java内存模型——重排序
线程安全问题概括来说表现为三个方面:原子性,可见性和有序性。
在多核处理器的环境下:编译器可能改变两个操作的先后顺序;处理器可能不是完全依照程序的目标代码所指定的顺序执行命令;一个处理器执行的多个操作,在其他处理器的角度来看,其顺序可能与目标代码所指定的顺序不一致。这种现象就叫重排序。
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型。
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
内存重排序类型:
| 重排序类型 | 含义 |
|---|---|
| LoadLoad重排序 | 该重排序指一个处理器上先后执行两个读内存操作L1和L2,其他处理器对这两个内存操作的感知顺序可能是L2——>L1,即L1被重排序到L2之后。 |
| StoreStore重排序 | 该重排序指一个处理器上先后执行两个写内存操作W1和W2,其他处理器对这两个内存操作的感知顺序可能是W2——>W1,即W1被重排序到W2之后。 |
| LoadStore重排序 | 该重排序指一个处理器上先后执行读内存操作L1和写内存操作W2,其他处理器对这两个内存操作的感知顺序可能是W2——>L1,即L1被重排序到W2之后。 |
| StoreLoad重排序 | 该重排序指一个处理器上先后执行写内存操作W1和读内存操作L2,其他处理器对这两个内存操作的感知顺序可能是L2——>W1,即W1被重排序到L2之后。 |
内存重排序与具体的处理器微架构有关,基于不同微架构的处理器所允许的内存重排序是不同的,这里不再阐述。
重排序可能会导致多线程程序出现内存可见性问题
对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序
对于处理器重排序,JMM的处理器重排序规则会要求Java编译器在生成指令序列时,插入特定类型的内存屏障指令,通过内存屏障指令来禁止特定类型的处理器重排序。
常见的处理器都不允许对存在数据依赖的操作做重排序
数据依赖性: 如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分为下列3种类型:
1.写后读:a=1;b=a;
2.写后写:a=1;a=2;
3.读后写:a=b;b=1;
为了遵守as-if-serial语义,编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。因为这种重排序会改变执行结果。
不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是as-if-serial语义允许对存在控制依赖的操作做重排序的原因);但在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。
重排序对多线程的影响

当操作1和操作2重排序时
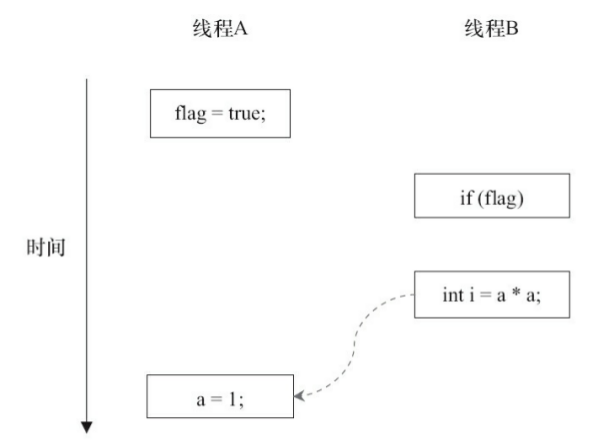
当操作3和操作4重排序时
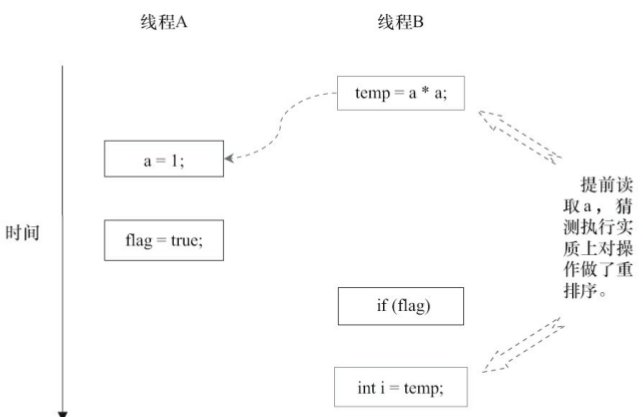
重排序在这里破坏了多线程程序的语义!
通过加锁同步可解决该问题
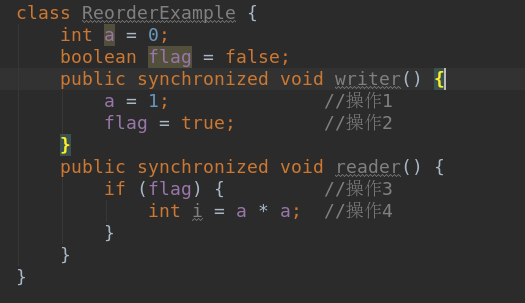
为了保证内存可见性,Java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序
- 无论是编译器还是处理器,都需要遵循以下重排序规则:
- 临界区内的操作不允许被重排序到临界区之外
- 临界区内的操作允许被重排序
- 临界区外的操作之间可以被重排序
- 锁申请与锁释放操作不能被重排序
- 两个锁申请操作不能被重排序
- 两个锁释放操作不能被重排序
- 临界区外的操作可以被重排序到临界区之内
参考资料:
1.Java并发编程的艺术(方腾飞 魏鹏 程晓明 著)
2.Java多线程编程实战指南(黄文海 著)
java内存模型——重排序的更多相关文章
- java内存模型-重排序
数据依赖性 如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性.数据依赖分下列三种类型: 名称 代码示例 说明 写后读 a = 1;b = a; 写一个变量之 ...
- Java内存访问重排序笔记
>>关于重排序 重排序通常是编译器或运行时环境为了优化程序性能而采取的对指令进行重新排序执行的一种手段. 重排序分为两类:编译期重排序和运行期重排序,分别对应编译时和运行时环境. > ...
- Java 并发系列之三:java 内存模型(JMM)
1. 并发编程的挑战 2. 并发编程需要解决的两大问题 3. 线程通信机制 4. 内存模型 5. volatile 6. synchronized 7. CAS 8. 锁的内存语义 9. DCL 双重 ...
- 【java多线程系列】java内存模型与指令重排序
在多线程编程中,需要处理两个最核心的问题,线程之间如何通信及线程之间如何同步,线程之间通信指的是线程之间通过何种机制交换信息,同步指的是如何控制不同线程之间操作发生的相对顺序.很多读者可能会说这还不简 ...
- Java内存模型(三)原子性、内存可见性、重排序、顺序一致性、volatile、锁、final
一.原子性 原子性操作指相应的操作是单一不可分割的操作.例如,对int变量count执行count++d操作就不是原子性操作.因为count++实际上可以分解为3个操作:(1)读取变量co ...
- java高并发核心要点|系列4|CPU内存指令重排序(Memory Reordering)
今天,我们来学习另一个重要的概念. CPU内存指令重排序(Memory Reordering) 什么叫重排序? 重排序的背景 我们知道现代CPU的主频越来越高,与cache的交互次数也越来越多.当CP ...
- JVM学习(3)——总结Java内存模型
俗话说,自己写的代码,6个月后也是别人的代码……复习!复习!复习!涉及到的知识点总结如下: 为什么学习Java的内存模式 缓存一致性问题 什么是内存模型 JMM(Java Memory Model)简 ...
- 浅析java内存模型--JMM(Java Memory Model)
在并发编程中,多个线程之间采取什么机制进行通信(信息交换),什么机制进行数据的同步? 在Java语言中,采用的是共享内存模型来实现多线程之间的信息交换和数据同步的. 线程之间通过共享程序公共的状态,通 ...
- 《深入理解Java内存模型》读书总结
概要 文章是<深入理解Java内容模型>读书笔记,该书总共包括了3部分的知识. 第1部分,基本概念 包括"并发.同步.主内存.本地内存.重排序.内存屏障.happens befo ...
随机推荐
- Centos7拓展磁盘(逻辑增加)
目录 第一步 第二步 第三步 以107.4G的Centos操作系统拓展20G磁盘空间,并将此20G磁盘空间分别分配给/home为例. 第一步 首先查看操作系统分区状况和磁盘占用情况.发现磁盘sda空间 ...
- 【NX二次开发】隐藏、显示对象UF_OBJ_set_blank_status
隐藏.显示对象用UF_OBJ_set_blank_status() 查看对象显示情况用UF_OBJ_ask_display_properties() 效果: 源码: #include "Te ...
- 认识5G
认识5G 一 移动通信发展历程 1移动通信技术具有代际演进规律 "G"代表一切 每10年一个周期 二 5G技术指标 流量密度:单位面积内的总流量数,是衡量移动网络在一定区域范围 ...
- 向虚拟机注册钩子,实现Bean对象的初始化和销毁方法
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言 有什么方式,能给代码留条活路? 有人说:人人都是产品经理,那你知道吗,人人也都可以是 ...
- Pytorch项目基本结构
梳理一下Pytorch项目的基本结构(其实TF的也差不多是这样,这种思路可以迁移到别的深度学习框架中) 结构树 -------checkpoints #存放训练完成的模型文件 ----xxx.pk ...
- Linux中Crontab的用法
1.crontab的概念: crontab命令用于设置周期性被执行的指令.该命令从标准输入设备读取指令,并将其存放于"crontab"文件中,以供之后读取和执行.可以使用它在每天的 ...
- python之循环与判断
1,for 循环,语法 举例: for i in range(1, 5, 2): # 0,1,2,3,4 print(i) for a in range(5):# --(0,5,1) 0,1,2,3, ...
- 第3章:快速部署一个Kubernetes集群
kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具. 这个工具能通过两条指令完成一个kubernetes集群的部署: # 创建一个 Master 节点$ kubeadm in ...
- FastDFS文件系统迁移和数据恢复
迁移步骤 打包旧服务器文件的所有文件 定位到旧服务器的tracker和Storage目录,将整个文件夹打包 tar -zcf fdfs-storage-data.tar.gz /fastdfs/sto ...
- AcWing 242. 一个简单的整数问题
给定长度为N的数列A,然后输入M行操作指令. 第一类指令形如"C l r d",表示把数列中第l~r个数都加d. 第二类指令形如"Q X",表示询问数列中第x个 ...