[决策树]西瓜数据graphviz可视化实现
[决策树]西瓜数据graphviz可视化实现
一、问题描述:
使用西瓜数据集构建决策树,并将构建的决策树进行可视化操作。
二、问题简析:
首先我们简单的介绍一下什么是决策树。决策树是广泛用于分类和回归任务的模型。本质上,它从一层层的if/else问题中进行学习,并得出结论。
三、代码实现:
说明:本实例运行在linux环境下,通过jupyter notebook运行。
依赖项:graphviz
下载GraphViz’s executables的网址:http://www.graphviz.org/
用pip安装的Graphviz,但是Graphviz不是一个python tool,仍然需要安装GraphViz’s executables。
sudo apt-get install graphviz
代码如下:
from random import choice
from collections import Counter
import math
# 定义数据集
D = [
{'色泽': '青绿', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑', '好瓜': '是'},
{'色泽': '乌黑', '根蒂': '蜷缩', '敲声': '沉闷', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑', '好瓜': '是'},
{'色泽': '乌黑', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑', '好瓜': '是'},
{'色泽': '青绿', '根蒂': '蜷缩', '敲声': '沉闷', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑', '好瓜': '是'},
{'色泽': '浅白', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑', '好瓜': '是'},
{'色泽': '青绿', '根蒂': '稍蜷', '敲声': '浊响', '纹理': '清晰', '脐部': '稍凹', '触感': '软粘', '好瓜': '是'},
{'色泽': '乌黑', '根蒂': '稍蜷', '敲声': '浊响', '纹理': '稍糊', '脐部': '稍凹', '触感': '软粘', '好瓜': '是'},
{'色泽': '乌黑', '根蒂': '稍蜷', '敲声': '浊响', '纹理': '清晰', '脐部': '稍凹', '触感': '硬滑', '好瓜': '是'},
{'色泽': '乌黑', '根蒂': '稍蜷', '敲声': '沉闷', '纹理': '稍糊', '脐部': '稍凹', '触感': '硬滑', '好瓜': '否'},
{'色泽': '青绿', '根蒂': '硬挺', '敲声': '清脆', '纹理': '清晰', '脐部': '平坦', '触感': '软粘', '好瓜': '否'},
{'色泽': '浅白', '根蒂': '硬挺', '敲声': '清脆', '纹理': '模糊', '脐部': '平坦', '触感': '硬滑', '好瓜': '否'},
{'色泽': '浅白', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '模糊', '脐部': '平坦', '触感': '软粘', '好瓜': '否'},
{'色泽': '青绿', '根蒂': '稍蜷', '敲声': '浊响', '纹理': '稍糊', '脐部': '凹陷', '触感': '硬滑', '好瓜': '否'},
{'色泽': '浅白', '根蒂': '稍蜷', '敲声': '沉闷', '纹理': '稍糊', '脐部': '凹陷', '触感': '硬滑', '好瓜': '否'},
{'色泽': '乌黑', '根蒂': '稍蜷', '敲声': '浊响', '纹理': '清晰', '脐部': '稍凹', '触感': '软粘', '好瓜': '否'},
{'色泽': '浅白', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '模糊', '脐部': '平坦', '触感': '硬滑', '好瓜': '否'},
{'色泽': '青绿', '根蒂': '蜷缩', '敲声': '沉闷', '纹理': '稍糊', '脐部': '稍凹', '触感': '硬滑', '好瓜': '否'},
]
# ==========
# 决策树生成类
# ==========
class DecisionTree:
def __init__(self, D, label, chooseA):
self.D = D # 数据集
self.label = label # 哪个属性作为标签
self.chooseA = chooseA # 划分方法
self.A = list(filter(lambda key: key != label, D[0].keys())) # 属性集合A
# 获得A的每个属性的可选项
self.A_item = {}
for a in self.A:
self.A_item.update({a: set(self.getClassValues(D, a))})
self.root = self.generate(self.D, self.A) # 生成树并保存根节点
# 获得D中所有className属性的值
def getClassValues(self, D, className):
return list(map(lambda sample: sample[className], D))
# D中样本是否在A的每个属性上相同
def isSameInA(self, D, A):
for a in A:
types = set(self.getClassValues(D, a))
if len(types) > 1:
return False
return True
# 构建决策树,递归生成节点
def generate(self, D, A):
node = {} # 生成节点
remainLabelValues = self.getClassValues(D, self.label) # D中的所有标签
remainLabelTypes = set(remainLabelValues) # D中含有哪几种标签
if len(remainLabelTypes) == 1:
# 当前节点包含的样本全属于同个类别,无需划分
return remainLabelTypes.pop() # 标记Node为叶子结点,值为仅存的标签
most = max(remainLabelTypes, key=remainLabelValues.count) # D占比最多的标签
if len(A) == 0 or self.isSameInA(D, A):
# 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分
return most # 标记Node为叶子结点,值为占比最多的标签
a = self.chooseA(D,A,self) # 划分选择
for type in self.A_item[a]:
condition = (lambda sample: sample[a] == type) # 决策条件
remainD = list(filter(condition, D)) # 剩下的样本
if len(remainD) == 0:
# 当前节点包含的样本集为空,不能划分
node.update({type: most}) # 标记Node为叶子结点,值为占比最多的标签
else:
# 继续对剩下的样本按其余属性划分
remainA = list(filter(lambda x: x != a, A)) # 未使用的属性
_node = self.generate(remainD, remainA) # 递归生成子代节点
node.update({type: _node}) # 把生成的子代节点更新到当前节点
return {a: node}
# 定义划分方法
# 随机选择
def random_choice(D, A, tree: DecisionTree):
return choice(A)
# 信息熵
def Ent(D,label,a,a_v):
D_v = filter(lambda sample:sample[a]==a_v,D)
D_v = map(lambda sample:sample[label],D_v)
D_v = list(D_v)
D_v_length = len(D_v)
counter = Counter(D_v)
info_entropy = 0
for k, v in counter.items():
p_k = v / D_v_length
info_entropy += p_k * math.log(p_k, 2)
return -info_entropy
# 信息增益
def information_gain(D, A, tree: DecisionTree):
gain = {}
for a in A:
gain[a] = 0
values = tree.getClassValues(D, a)
counter = Counter(values)
for a_v,nums in counter.items():
gain[a] -= (nums / len(D)) * Ent(D,tree.label,a,a_v)
return max(gain.keys(),key=lambda key:gain[key])
# 创建决策树
desicionTreeRoot = DecisionTree(D, label='好瓜',chooseA=information_gain).root
print('决策树:', desicionTreeRoot)
# 决策树可视化类
class TreeViewer:
def __init__(self):
from graphviz import Digraph
self.id_iter = map(str, range(0xffff))
self.g = Digraph('G', filename='decisionTree.gv')
def create_node(self, label, shape=None):
id = next(self.id_iter)
self.g.node(name=id, label=label, shape=shape, fontname="Microsoft YaHei")
return id
def build(self, key, node, from_id):
for k in node.keys():
v = node[k]
if type(v) is dict:
first_attr = list(v.keys())[0]
id = self.create_node(first_attr+"?", shape='box')
self.g.edge(from_id, id, k, fontsize = '12', fontname="Microsoft YaHei")
self.build(first_attr, v[first_attr], id)
else:
id = self.create_node(v)
self.g.edge(from_id, id, k, fontsize = '12', fontname="Microsoft YaHei")
def show(self, root):
first_attr = list(root.keys())[0]
id = self.create_node(first_attr+"?", shape='box')
self.build(first_attr, root[first_attr], id)
self.g.view()
# 显示创建的决策树
viewer = TreeViewer()
viewer.show(desicionTreeRoot)
输出结果:
决策树: {'纹理': {'清晰': {'根蒂': {'蜷缩': '是', '硬挺': '否', '稍蜷': {'色泽': {'青绿': '是', '浅白': '是', '乌黑': {'触感': {'硬滑': '是', '软粘': '否'}}}}}}, '稍糊': {'触感': {'硬滑': '否', '软粘': '是'}}, '模糊': '否'}}
在jupyter notebook的运行效果如图:
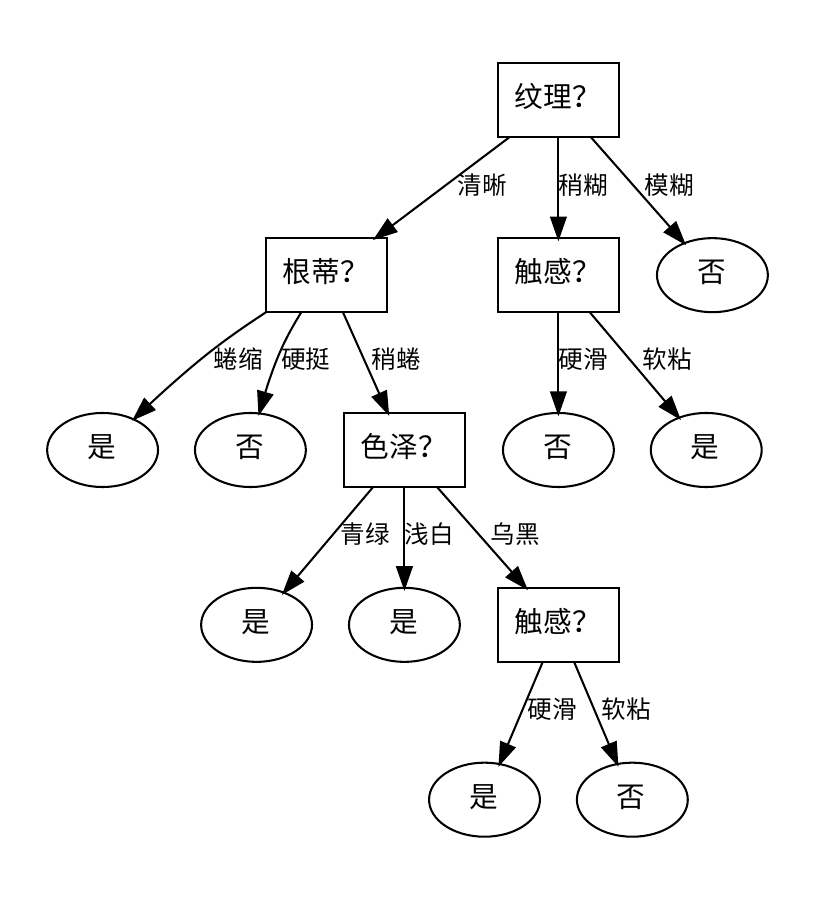
参考:
Python机器学习之决策树(使用西瓜数据集构建决策树,并将其可视化,graphviz程序下载)
[决策树]西瓜数据graphviz可视化实现的更多相关文章
- 图数据 3D 可视化在 Explorer 中的应用
本文首发于 NebulaGraph 公众号 前言图数据可视化是现代 Web 可视化技术中比较常见的一种展示方式,NebulaGraph Explorer 作为基于 NebulaGraph 的可视化产品 ...
- 11,SFDC 管理员篇 - 报表和数据的可视化
1,Report Builder 1,每一个report type 都有一个 primay object 和多个相关的object 2,Primary object with related obje ...
- MetricGraphics.js – 时间序列数据的可视化
MetricsGraphics.js 是建立在D3的基础上,被用于可视化和布局的时间序列数据进行了优化.它提供以产生一个原则性的,一致的和响应式的方式的图形常见类型的简单方法.该库目前支持折线图,散点 ...
- 利用 t-SNE 高维数据的可视化
利用 t-SNE 高维数据的可视化 具体软件和教程见: http://lvdmaaten.github.io/tsne/ 简要介绍下用法: % Load data load ’mnist_trai ...
- 基于 HTML5 的 WebGL 和 VR 技术的 3D 机房数据中心可视化
前言 在 3D 机房数据中心可视化应用中,随着视频监控联网系统的不断普及和发展, 网络摄像机更多的应用于监控系统中,尤其是高清时代的来临,更加快了网络摄像机的发展和应用. 在监控摄像机数量的不断庞大的 ...
- OneAPM大讲堂 | 监控数据的可视化分析神器 Grafana 的告警实践
文章系国内领先的 ITOM 管理平台供应商 OneAPM 编译呈现. 概览 Grafana 是一个开源的监控数据分析和可视化套件.最常用于对基础设施和应用数据分析的时间序列数据进行可视化分析,也可以用 ...
- LDA模型数据的可视化
""" 执行lda2vec.ipnb中的代码 模型LDA 功能:训练好后模型数据的可视化 """ from lda2vec import p ...
- circso 对数据进行可视化
circos可以用来绘制圈图,能够对染色体上的数据进行可视化,首先需要一个染色体的文件 染色体的文件如下,每列之间空格分隔 chr - chr1 chr1 chr - chr2 chr2 chr - ...
- 初识Dash -- 构建一个人人都能够轻松上手的界面,操控数据和可视化
从事数据科学工作,少不了使用Pandas.scikit-learn这些Python生态系统中的利器,还有就是控制工作流的Jupyter Notebooks,没的说,你和同事都爱用.但是,要想将工作成果 ...
随机推荐
- 基于MQTT协议实现远程控制的"智能"车
智能,但不完全智能 虽然我不觉得这玩意儿有啥智能的,但都这么叫就跟着叫喽. 时隔好几天才写的 其实在写这篇博文的时候我已经在做升级了,并且已经到了中后期阶段了. 主要是业余时间做着玩,看时间了. 规格 ...
- 【讨论】APP的免填邀请码解决方案
00x0 具体需求 app中已注册的用户分享一个含有邀请码的二维码,分享到朋友圈新用户在朋友圈打开这个这个链接下载app.新用户安装后打开app后就自动绑定邀请码要求用户不填写任何东西 朋友老板出差给 ...
- map和forEach的区别
总结 forEach()可以做到的东西,map()也同样可以.反过来也是如此. map()会分配内存空间存储新数组并返回,forEach()不会返回数据. forEach()允许callback更改原 ...
- Linux学习 - 文件特殊权限
一.SUID权限(只针对文件) 只有可执行的二进制程序才能设定SUID权限 命令执行者要对该程序拥有x(执行)权限 1 拥有SUID的文件 /usr/bin/passwd 2 功能: 命令执行者(其他 ...
- hadoop Sort排序
1 public int getPartition(IntWritable key,IntWritable value,int numPartitions){ 2 int Maxnumber = 12 ...
- web端 - 返回上一步,点击返回,跳转上个页面 JS
1.方法一: <script language="javascript" type="text/javascript"> window.locati ...
- Mybatis-plus报Invalid bound statement (not found)错误
错误信息 org.springframework.security.authentication.InternalAuthenticationServiceException: Invalid bou ...
- Mysql脚本 优化检测
下载地址: wget https://launchpad.net/mysql-tuning-primer/trunk/1.6-r1/+download/tuning-primer.sh 安装依赖: y ...
- 从Rest到Graphql
一.引言 ok,如图所示,我在去年曾经写过一篇文章<闲侃前后端分离的必要性>.嗯,我知道肯定很多人没看过.所以我做一个总结,其实啰里八嗦了一篇文章,就是想说一下现在的大型互联网项目一般是如 ...
- Log4j2再发新版本2.16.0,完全删除Message Lookups的支持,加固漏洞防御
昨天,Apache Log4j 团队再次发布了新版本:2.16.0! 2.16.0 更新内容 默认禁用JNDI的访问,用户需要通过配置log4j2.enableJndi参数开启 默认允许协议限制为:j ...