每天收获一点点------Hadoop Eclipse插件的使用
本文所用软件版本:myeclipe2014 hadoop1.2.1
1、安装Hadoop开发插件
下载hadoop-eclipse-plugin-1.2.1.jar,拷贝到myeclipse根目录下/dropins目录下。
2、 启动myeclipse,打开Perspective:
【Window】->【Open Perspective】->【Other...】->【Map/Reduce】->【OK】

3、 打开一个View:
【Window】->【Show View】->【Other...】->【MapReduce Tools】->【Map/Reduce Locations】->【OK】

4、 添加Hadoop location:

此处添加自己的hadoop安装路径。
5、new Hadoop location
、

修改其中内容:
Map/Reduce Master 这个框里:这两个参数就是mapred-site.xml里面mapred.job.tracker里面的ip和port
DFS Master 这个框里:这两个参数就是core-site.xml里面fs.default.name里面的ip和port
user name:这个是连接hadoop的用户名
因为我是用root户安装的hadoop,而且没建立其他的用户,所以用root。下面的不用填写。
然后点击finish按钮,此时,这个视图中就有多了一条记录。
修改后:

重启myeclipse并重新编辑刚才建立的那个连接记录,现在我们编辑advance parameters tab页
此页只需修改,其中箭头所示处,后面填core-site.xml里所对应的路径即可。

然后点击finish,然后就连接上了(先要启动sshd服务,启动hadoop进程),连接上的标志如图:

6、再跑wordcount例子
新建Map/Reduce Project:
【File】->【New】->【Project...】->【Map/Reduce】->【Map/Reduce Project】->【Project name: WordCount】->【Configure Hadoop install directory...】->【Hadoop installation directory: usr/local/hadoop/hadoop-1.2.1】->【Apply】->【OK】->【Next】->【Allow output folders for source folders】->【Finish】
新建WordCount类
添加/编写源代码:此代码是hadoop自带的,所以在hadoop安装目录下,如下图:(代码复制过来即可用)

上传模拟数据文件夹:此过程请参考本博客 http://www.cnblogs.com/yangxiao99/p/4574889.html
然后配置运行参数:
在新建的项目WordCount,点击WordCount.java,右键-->Run As-->Run Configurations

点击Run,运行程序
在此刻看到运行结果,如下图:
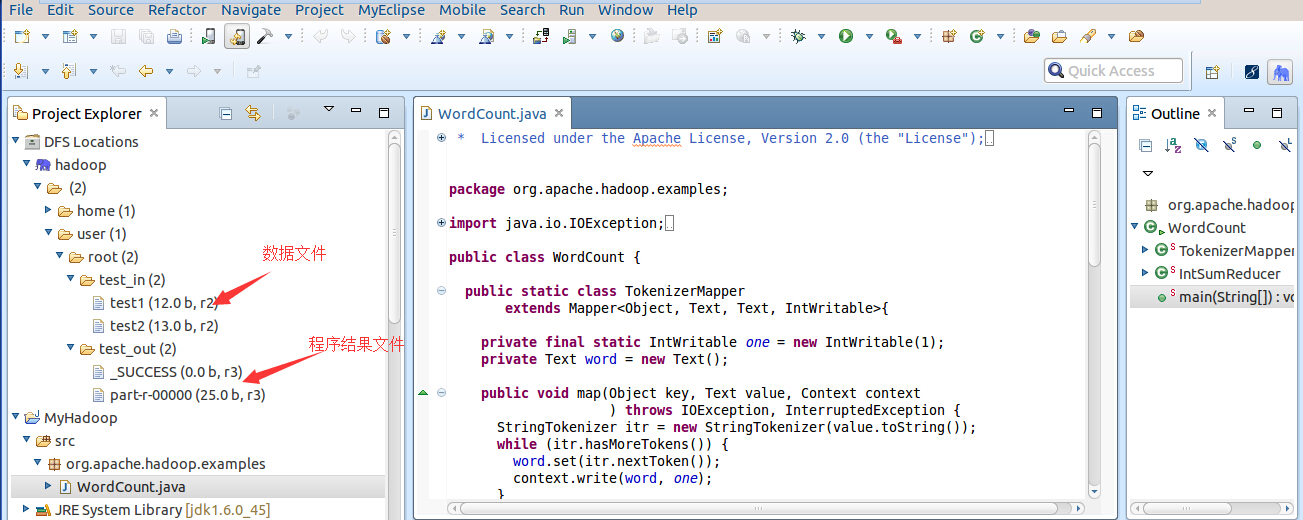
完毕!!!
以上是亲手所写,欢迎各位来探讨交流:QQ:747861092
QQ群:163354117 (群名称:CodeForFuture)
每天收获一点点------Hadoop Eclipse插件的使用的更多相关文章
- Hadoop学习笔记—6.Hadoop Eclipse插件的使用
开篇:Hadoop是一个强大的并行软件开发框架,它可以让任务在分布式集群上并行处理,从而提高执行效率.但是,它也有一些缺点,如编码.调试Hadoop程序的难度较大,这样的缺点直接导致开发人员入门门槛高 ...
- hadoop eclipse插件生成
hadoop eclipse插件生成 做了一年的hadoop开发.还没有自动生成过eclipse插件,一直都是在网上下载别人的用,今天有时间,就把这段遗憾补回来,自己生成一下,废话不说,開始了. 本文 ...
- The command ("dfs.browser.action.delete") is undefined 解决Hadoop Eclipse插件报错
Hadoop Eclipse插件 报错. 使用 hadoop-eclipse-kepler-plugin-2.2.0.jar 如下所示 Error Log 强迫症看了 受不了 The command ...
- 第四章.使用ant编译hadoop eclipse插件
从hadoop 0.20.203以后,hadoop的发布包里,不再对eclipse插件进行jar包发布,而是给出了打包的代码,需要各位开发人员自己进行打包和设置.我们打的包必须跟自己使用的hadoop ...
- Hadoop Eclipse 插件制作以及安装
在本地使用Eclipse调试MapReduce程序,需要Hadoop插件,笔摘记录下制作安装过程. 准备工作(hadoop-2.6.0为例): 搭建好Hadoop环境 下载Hadoop安装包,解压到某 ...
- Hadoop eclipse插件使用过程中出现的问题
http://download.csdn.net/detail/java2000_wl/4326323 转自http://www.ithao123.cn/content-945210.html 由于h ...
- hadoop —— eclipse插件安装配置
安装: 1. 将hadoop-core-0.20.2-cdh3u6/contrib/eclipse-plugin/hadoop-eclipse-plugin-0.20.2-cdh3u6.jar拷贝到e ...
- 更新 hadoop eclipse 插件
卸载hadoop 1.1.2插件.并安装新版hadoop 2.2.0插件. 假设直接删除eclipse plugin文件夹下的hadoop 1.1.2插件,会导致hadoop 1.1.2插件残留在ec ...
- 每天收获一点点------Hadoop RPC机制的使用
一.RPC基础概念 1.1 RPC的基础概念 RPC,即Remote Procdure Call,中文名:远程过程调用: (1)它允许一台计算机程序远程调用另外一台计算机的子程序,而不用去关心底层的网 ...
随机推荐
- veridata实验例(3)验证veridata发现insert操作不会导致同步
veridata实验例(3)验证veridata发现insert操作不会导致同步 续接:<veridata实验举例(2)验证表BONUS与表SALGRADE两节点同步情况>,地址:点击打开 ...
- error: png.h not found.
跑php设备 --enable-mbstring --enable-ftp --enable-gd-native-ttf --with-openssl --enable-pcntl --enable- ...
- JAVA学习课第二十八届(多线程(七))- 停止-threaded多-threaded面试题
主密钥 /* * wait 和 sleep 差别? * 1.wait能够指定时间也能够不指定 * sleep必须指定时间 * 2.在同步中,对CPU的运行权和锁的处理不同 * wait释放运 ...
- centos安装和卸载软件
==如何卸载: 1.打开一个SHELL终端 2.因为Linux下的软件名都包括版本号,所以卸载前最好先确定这个软件的完整名称. 查找RPM包软件:rpm -qa ×××* 注意:×××指软件名称开头的 ...
- WPF技术触屏上的应用系列(五): 图片列表异步加载、手指进行缩小、放大、拖动 、惯性滑入滑出等效果
原文:WPF技术触屏上的应用系列(五): 图片列表异步加载.手指进行缩小.放大.拖动 .惯性滑入滑出等效果 去年某客户单位要做个大屏触屏应用,要对档案资源进行展示之用.客户端是Window7操作系统, ...
- V微软S2015下载:开展Win10/Linux/iOS多平台软件
微软VS2015下载:开展Win10/Linux/iOS多平台软件 资源:IT之家作者:子非 责任编辑:子非 11月13日消息,微软刚刚宣布了 Visual Studio 2015 ...
- ReactJS学习 相关网站
React 入门实例教程-阮一峰 http://www.ruanyifeng.com/blog/2015/03/react.html汇智网-React 互动学习http://hubwiz.com/co ...
- iOS发展- backBarButtonItem 颜色/文字修改
iOS7之后. 默认返回button字体颜色为蓝色, 在父母的陈列柜VC(老界面)的title 假设做出改变, 通过下面的方法可以: 1. 更改字体颜色 (1) 在plist里面, 加View con ...
- .NET 4 并行(多核)编程系列之二 从Task开始
原文:.NET 4 并行(多核)编程系列之二 从Task开始 .NET 4 并行(多核)编程系列之二 从Task开始 前言:我们一步步的从简单的开始讲述,还是沿用我一直的方式:慢慢演化,步步为营. ...
- 【Bootstrap】自己主动去适应PC、平面、手机Bootstrap网格系统
酒吧格英语作为一门系统"grid systems",也有人翻译成"网络格系统".使用固定格子设计布局,其风格整齐而简洁,在二战结束后人气,流风格之中的一个. 1 ...