在SQL Server里为什么我们需要更新锁
今天我想讲解一个特别的问题,在我每次讲解SQL Server里的锁和阻塞(Locking & Blocking)都会碰到的问题:在SQL Server里,为什么我们需要更新锁?在我们讲解具体需要的原因前,首先我想给你介绍下当更新锁(Update(U)Lock)获得时,根据它的兼容性锁本身是如何应对的。
一般来说,当执行UPDATE语句时,SQL Server会用到更新锁(Update Lock)。如果你查看对应的执行计划,你会看到它包含3个部分
- 读取数据
- 计算新值
- 写入数据
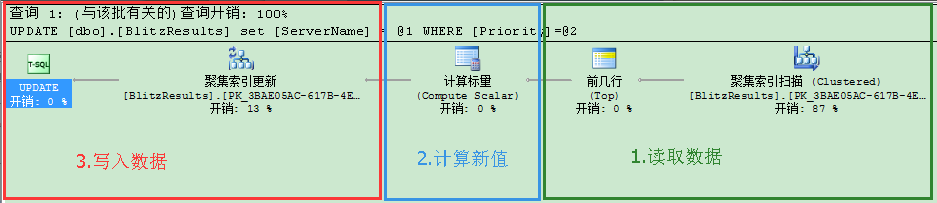
在查询计划的第1部分,SQL Server初始读取要修改的数据,在各个记录上会获得更新锁(Update Locks)。在查询计划的最后第3部分,当数据被修改时,这些更新锁(Update Locks)转化为排它锁(Exclusive(X))。用这个方法产生的问题都是一样的:在第1个阶段,SQL Server为什么要获得更新锁(Update Locks),而不是共享锁(Shared(S) Locks)。平常当你通过SELECT语句读取数据,共享锁(Shared(S) Locks)已经够用了。现在的更新查询计划为什么有这个区别?我们来详细分析下。
回避死锁(Deadlock Avoidance)
首先在更新查询计划里,更新锁用来避免死锁情形。假设在计划的第1阶段,有多个更新查询计划获得共享锁(Shared(S)Locks),然后在查询计划的第3阶段,当数据最后被修改时,这些共享锁(Shared Locks)转化为排它锁(Exclusive Loks),会发生什么:
- 第1个查询不能转化共享锁为排它锁,因为第2个查询已经获得了共享锁。
- 第2个查询不能转化共享锁为排它锁,因为第1个查询已经获得了共享锁。
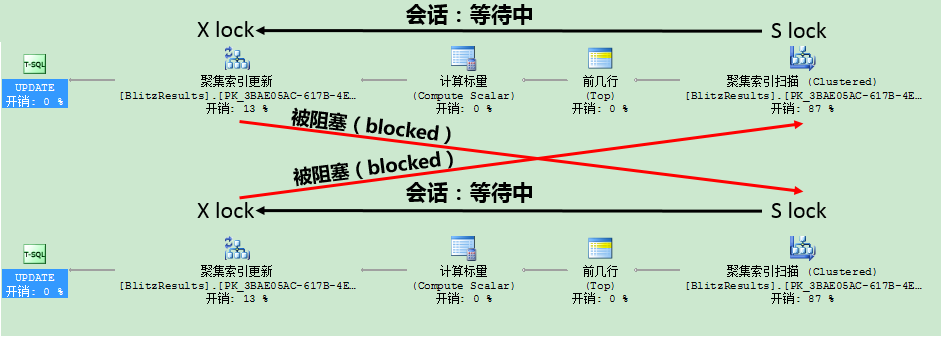
这是其中一个主要原因,为什么关系数据库引擎引入更新锁来实现避免特定的死锁情形。一个更新锁只与一个共享锁兼容,但不与另一个更新或排它锁兼容。因此死锁情形可以被避免,应为2个更新查询计划不可能同时并发运行。在查询的第1阶段,第2个查询会一直等到获得更新锁。System R的一个未公开研究也展示如何避免这类显著的死锁。System R不使用任何更新锁来实现避免死锁。
提升的并发
在第1阶段不获得更新锁,在这个阶段直接获得排它锁也是可见选项。这会克服死锁问题,因为排它锁与另一个排它锁不兼容。但这个方法的问题是并发受限制,因为同时没有其他的SELECT查询可以读取当前有排它锁的数据。因此需要更新锁,因为这个特定锁与传统的共享锁兼容。这样的话其他的SELECT查询可以读取数据,只要这个更新锁还没转化为排它锁。作为副作用,这会提高我们并发运行查询的并发性。
在以前关系学术上,更新锁是所谓的非对称锁(Asymmetric Lock)。在更新锁的上下文里,这个更新锁与共享锁兼容,但反之就不是:共享锁与更新锁不兼容。但SQL Server并不把共享锁作为非对称锁实现。更新锁是个对称(symmetric)的,就是说更新锁和共享锁是彼此双向兼容的。这会提供系统的整体并发,因为在2个锁类型键不会引入阻塞情形。
小结
在今天的文章里我给你介绍了共享锁,还有为什么需要共享锁。如你所见在关系数据库,是强烈需要更新锁的,因为不然的就会带来死锁并降低并发。我希望现在你已经很好的理解了更新锁,还有在SQL Server里它们是如何使用的。
感谢关注!
参考文章:
https://www.sqlpassion.at/archive/2014/07/28/why-do-we-need-update-locks-in-sql-server/
在SQL Server里为什么我们需要更新锁的更多相关文章
- 在SQL Server里我们为什么需要意向锁(Intent Locks)?
在1年前,我写了篇在SQL Server里为什么我们需要更新锁.今天我想继续这个讨论,谈下SQL Server里的意向锁,还有为什么需要它们. SQL Server里的锁层级 当我讨论SQL Serv ...
- SQL Server里的闩锁介绍
在今天的文章里我想谈下SQL Server使用的更高级的,轻量级的同步对象:闩锁(Latch).闩锁是SQL Server存储引擎使用轻量级同步对象,用来保护多线程访问内存内结构.文章的第1部分我会介 ...
- SQL Server里因丢失索引造成的死锁
在今天的文章里我想演示下SQL Server里在表上丢失索引如何引起死锁(deadlock)的.为了准备测试场景,下列代码会创建2个表,然后2个表都插入4条记录. -- Create a table ...
- SQL Server里在文件组间如何移动数据?
平常我不知道被问了几次这样的问题:“SQL Server里在文件组间如何移动数据?“你意识到这个问题:你只有一个主文件组的默认配置,后来围观了“SQL Server里的文件和文件组”后,你知道,有多 ...
- SQL Server里的文件和文件组
在今天的文章里,我想谈下SQL Server里非常重要的话题:SQL Server如何处理文件的文件组.当你用CREATE DATABASE命令创建一个简单的数据库时,SQL Server为你创建2个 ...
- SQL Server里的闩锁耦合(Latch Coupling)
几年前,我写了篇关于闩锁和为什么SQL Server需要它们的文章.在今天的文章里,我想进一步谈下非缓存区闩锁(Non-Buffer Latches),还有在索引查找操作期间,SQL Server如何 ...
- 在SQL Server里如何进行页级别的恢复
在今天的文章里我想谈下每个DBA应该知道的一个重要话题:在SQL Server里如何进行页级别还原操作.假设在SQL Server里你有一个损坏的页,你要从最近的数据库备份只还原有问题的页,而不是还原 ...
- SQL Server里强制参数化的痛苦
几天前,我写了篇SQL Server里简单参数化的痛苦.今天我想继续这个话题,谈下SQL Server里强制参数化(Forced Parameterization). 强制参数化(Forced Par ...
- SQL Server里ORDER BY的歧义性
在今天的文章里,我想谈下SQL Server里非常有争议和复杂的话题:ORDER BY子句的歧义性. 视图与ORDER BY 我们用一个非常简单的SELECT语句开始. -- A very simpl ...
随机推荐
- PAT/进制转换习题集
B1022. D进制的A+B (20) Description: 输入两个非负10进制整数A和B(<=230-1),输出A+B的D (1 < D <= 10)进制数. Input: ...
- TJ/T808 终端通讯协议设计与实现(码农本色)
由于公司项目涉及到相关技术,对于平常写WEB的技术人员来说对这人来说比较默生:为了让下面的技术人员更好地对这个协议的实施,所以单独针对这个协议进行了分析和设计,以更于后期更好指导相关开发工作.由于自己 ...
- 测试了几款 C# 脚本引擎 , Jint , Jurassic , Nlua, ClearScript
测试类 public class Script_Common { public string read(string filename) { return System.IO.File.ReadAll ...
- 【T-SQL基础】02.联接查询
概述: 本系列[T-SQL基础]主要是针对T-SQL基础的总结. [T-SQL基础]01.单表查询-几道sql查询题 [T-SQL基础]02.联接查询 [T-SQL基础]03.子查询 [T-SQL基础 ...
- HTML5+flash打造兼容各浏览器的文件上传方案
上一篇文章介绍了HTML5版的文件上传插件,相比flash,采用HTML5的新技术无疑可以提升程序的加载速度.但是在目前的情况看来,HTML5的特性支持度不高,插件的可用性范围确实比较窄.例如,我在插 ...
- HOOK技术的一些简单总结
好久没写博客了, 一个月一篇还是要尽量保证,今天谈下Hook技术. 在Window平台上开发任何稍微底层一点的东西,基本上都是Hook满天飞, 普通应用程序如此,安全软件更是如此, 这里简单记录一些常 ...
- svn 忽略文件不管用
svn 不能对已添加过版本控制的文件进行忽略.于是乎,你会发先,你怎么忽略都不起作用.于是乎,该怎么办? svn忽略已添加到版本库文件或文件夹步骤: 将要忽略的文件或文件夹剪切到非工作拷贝目录. 在父 ...
- Atitit.现在的常用gui技术与gui技术趋势评价总结
Atitit.现在的常用gui技术与gui技术趋势评价总结 1. Gui俩种分类: native 和 dsl 和 script1 2. 最好的跨平台gui技术h51 2.1. 几大技术体系(java ...
- Paip.语义分析----情绪情感词汇表总结
Paip.语义分析----情绪情感词汇表总结 以下词语是按感情色彩共分为十四类: 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:h ...
- fir.im Weekly - 聊聊让人向往的远程开发工作
6月30 日,苹果开发者后台贴出一封关于广电总局的醒目通知,申报一个游戏 APP 上架AppStore,你需要文网文+ICP证+软著+版号,审批难度将越来越大,不禁让人感慨中国独立开发者的成长 &qu ...