、高可用的分布式 key-value 存储服务,具备事务能力,主要用于存储:
- Metadata : 表的元信息、索引信息、集群信息、事务信息等。
- Administration:用户系统、用户权限等信息。
- Security :用户登录认证、数据加密等。
2、Compute Layer
计算层由多个集群(cluster)组成,不同集群可以承担不同的工作负载,每个集群又有多个计算节点(node)组成,你可以轻松的添加、删除节点或集群,做到资源的按需、按量管理。
计算节点是计算层的最小构成单元,其中每个计算节点包含以下几个组件:
执行计划 (Planner)
根据用户输入的 SQL 生成执行计划,它只是个逻辑表达,并不能真正的执行,而是用于指导整个计算流水线(Pipeline)的编排与生成。
比如语句
SELECT number + 1 FROM numbers_mt(10) WHERE number > 8 LIMIT 2
执行计划:
databend :) EXPLAIN SELECT number + 1 FROM numbers_mt(10) WHERE number > 8 LIMIT 2
┌─explain────────────────────────────────────────────────────────────────────────────────────────────┐
│ Limit: 2 │
│ Projection: (number + 1):UInt64 │
│ Expression: (number + 1):UInt64 (Before Projection) │
│ Filter: (number > 8) │
│ ReadDataSource: scan partitions: [1], scan schema: [number:UInt64], statistics: [read_rows: 10, read_bytes: 80] │
└────────────────────────────────────────────────────────────────────────────────────────────────┘
这个执行计划自下而上分别是 :
ReadDataSource:表示从哪些文件里读取数据
Filter: 表示要做 (number > 8) 表达式过滤
Expression: 表示要做 (number + 1) 表达式运算
Projection: 表示查询列是哪些
Limit: 表示取前 2 条数据
优化器 (Optimizer)
对执行计划做一些基于规则的优化(A Rule Based Optimizer), 比如做一些谓词下推或是去掉一些不必要的列等,以使整个执行计划更优。
处理器 (Processors)
处理器(Processor)是执行计算逻辑的核心组件。根据执行计划,处理器们被编排成一个流水线(Pipeline),用于执行计算任务。
整个 Pipeline 是一个有向无环图,每个点是一个处理器,每条边由处理器的 InPort 和 OutPort 相连构成,数据到达不同的处理器进行计算后,通过边流向下一个处理器,多个处理器可以并行计算,在集群模式下还可以跨节点分布式执行,这是 Datafuse 高性能的一个重要设计。
例如,我们可以通过 EXPLAIN PIPELINE 来查看:
databend :) EXPLAIN PIPELINE SELECT number + 1 FROM numbers_mt(10000) WHERE number > 8 LIMIT 2
┌─explain───────────────────────────────────────────────────────────────┐
│ LimitTransform × 1 processor │
│ Merge (ProjectionTransform × 16 processors) to (LimitTransform × 1) │
│ ProjectionTransform × 16 processors │
│ ExpressionTransform × 16 processors │
│ FilterTransform × 16 processors │
│ SourceTransform × 16 processors │
└───────────────────────────────────────────────────────────────────────┘
同样,理解这个 Pipeline 我们自下而上来看:
- SourceTransform:读取数据文件,16 个物理 CPU 并行处理
- ilterTransform:对数据进行 (number > 8) 表达式过滤,16 个物理 CPU 并行处理
- pressionTransform:对数据进行 (number + 1) 表达式执行,16 个物理 CPU 并行处理
- ojectionTransform:对数据处理生成最终列
- LimitTransform:对数据进行 Limit 2 处理,Pipeline 进行折叠,由一个物理 CPU 来执行
- Databend 通过 Pipeline 并行模型,并结合向量计算最大限度的去压榨 CPU 资源,以加速计算。
缓存 ( Cache )
计算节点使用本地 SSD 缓存数据和索引,以提高数据亲和性来加速计算。
缓存的预热方式有:
LOAD_ON_DEMAND - 按需加载索引或数据块(默认)。
LOAD_INDEX - 只加载索引。
LOAD_ALL - 加载全部的数据和索引,对于较小的表可以采取这种模式。
3. Storage Layer
Databend 使用 Parquet 列式存储格式来储存数据,为了加快查找(Partition Pruning),Databend 为每个 Parquet 提供了自己的索引(根据 Primary Key 生成):
min_max.idx Parquet 文件 minimum 和 maximum 值
sparse.idx 以 N 条记录为颗粒度的稀疏索引
通过这些索引, 我们可以减少数据的交互,并使计算量大大减少。
假设有两个Parquet 文件:f1, f2,f1 的 min_max.idx: [3, 5] ;f2 的 min_max.idx: [4, 6] 。如果查询条件为:where x < 4 , 我们只需要 f1 文件就可以,再根据 sparse.idx 索引定位到 f1 文件中的某个数据页。
项目地址
代码地址:
https://github.com/datafuselabs/databend
项目官网:
https://datafuse.rs
想了解我们更多可以关注公众号: Databend .
Databend 设计概述 | 白皮书的更多相关文章
- Android设计 - 图标设计概述(Iconography)
2014-10-30 张云飞VIR 翻译自:https://developer.android.com/design/style/iconography.html Iconography 图标设计概述 ...
- HTML&CSS精选笔记_HTML与CSS网页设计概述
HTML与CSS网页设计概述 Web基本概念 认识网页 网页主要由文字.图像和超链接等元素构成.当然,除了这些元素,网页中还可以包含音频.视频以及Flash等. 名词解释 Internet网络 就是通 ...
- Axure学习笔记1--原型设计概述
Axure原型 1.原型的出现 -软件功能复杂,用户需求多 -挖掘用户的实际需求 -项目组之间降低沟通成本 2.类型: [草图原型]描述产品大概需求,记录瞬间灵感 [低保真原型]展示系统的大致结构和基 ...
- Power Gating的设计(概述)
Leakage power随着CMOS电路工艺进程,功耗越来越大. Power Domain的开关一般通过硬件中的timer和系统层次的功耗管理软件来进行控制,需要在一下几方面做trade-off: ...
- UML+模式设计概述
转自于:http://blog.csdn.net/rexuefengye/article/details/13020225 工程学:工程庞大到一定程度必须是用工程学方法,好比直接用水泥沙子建设实用的摩 ...
- Mysql数据库(一)数据库设计概述
1.数据库的体系结构 1.1 数据库系统的三级模式结构是指模式.外模式和内模式. 1.2 三级模式之间的映射分为外模式/模式映射和模式/内模式映射. 2.E-R图也称“实体-关系图”,用于描述现实世界 ...
- Spring MVC 设计概述
MVC设计的根本原因在于解耦各个模块 Spring MVC的架构 对于持久层而言,随着软件发展,迁移数据库的可能性很小,所以在大部分情况下都用不到Hibernate的HQL来满足移植数据库的要求. ...
- DDD领域驱动设计-概述-Ⅰ
如果我看得更远,那是因为我站在巨人的肩膀上.(If I have seen further it is by standing on ye shoulder of Giants.) ...
- 现代JVM内存管理方法的发展历程,GC的实现及相关设计概述(转)
JVM区域总体分两类,heap区和非heap区.heap区又分:Eden Space(伊甸园).Survivor Space(幸存者区).Tenured Gen(老年代-养老区). 非heap区又分: ...
随机推荐
- Python自动化测试发送邮件太麻烦?!一起聊一聊 Python 发送邮件的3种方式
1. 前言 发送邮件,我们在平时工作中经用到,做为测试人员,在自动化测试中用的也比较多,需要发送邮件给某领导 SMTP是Python默认的邮件模块,可以发送纯文本.富文本.HTML 等格式的邮件 今天 ...
- IdentityServer4[5]简化模式
Implicit简化模式(直接通过浏览器的链接跳转申请令牌) 简化模式是相对于授权码模式而言的.其不再需要[Client]的参与,所有的认证和授权都是通过浏览器来完成的. 创建项目 IdentityS ...
- HashMap扩容和ConcurrentHashMap
HashMap 存储结构 HashMap是数组+链表+红黑树(1.8)实现的. (1)Node[] table,即哈希桶数组.Node是内部类,实现了Map.Entry接口,本质是键值对. stati ...
- 如何通过云效Flow完成自动化构建—构建集群
如何通过云效Flow完成自动化构建-构建集群,云效流水线Flow是持续交付的载体,通过构建自动化.集成自动化.验证自动化.部署自动化,完成从开发到上线过程的持续交付.通过持续向团队提供及时反馈,让交付 ...
- 视频需求超平常数 10 倍,却节省了 60% 的 IT 成本投入是一种什么样的体验?
作者 | 山猎 近年来,Serverless 一直在高速发展,并呈现出越来越大的影响力.主流的云服务商也在不断地丰富云产品体系,提供更好的开发工具,更高效的应用交付流水线,更好的可观测性,更细腻的产品 ...
- Git学习笔记02-配置
安装好Git之后,做的就是需要配置Git了 第一步,配置自己的名称和邮箱 打开Git Bash 输入命令 git config --global user.name "用户名" g ...
- redis两种持久化策略/存储模式
redis的持久化策略 RDB,即 Redis DataBase,以快照形式将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的dump文件,达到数据恢复. 默认开启,见redis ...
- 内网渗透DC-2靶场通关(CTF)
为了更好的阅读体验,请在pc端打开我的个人博客 DC系列共9个靶场,本次来试玩一下DC-2,共有5个flag,下载地址. 下载下来后是 .ova 格式,建议使用vitualbox进行搭建,vmware ...
- 改善深层神经网络-week2编程题(Optimization Methods)
1. Optimization Methods Gradient descent goes "downhill" on a cost function \(J\). Think o ...
- dfs初步模板解析
#include<stdio.h> int a[10],book[10],n; //这里还有需要注意的地方C语言全局变量默认为0 void dfs(int step){ //此时在第ste ...