解析导航栏的url--selnium,beautifulsoup实战
前段时间做ui自动化测试的时候,导航栏菜单始终有点问题,最后只好直接获取到url,然后直接使用driver.get(url)进入页面;
包括做压测的时候,比如我要找出所有报表菜单的url,这样不可能手动去一个一个找出来,然后复制,这样浪费时间,并且也容易漏掉,所以我就写了个脚本来干这事;
首先说下思路:登录-->获取所有的a标签-->筛选掉不用的标签-->打印或者保存到文件中
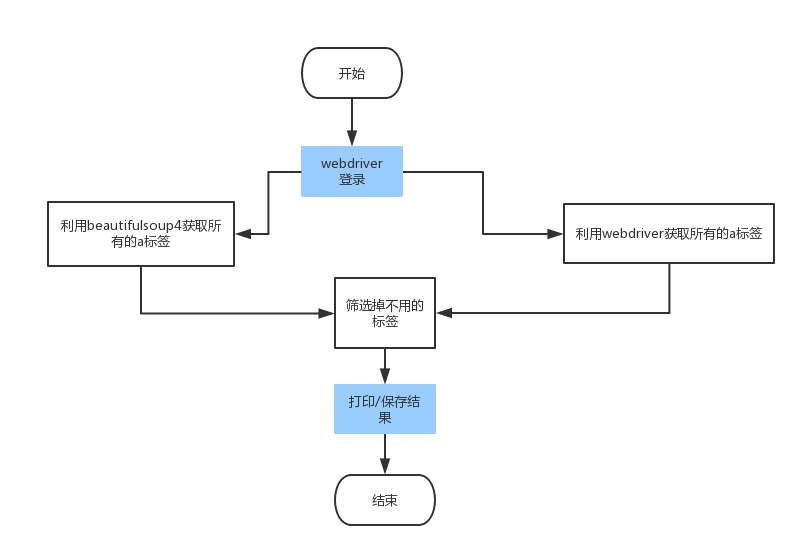
其中我获取页面所有的标签使用了两种方法,webdriver和beautifulsoup4,两种的区别:1、beautifulsoup4来解析的时候,比较稳定,并且速度快,2、webdriver可能简单一点吧,我推荐是用beautifulsoup4;之所以是用webdriver登录,是因为用webdriver登录简单,不像requests来请求的话,第一次还要分析url,参数之类的,用webdriver的话,只需要定位几个元素就ok了,何乐而不为呢。。。
下面我将两种方式的运行时间、最终的解析结果:

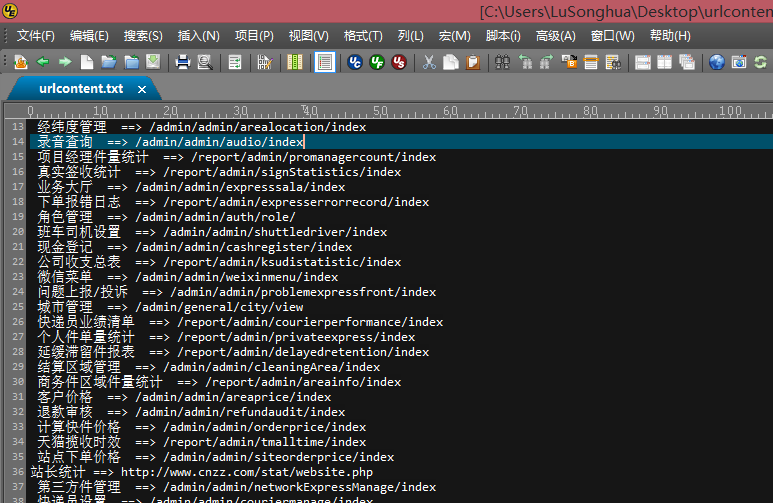
下面的是第一种方式:使用beautifulsoup4来解析:
#coding=utf-8 """
是为了获取XXX系统菜单的url
使用的是selenium登录,获取网页的内容,然后用beautifulsoup来解析
"""
import unittest
import time
from selenium import webdriver
from bs4 import BeautifulSoup # 登录url
url = 'http://XXXX.XXXX.com/' # 系统的url
username = 'XXXX'
password = 'XXXXX' class GetUrl(unittest.TestCase):
def setUp(self):
self.dr = webdriver.Chrome()
self.dr.get(url) def tearDown(self):
self.dr.quit() def _login(self):
self.dr.find_element_by_id('username').send_keys(username) # 输入用户名
self.dr.find_element_by_id('password').send_keys(password) # 输入密码
# self.dr.find_element_by_id('verifycode').send_keys('XXXXX') 这里原来是需要验证码的,后来取消掉了
self.dr.find_element_by_id('weblogin').click() # 点击登录按钮
time.sleep(3) def _gethtmlcontent(self):
"""获取当前页面的html的所有内容"""
content = self.dr.page_source # 将该页面的内容 返回给content保存起来方便后面解析
return content def _geturl(self,pagesource):
"""
找出所有的a标签,然后筛选掉非导航连接的a标签。返回的是一个dict
"""
result = dict()
soup = BeautifulSoup(pagesource, "lxml")
eles = soup.find_all("a")
flag = 0
for ele in eles:
if '#' in ele['href']:
continue
tmp = ele.string
if tmp is not None and '@' not in tmp:
flag += 1
ele_url = ele['href'].split('?')[0]
# print('{0} ==> {1}'.format(tmp,ele_url))
result[tmp] = ele_url # print('Find out {0} datas.'.format(len(result)))
return result def _writetotxt(self,contents):
"""
将结果写入文件中
"""
print('写入开始')
with open('urlcontent.txt','w') as f:
for title,value in contents.items():
f.write('{0} ==> {1}\n'.format(title,value))
print('写入完毕') def test_run(self):
self._login()
pagesources = self._gethtmlcontent()
result = self._geturl(pagesources)
self._writetotxt(result) if __name__ == '__main__':
unittest.main()
第二种全都是使用webdriver来解析的:
#coding=utf-8 """
是为了获取XXX系统菜单的url
使用的是selenium登录,查找元素,获取元素的属性
"""
from selenium import webdriver
import unittest
import time # 登录url
url = 'http://XXX.XXX.com/'
username = 'XXX'
password = 'XXX' class GetUrl(unittest.TestCase):
def setUp(self):
self.dr = webdriver.Chrome()
self.dr.get(url) def tearDown(self):
self.dr.quit() def _login(self):
# time.sleep(2)
self.dr.find_element_by_id('username').send_keys(username)
self.dr.find_element_by_id('password').send_keys(password)
# self.dr.find_element_by_id('verifycode').send_keys('XXXXX')
self.dr.find_element_by_id('weblogin').click()
time.sleep(3) def _geturl(self):
# 这里返回的是一个list,然后里面是一个个字典
result = list()
eles = self.dr.find_elements_by_css_selector('menu.u-menu a')
for ele in eles:
tmp = dict()
href = ele.get_attribute('href').split('?')[0]
# 获取菜单 的名称
name = ele.get_attribute('innerHTML')
if "<i>" not in name:
tmp['name'] = name.strip()
tmp['href'] = href
result.append(tmp)
# print('name: {0},href: {1}'.format(name,href))
return result def _writetotxt(self,contents):
print("一共{0}条数据".format(len(contents)))
print('写入开始')
with open('urlcontent.txt','w') as f:
for content in contents:
f.write('{0} ==> {1}\n'.format(content['name'],content['href']))
print('写入完毕') def test_run(self):
self._login()
self._writetotxt(self._geturl()) if __name__ == '__main__':
unittest.main()
好了,就到这里吧。。。
解析导航栏的url--selnium,beautifulsoup实战的更多相关文章
- 解析导航栏的url
前段时间做ui自动化测试的时候,导航栏菜单始终有点问题,最后只好直接获取到url,然后直接使用driver.get(url)进入页面: 包括做压测的时候,比如我要找出所有报表菜单的url,这样不可能手 ...
- day77:luffy:导航栏的实现&DjangoRestFramework JWT&多条件登录
目录 1.导航栏的实现 2.登录前戏:用户表初始化 3.DjangoRestFramework JWT 4.多条件登录 5.登录状态的判断和退出登录 1.导航栏的实现 1.设计导航栏的model模型类 ...
- Android ActionBar完全解析,使用官方推荐的最佳导航栏(下) .
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/25466665 本篇文章主要内容来自于Android Doc,我翻译之后又做了些加工 ...
- Html5 学习笔记 【PC固定布局】 实战2 导航栏搜索区域
<!DOCTYPE html> <html lang="zh-cn"> <head> <meta charset="UTF-8& ...
- Html5 学习笔记 【PC固定布局】 实战1 导航栏
导航栏html文件: <!DOCTYPE html> <html lang="zh-cn"> <head> <meta charset=& ...
- Android ActionBar完全解析,使用官方推荐的最佳导航栏(上)
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/18234477 本篇文章主要内容来自于Android Doc,我翻译之后又做了些加工 ...
- Android ActionBar全然解析,使用官方推荐的最佳导航栏(上)
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/18234477 本篇文章主要内容来自于Android Doc.我翻译之后又做了些加工 ...
- 【转】Android ActionBar完全解析,使用官方推荐的最佳导航栏(上)
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/18234477 本篇文章主要内容来自于Android Doc,我翻译之后又做了些加工 ...
- Bootstrap 学习笔记 项目实战 响应式导航栏
导航代码HTML: <!DOCTYPE html> <html lang="zh-cn"> <head> <meta charset=&q ...
随机推荐
- 分享我的“艺术品”:公共建筑能耗监测平台的GPRS通讯服务器的开发方法分享
在这个文章里面我将用一个实际的案例来分享如何来构建一个能够接受3000+个连接的GPRS通讯服务器软件,这个软件被我认为是一个艺术品,实现周期为1.5个月,文章很长,有兴趣的同志慢慢看.在这里,我将分 ...
- Grpc微服务从零入门
快速入门 安装 JDK 毫无疑问,要想玩Java,就必须得先装Java JDK,目前公司主要使用的是Oracle JDK 8,安装完成后要配置环境才能正常使用,真蠢,不过也就那么一下下,认了吧.配置方 ...
- 解决.NET Core中MailKit无法使用阿里云邮件推送服务的问题
在博问中(.net core怎么实现邮件发送)知道了MailKit无法使用阿里云邮件推送服务发送邮件的问题,自已实测也遇到同样的问题,而用自己搭建的邮件服务器没这个问题. 于是,向阿里云提交了工单.. ...
- WebDAV 配置及相关工具
最近在项目中安装和调试服务器,杯具的是,服务器是内网地址,而且不可以直接SSH.SFTP,只能通过中间一台linux作为跳板,然后在SSH命令行里去操作目标机器. 如果只是命令行操作也就无所谓了,但是 ...
- 【译】用jQuery 处理XML-- DOM(文本对象模型)简介
用jQuery 处理XML--写在前面的话 用jQuery 处理XML-- DOM(文本对象模型)简介 用jQuery 处理XML--浏览器中的XML与JavaScript 用jQuery 处理XML ...
- AngularJS快速入门指南19:示例代码
本文给出的大部分示例都可以直接运行,通过点击运行按钮来查看结果,同时支持在线编辑代码. <div ng-app=""> <p>Name: <input ...
- MySQL服务器安装配置-非安装版、windows版
文档以5.6.30版本为例子说明 1. 下载MySQL http://dev.mysql.com/downloads/mysql/5.6.html#downloads 我们可以选择自己所需要的版本.环 ...
- ssh/openssh
http://www.cnblogs.com/wwufengg/articles/ssh-openssh-detail.html http://www.cnblogs.com/jjkv3/archiv ...
- sublime text使用及常见问题
sublime text是一款非常不错的代码编辑器,体积小.界面漂亮.支持众多语言.插件丰富,且支持Windows.Mac.Linux几大平台. 官网:http://www.sublimetext.c ...
- 理解nginx的配置
Nginx配置文件主要分成四部分:main(全局设置).server(主机设置).upstream(上游服务器设置,主要为反向代理.负载均衡相关配置)和 location(URL匹配特定位置后的设置) ...