点我吧工作总结(技术篇) Cobar原理和环境搭建
我思故我在,提问启迪思考!
1.什么是Cobar?
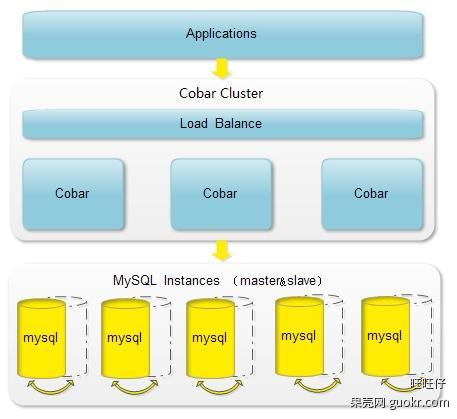
Cobar是关系型数据的分布式处理系统,它可以在分布式的环境下看上去像传统数据库一样为您提供海量数据服务。cobar已经在阿里巴巴B2B公司稳定运行了3年以上。目前已经接管了3000+个MySQL数据库的schema,为应用提供数据服务。据最近统计cobar集群目前平均每天处理近50亿次的SQL执行请求。
Cobar是阿里巴巴(B2B)部门开发的一种关系型数据的分布式处理系统,它可以在分布式的环境下看上去像传统数据库一样为您提供海量数据服务。master是主库,slave是从库,配合cobar的使用过,需要在建表的时候加入分库字段,由cobar分库路由分配到不同的数据库上做查询。
2.什么是数据库的schema?
在mysql中创建一个schema跟创建一个database是一样的效果,schema为数据库对象的集合,为了区分各个集合,我们需要给这个集合起个名字,这些名字就是我们在企业管理器的方案下看到的许多类似用户名的节点,这些类似用户名的节点其实就是一个schema。(个人理解,schema可以理解为数据库database的一个快捷方式)。
3.cobar解决了哪些问题?{最好是能用缓存挡掉数据库访问的压力}
随着业务的进行数据库的数据量和访问量的剧增,需要对数据进行水平拆分来降低单库的压力,而且需要高效且相对透明的来屏蔽掉水平拆分的细节?
为提高访问的可用性,数据源需要备份,数据源可用性的检测和failover?前台的高并发造成后台数据库连接数过多,降低了性能,怎么解决?针对以上问题就有了cobar施展自己的空间了,cobar中间件以proxy的形式位于前台应用和实际数据库之间,对前台的开放的接口是mysql通信协议。将前台SQL语句变更并按照数据分布规则转发到合适的后台数据分库,再合并返回结果,模拟单库下的数据库行为。
cabar优点总结:1.数据和访问从集中式改变为分布,Cobar支持将一张表水平拆分成多份分别放入不同的库来实现表的水平拆分,Cobar也支持将不同的表放入不同的库,多数情况下,用户会将以上两种方式混合使用。(注意!:Cobar不支持将一张表,例如test表拆分成test_1,test_2, test_3.....放在同一个库中,必须将拆分后的表分别放入不同的库来实现分布式。)2.解决连接数过大的问题。3.对业务代码侵入性少。4.提供数据节点的failover,
HA(High Available高可用性):Cobar的主备切换有两种触发方式,一种是用户手动触发,一种是Cobar的心跳语句检测到异常后自动触发。那么,当心跳检测到主机异常,切换到备机,如果主机恢复了,需要用户手动切回主机工作,Cobar不会在主机恢复时自动切换回主机,除非备机的心跳也返回异常。Cobar只检查MySQL主备异常,不关心主备之间的数据同步,因此用户需要在使用Cobar之前在MySQL主备上配置双向同步。(当出错的时候,频繁的在主从之间切换,会导致业务逻辑层的sql查询不可用现象发生)。
4.cobar应用举例。

应用介绍:
1.通过Cobar提供一个名为test的数据库,其中包含t1,t2两张表。后台有3个MySQL实例(ip:port)为其提供服务,分别为:A,B,C。
2.期望t1表的数据放置在实例A中,t2表的数据水平拆成四份并在实例B和C中各自放两份。t2表的数据要具备HA(High Available高可用性)功能,即B或者C实例其中一个出现故障,不影响使用且可提供完整的数据服务。
5.其他类似功能的MySQL中间件了解?
Atlas,cobar,TDDL(http://www.guokr.com/blog/475765/?_t=t)
6.Cobar的环境搭建
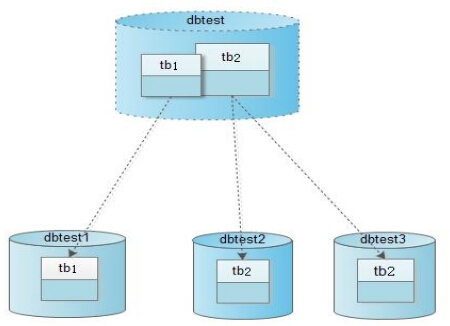
如上图所示, 我们在schema中定义了两个表,第一个表命名为tb1,另外一个表命名为tb2。但是在实际的物理数据库服务器上,却是将表tb1存放在数据库dbtest1上,将表tb2分别存放在dbtest2数据库和dbtest3数据库。tb1作为对比,来感受一下用Cobar实现的分库功能。
首先,我们创建dbtest1、dbtest2、dbtest3三个数据库和tb1,tb2,tb2三个表。因为这些都是实际在物理数据库服务器上存在的,而dbtest是虚幻的,不实际存在的快捷方式吧。
#创建dbtest1 ;在dbtest1上创建tb1
drop database if exists dbtest1;
create database dbtest1;
use dbtest1;
create table tb1(
id int not null,
gmt datetime); #创建dbtest2;在dbtest2上创建tb2
drop database if exists dbtest2;
create database dbtest2;
use dbtest2;
create table tb2(
id int not null,
val varchar(256)); #创建dbtest3;在dbtest3上创建tb2
drop database if exists dbtest3;
create database dbtest3;
use dbtest3;
create table tb2(
id int not null,
val varchar(256));
创建好上述数据库和表之后,注意一般是要放在三台服务器上,为了分担读写压力。我们来配置装有Cobar的服务器上的几个Cobar配置文件,schema.xml、rule.xml和server.xml,它们的配置分别如下:
<?xml version="1.0" encoding="UTF-"?>
<!DOCTYPE cobar:schema SYSTEM "schema.dtd">
<cobar:schema xmlns:cobar="http://cobar.alibaba.com/">
<!-- schema定义 -->
<schema name="dbtest" dataNode="dnTest1">
<table name="tb2" dataNode="dnTest2,dnTest3" rule="rule1" />
</schema>
<!-- 数据节点定义,数据节点由数据源和其他一些参数组织而成。-->
<dataNode name="dnTest1">
<property name="dataSource">
<dataSourceRef>dsTest[]</dataSourceRef>
</property>
</dataNode>
<dataNode name="dnTest2">
<property name="dataSource">
<dataSourceRef>dsTest[]</dataSourceRef>
</property>
</dataNode>
<dataNode name="dnTest3">
<property name="dataSource">
<dataSourceRef>dsTest[]</dataSourceRef>
</property>
</dataNode>
<!-- 数据源定义,数据源是一个具体的后端数据连接的表示。-->
<dataSource name="dsTest" type="mysql">
<property name="location">
<!--注意:替换为您的MySQL IP和Port{数组}-->
<location>192.168.0.1:/dbtest1</location>
<location>192.168.0.1:/dbtest2</location>
<location>192.168.0.1:/dbtest3</location>
</property>
<!--注意:替换为您的MySQL用户名-->
<property name="user">test</property>
<!--注意:替换为您的MySQL密码-->
<property name="password">test</property>
<property name="sqlMode">STRICT_TRANS_TABLES</property>
</dataSource>
</cobar:schema>
上图的配置文件,完成了从dbtest中tb2到dbtest2中的tb2(即192.168.0.1:3306/dbtest2库)和dbtest3中的tb2(即192.168.0.1:3306/dbtest3库)的映射,那么它们是怎么被映射呢,映射算法是在rule.xml中配置的。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE cobar:rule SYSTEM "rule.dtd">
<cobar:rule xmlns:cobar="http://cobar.alibaba.com/">
<!-- 路由规则定义,定义什么表,什么字段,采用什么路由算法。-->
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm><![CDATA[ func1(${id})]]></algorithm>
</rule>
</tableRule>
<!-- 路由函数定义,应用在路由规则的算法定义中,路由函数可以自定义扩展。-->
<function name="func1" class="com.alibaba.cobar.route.function.PartitionByLong">
<property name="partitionCount">2</property>
<property name="partitionLength">512</property>
</function>
</cobar:rule>
上图的rule.xm配置文件,定义了分库规则:按照id字段把tb2表中的数据分配到dnTest2和dnTest3两个分区中,其中id小于512的数据会被放到dnTest2库的分区中,而其余的会被放到dnTest3库的分区中。Server.xml中则配置了地Cobar服务的数据库结构、用户名和密码。在启动Cobar服务之后,使用用户名root和密码passwd就可以登录Cobar服务。启动Cobar服务。
首先使用命令“mysql -h127.0.0.1 -uroot -ppasswd -P8066 -Ddbtest”来登录Cobar服务。登陆:127.0.0.1:8066/dbtest;用户名:root;密码:passwd。
其次使用命令“show database”。
然后在表tb2中插入三条记录,然后我们取看真正的物理数据库,id大于512的被映射到dbtest3中的tb2,而id小于512的被映射到dbtest2中的tb2.


点我吧工作总结(技术篇) Cobar原理和环境搭建的更多相关文章
- springmvc工作原理和环境搭建
SpringMVC工作原理 上面的是springMVC的工作原理图: 1.客户端发出一个http请求给web服务器,web服务器对http请求进行解析,如果匹配DispatcherServle ...
- 1.appium工作原理及环境搭建
1.appium: 是一个自动化测试开源工具,支持 iOS 平台和 Android 平台上的原生应用,web应用和混合应用. 2.工作原理: 3.搭建appium环境: (1)安装python和nod ...
- 基于Selenium2+Java的UI自动化(1) - 原理和环境搭建
一.Selenium2的原理 Selenium1是thoughtworks公司的一个产品经理,为了解决重复烦躁的验收工作,写的一个自动化测试工具,其原理是用JS注入的方 式来模拟人工的操作,但是由于J ...
- monkey 原理,环境搭建、命令详解
一.monkey测试的相关的原理 monkey测试的原理就是利用socket通讯的方式来模拟用户的按键输入,触摸屏输入,手势输入等,看设备多长时间会出异常.当Monkey程序在模拟器或设备运行的时候, ...
- memcache原理及环境搭建、测试
一.原理 Memcache是一个高性能的分布式的内存对象缓存系统,通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像.视频.文件以及数据库检索的结果等.简单 ...
- docker原理学习-环境搭建
1. mac下用VMware虚拟机安装ubunt16.04 2. ubuntu安装并启动ssh服务 3. 用mac终端ssh到虚拟机中 ssh didiyu@ip 输入登陆密码
- RocketMQ(1)---架构原理及环境搭建
一.架构简述 RocketMQ阿里开源的一个分布式消息传递和流媒体平台,具有低延迟,高性能和可靠性, 万亿级容量和灵活的可伸缩性.跟其它中间件相比,RocketMQ的特点是纯JAVA实现,在发生宕机和 ...
- MapReduce工作流程及Shuffle原理概述
引言: 虽然MapReduce计算框架简化了分布式程序设计,将所有的并行程序均需要关注的设计细节抽象成公共模块并交由系统实现,用户只需关注自己的应用程序的逻辑实现,提高了开发效率,但是开发如果对Map ...
- 全网最全最细的appium自动化测试环境搭建教程以及appium工作原理
一.前言 对于appium自动化测试环境的搭建我相信90%的自学者都是在痛苦中挣扎,在挣扎中放弃,在放弃后又重新开始,只有10%的人,人品比较好,能够很快并顺利的搭建成功.appium 自动化测试 ...
随机推荐
- Beats数据采集---Packetbeat\Filebeat\Topbeat\WinlogBeat使用指南
Beats是elastic公司的一款轻量级数据采集产品,它包含了几个子产品: packetbeat(用于监控网络流量). filebeat(用于监听日志数据,可以替代logstash-input-fi ...
- Atitit机器学习原理与概论book attilax总结
Atitit机器学习原理与概论book attilax总结 <机器学习(决战大数据时代!IT技术人员不得不读!)>((美)米歇尔(Mitchell)[简介_书评_在线阅读] -1 < ...
- iOS-性能优化2
性能优化总结2 iOS应用是非常注重用户体验的,不光是要求界面设计合理美观,也要求各种UI的反应灵敏,我相信大家对那种一拖就卡卡卡的 TableView 应用没什么好印象.还记得12306么,那个速度 ...
- react2 react 遍历数组
<body><!-- React 真实 DOM 将会插入到这里 --><div id="example"></div> <!- ...
- Android中的Activity相关知识总结
一.什么是Activity? 简单理解:Activity是Android组件中最基本也是最为常见用的四大组件之一.是一个与用户交互的系统模块,一个Activity通常就是一个单独的屏幕(页面), 它上 ...
- KendoUI系列:AutoComplete
1.基本使用 <link href="@Url.Content("~/C ontent/kendo/2014.1.318/kendo.common.min.css" ...
- LeetCode:Find the Difference_389
LeetCode:Find the Difference [问题再现] Given two strings s and t which consist of only lowercase letter ...
- 初探JavaScript(四)——作用域链和声明提前
前言:最近恰逢毕业季,千千万万的学生党开始步入社会,告别象牙塔似的学校生活.往往在人生的各个拐点的时候,情感丰富,感触颇深,各种对过去的美好的总结,对未来的展望.与此同时,也让诸多的老“园”工看完这些 ...
- 苹果官方发布,iPhone 6 & Plus 设计素材
苹果发布 iPhone 6 和 iPhone 6 Plus 有一段时间了,据说首日预定量达到了创纪录的1600万部,真是不可思议.苹果已经创建了一些指引,让开发者可以受益.他们已经发布了一组苹果官方的 ...
- 3D Grid Effect – 使用 CSS3 制作网格动画效果
今天我们想与大家分享一个小的动画概念.这个梦幻般的效果是在马库斯·埃克特的原型应用程序里发现的.实现的基本思路是对网格项目进行 3D 旋转,扩展成全屏,并呈现内容.我们试图模仿应用程序的行为,因此 ...