Regularizing Deep Networks with Semantic Data Augmentation
概
通过data augments来对数据进行扩充, 可以有效提高网络的泛化性.
但是这些transformers通常只有一些旋转, 剪切等较为简单的变换, 想要施加更为复杂的语义不变变换(如切换背景), 可能就需要GAN等引入额外的网络来进行.
本文提出的ISDA算法是基于特征的变化进行的, 技能进行语义层面的变换, 又没有GAN等方法的计算昂贵的缺点.
主要内容
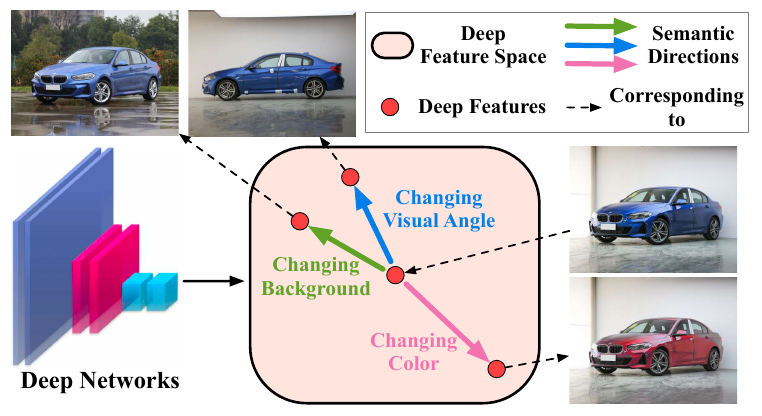
作者认为, 在最后的特征层, 通过增加一定的平移对应不同的语义上的变换.
但是, 作者也指明了, 并非所有的方向都是一个有意义的方向, 比如这个方向可能是戴上眼镜, 这个方向对于人来说是有意义的, 但是对于汽车飞机就没有意义了.
所以我们需要从一个有意义的分布中采样, 作者假设该分布是一个零均值的正态分布, 即
\]
于是乎, 现在的问题就是如何选择这个协方差矩阵\(\Sigma\).
就像之前讲的, 有些方向是否有意义与类别有关系, 所以不同的类别的样本会从不同的正态分布
\]
中采样.
对于每一个协方差矩阵, 作者采用online的更新方式更新:
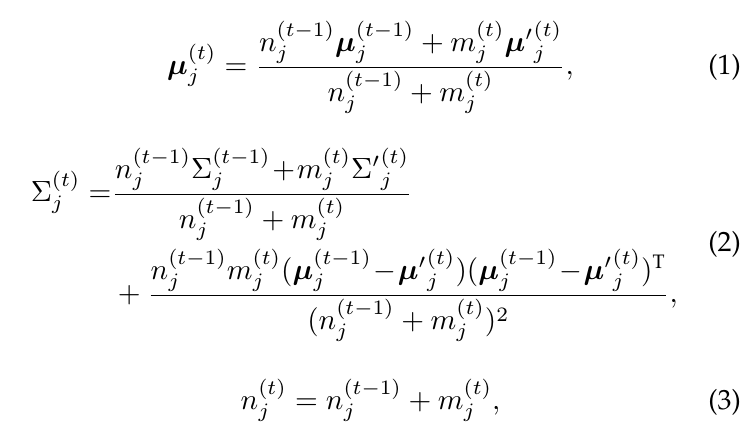
上图是式子就是普通的协方差估计式子
\]
的online更新版本.
如果假设样本\(x\)经过encoder之后的特征为\(a\), 则其变换后的版本
\]
其中\(y\)为\(x\)的类别标签. 于是一般的对应的损失函数即为
\]
当我们令\(M\)趋于无穷大的时候,
\]
这个式子没有显示解, 故作者退而求其次, 最小化其上界.
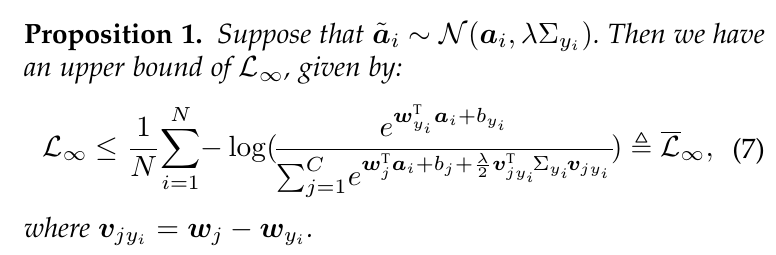
这个证明不难, 这里就练习一下
\]
既然
\]
代码
Regularizing Deep Networks with Semantic Data Augmentation的更多相关文章
- 【论文考古】联邦学习开山之作 Communication-Efficient Learning of Deep Networks from Decentralized Data
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, "Communication-Efficient Learni ...
- Communication-Efficient Learning of Deep Networks from Decentralized Data
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Proceedings of the 20th International Conference on Artificial Intell ...
- 论文解读(GraphDA)《Data Augmentation for Deep Graph Learning: A Survey》
论文信息 论文标题:Data Augmentation for Deep Graph Learning: A Survey论文作者:Kaize Ding, Zhe Xu, Hanghang Tong, ...
- paper 147:Deep Learning -- Face Data Augmentation(一)
1. 在深度学习中,当数据量不够大时候,常常采用下面4中方法: (1)人工增加训练集的大小. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.也就是Data ...
- Fully Convolutional Networks for Semantic Segmentation 译文
Fully Convolutional Networks for Semantic Segmentation 译文 Abstract Convolutional networks are powe ...
- Deep Learning 8_深度学习UFLDL教程:Stacked Autocoders and Implement deep networks for digit classification_Exercise(斯坦福大学深度学习教程)
前言 1.理论知识:UFLDL教程.Deep learning:十六(deep networks) 2.实验环境:win7, matlab2015b,16G内存,2T硬盘 3.实验内容:Exercis ...
- 论文笔记:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks ICML 2017 Paper:https://arxiv.org/ ...
- 【DeepLearning】Exercise: Implement deep networks for digit classification
Exercise: Implement deep networks for digit classification 习题链接:Exercise: Implement deep networks fo ...
- 深度学习材料:从感知机到深度网络A Deep Learning Tutorial: From Perceptrons to Deep Networks
In recent years, there’s been a resurgence in the field of Artificial Intelligence. It’s spread beyo ...
随机推荐
- 学习java 7.19
学习内容: 接口的组成中加入了默认方法,静态方法,私有方法 接口中默认方法:public default 返回值类型 方法名(参数列表){ } public default void show() ...
- flink-----实时项目---day05-------1. ProcessFunction 2. apply对窗口进行全量聚合 3使用aggregate方法实现增量聚合 4.使用ProcessFunction结合定时器实现排序
1. ProcessFunction ProcessFunction是一个低级的流处理操作,可以访问所有(非循环)流应用程序的基本构建块: event(流元素) state(容错,一致性,只能在Key ...
- echarts饼图样式
1.中间标题字体大小不一致(可分为一个title一个graphic) 2.labelLine与饼图分离(两个饼图,其中一个显示一个隐藏) function setmyChartJsgxzq(arr,d ...
- 如何启动、关闭和设置ubuntu防火墙 (转载)
引自:http://www.cnblogs.com/jiangyao/archive/2010/05/19/1738909.html 由于LInux原始的防火墙工具iptables过于繁琐,所以ubu ...
- Oracle中创建DB LINK
当用户要跨本地数据库,访问另外一个数据库表中的数据时,本地数据库中必须创建了远程数据库的dblink,通过dblink本地数据库可以像访问本地数据库一样访问远程数据库表中的数据.下面讲介绍如何在本地数 ...
- 为Python的web框架编写前端模版的教程
虽然我们跑通了一个最简单的MVC,但是页面效果肯定不会让人满意. 对于复杂的HTML前端页面来说,我们需要一套基础的CSS框架来完成页面布局和基本样式.另外,jQuery作为操作DOM的JavaScr ...
- springboot+vue集成mavon-editor,开发在线文档知识库
先睹为快,来看下效果: 技术选型 SpringBoot.Spring Security.Oauth2.Vue-element-admin 集成mavon-editor编辑器 安装 mavon-edit ...
- Project Reactor工厂方法和错误处理
工厂方法创建流 Backpressure : the ability for the consumer to signal the producer that the rate of emission ...
- 【Java基础】ExecutorService的使用
ExecutorService是java中的一个异步执行的框架,通过使用ExecutorService可以方便的创建多线程执行环境. 本文将会详细的讲解ExecutorService的具体使用. 创建 ...
- angular关于select的留白问题
Angular select留白的问题 小白的总结,大神勿喷:需要转载请说明出处,如果有什么问题,欢迎留言 总结:出现留白说明你的ng-model的值在option的value中没有对应的值: 一.直 ...