Hadoop学习笔记—12.MapReduce中的常见算法
一、MapReduce中有哪些常见算法
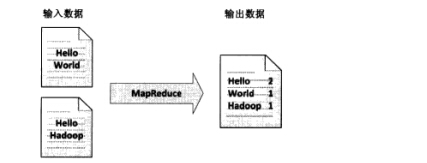
(1)经典之王:单词计数
这个是MapReduce的经典案例,经典的不能再经典了!
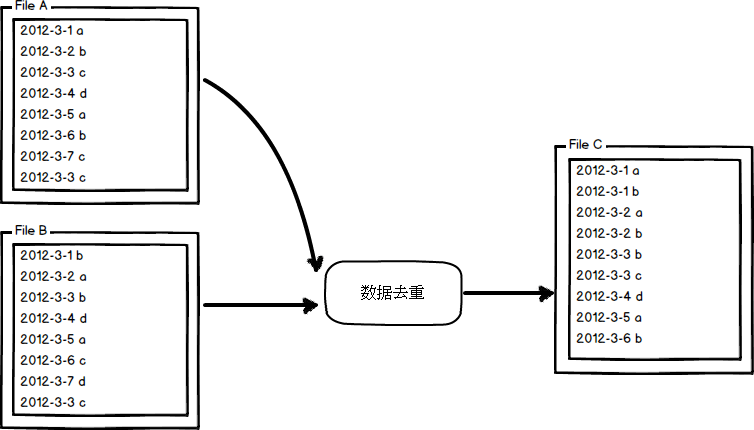
(2)数据去重
"数据去重"主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重。
(3)排序:按某个Key进行升序或降序排列
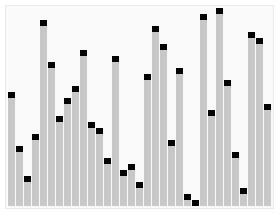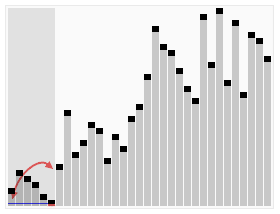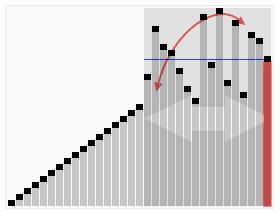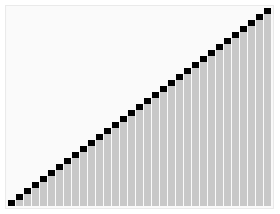
(4)TopK:对源数据中所有数据进行排序,取出前K个数据,就是TopK。
通常可以借助堆(Heap)来实现TopK问题。
(5)选择:关系代数基本操作再现
从指定关系中选择出符合条件的元组(记录)组成一个新的关系。在关系代数中,选择运算是针对元组的运算。
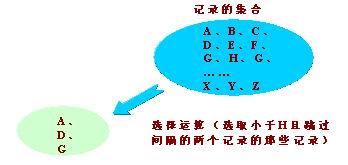
在MapReduce中,以求最大最小值为例,从N行数据中取出一行最小值,这就是一个典型的选择操作。
(6)投影:关系代数基本操作再现
从指定关系的属性(字段)集合中选取部分属性组成同类的一个新关系。由于属性减少而出现的重复元组被自动删除。投影运算针对的是属性。

在MapReduce中,以前面的处理手机上网日志为例,在日志中的11个字段中我们选出了五个字段来显示我们的手机上网流量就是一个典型的投影操作。
(7)分组:Group By XXXX
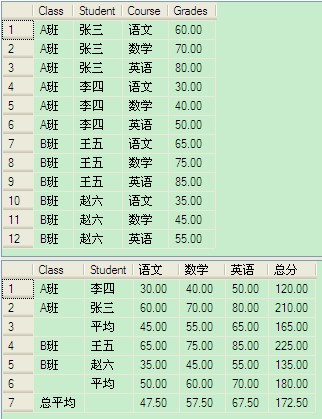
在MapReduce中,分组类似于分区操作,以处理手机上网日志为例,我们分为了手机号和非手机号这样的两个组来分别处理。
(8)多表连接
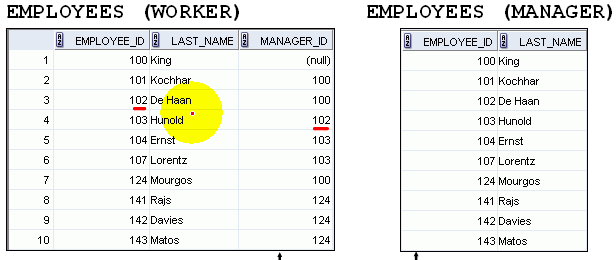
(9)单表关联

二、TopK一般类型之前K个问题
TopK问题是一个很常见的实际问题:在一大堆的数据中如何高效地找出前K个最大/最小的数据。我们以前的做法一般是将整个数据文件都加载到内存中,进行排序和统计。但是,当数据文件达到一定量时,这时是无法直接全部加载到内存中的,除非你想冒着宕机的危险。
这时我们想到了分布式计算,利用计算机集群来做这个事,打个比方:本来一台机器需要10小时才能完成的事,现在10台机器并行地来计算,只需要1小时就可以完成。本次我们使用一个随机生成的100万个数字的文件,也就是说我们要做的就是在100万个数中找到最大的前100个数字。
实验数据下载地址:http://pan.baidu.com/s/1qWt4WaS
2.1 利用TreeMap存储前K个数据
(1)红黑树的实现
如何存储前K个数据时TopK问题的一大核心,这里我们采用Java中TreeMap来进行存储。TreeMap的实现是红黑树算法的实现,红黑树又称红-黑二叉树,它首先是一棵二叉树,它具体二叉树所有的特性,同时红黑树更是一棵自平衡的排序二叉树。
平衡二叉树必须具备如下特性:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。也就是说该二叉树的任何一个等等子节点,其左右子树的高度都相近。
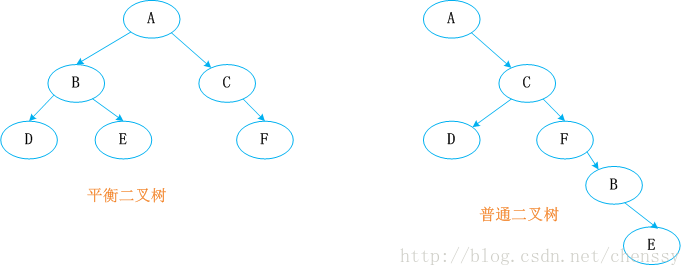
红黑树顾名思义就是:节点是红色或者黑色的平衡二叉树,它通过颜色的约束来维持着二叉树的平衡。

About:关于TreeMap与红黑树的详细介绍可以阅读chenssy的一篇文章:TreeMap与红黑树 ,这里不再赘述。
(2)TreeMap中的put方法
在TreeMap的put()的实现方法中主要分为两个步骤,第一:构建排序二叉树,第二:平衡二叉树。
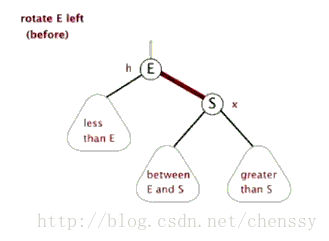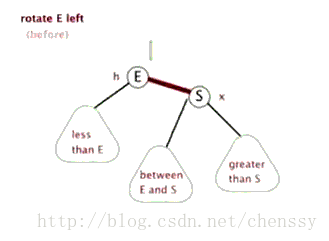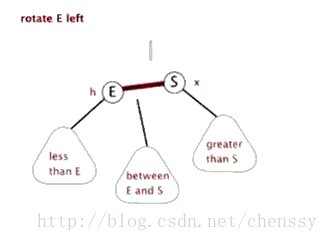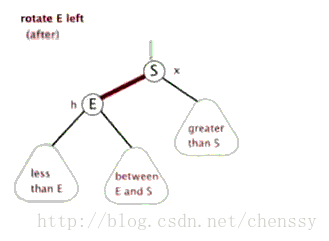
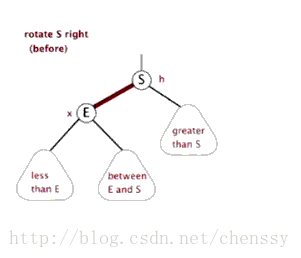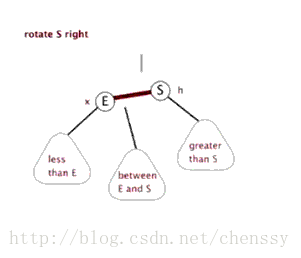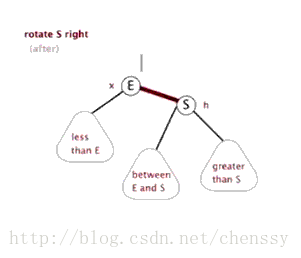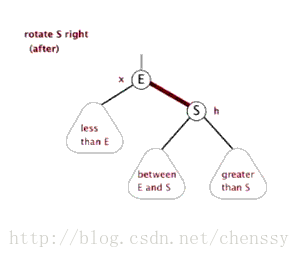
为了平衡二叉树,往往需要进行左旋和右旋以及着色操作,这里看看左旋和右旋操作,这些操作的目的都是为了维持平衡,保证二叉树是有序的,可以帮助我们实现有序的效果,即数据的存储是有序的。
2.2 编写map和reduce函数代码
(1)map函数
public static class MyMapper extends
Mapper<LongWritable, Text, NullWritable, LongWritable> {
public static final int K = 100;
private TreeMap<Long, Long> tm = new TreeMap<Long, Long>(); protected void map(
LongWritable key,
Text value,
Mapper<LongWritable, Text, NullWritable, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
try {
long temp = Long.parseLong(value.toString().trim());
tm.put(temp, temp);
if (tm.size() > K) {
tm.remove(tm.firstKey());
// 如果是求topk个最小的那么使用下面的语句
//tm.remove(tm.lastKey());
}
} catch (Exception e) {
context.getCounter("TopK", "errorLog").increment(1L);
}
}; protected void cleanup(
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, NullWritable, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
for (Long num : tm.values()) {
context.write(NullWritable.get(), new LongWritable(num));
}
};
}
cleanup()方法是在map方法结束之后才会执行的方法,这里我们将在该map任务中的前100个数据传入reduce任务中;
(2)reduce函数
public static class MyReducer extends
Reducer<NullWritable, LongWritable, NullWritable, LongWritable> {
public static final int K = 100;
private TreeMap<Long, Long> tm = new TreeMap<Long, Long>(); protected void reduce(
NullWritable key,
java.lang.Iterable<LongWritable> values,
Reducer<NullWritable, LongWritable, NullWritable, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
for (LongWritable num : values) {
tm.put(num.get(), num.get());
if (tm.size() > K) {
tm.remove(tm.firstKey());
// 如果是求topk个最小的那么使用下面的语句
//tm.remove(tm.lastKey());
}
}
// 按降序即从大到小排列Key集合
for (Long value : tm.descendingKeySet()) {
context.write(NullWritable.get(), new LongWritable(value));
}
};
}
在reduce方法中,依次将map方法中传入的数据放入TreeMap中,并依靠红黑色的平衡特性来维持数据的有序性。
(3)完整代码
package algorithm; import java.net.URI;
import java.util.TreeMap; import mapreduce.MyWordCountJob.MyMapper;
import mapreduce.MyWordCountJob.MyReducer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapred.TestJobCounters.NewIdentityReducer;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class MyTopKNumJob extends Configured implements Tool { /**
* @author Edison Chou
* @version 1.0
*/
public static class MyMapper extends
Mapper<LongWritable, Text, NullWritable, LongWritable> {
public static final int K = 100;
private TreeMap<Long, Long> tm = new TreeMap<Long, Long>(); protected void map(
LongWritable key,
Text value,
Mapper<LongWritable, Text, NullWritable, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
try {
long temp = Long.parseLong(value.toString().trim());
tm.put(temp, temp);
if (tm.size() > K) {
//tm.remove(tm.firstKey());
// 如果是求topk个最小的那么使用下面的语句
tm.remove(tm.lastKey());
}
} catch (Exception e) {
context.getCounter("TopK", "errorLog").increment(1L);
}
}; protected void cleanup(
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, NullWritable, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
for (Long num : tm.values()) {
context.write(NullWritable.get(), new LongWritable(num));
}
};
} /**
* @author Edison Chou
* @version 1.0
*/
public static class MyReducer extends
Reducer<NullWritable, LongWritable, NullWritable, LongWritable> {
public static final int K = 100;
private TreeMap<Long, Long> tm = new TreeMap<Long, Long>(); protected void reduce(
NullWritable key,
java.lang.Iterable<LongWritable> values,
Reducer<NullWritable, LongWritable, NullWritable, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
for (LongWritable num : values) {
tm.put(num.get(), num.get());
if (tm.size() > K) {
//tm.remove(tm.firstKey());
// 如果是求topk个最小的那么使用下面的语句
tm.remove(tm.lastKey());
}
}
// 按降序即从大到小排列Key集合
for (Long value : tm.descendingKeySet()) {
context.write(NullWritable.get(), new LongWritable(value));
}
};
} // 输入文件路径
public static String INPUT_PATH = "hdfs://hadoop-master:9000/testdir/input/seq100w.txt";
// 输出文件路径
public static String OUTPUT_PATH = "hdfs://hadoop-master:9000/testdir/output/topkapp"; @Override
public int run(String[] args) throws Exception {
// 首先删除输出路径的已有生成文件
FileSystem fs = FileSystem.get(new URI(INPUT_PATH), getConf());
Path outPath = new Path(OUTPUT_PATH);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
} Job job = new Job(getConf(), "TopKNumberJob");
// 设置输入目录
FileInputFormat.setInputPaths(job, new Path(INPUT_PATH));
// 设置自定义Mapper
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置自定义Reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(LongWritable.class);
// 设置输出目录
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); return job.waitForCompletion(true) ? 0 : 1;
} public static void main(String[] args) {
Configuration conf = new Configuration();
// map端输出启用压缩
conf.setBoolean("mapred.compress.map.output", true);
// reduce端输出启用压缩
conf.setBoolean("mapred.output.compress", true);
// reduce端输出压缩使用的类
conf.setClass("mapred.output.compression.codec", GzipCodec.class,
CompressionCodec.class); try {
int res = ToolRunner.run(conf, new MyTopKNumJob(), args);
System.exit(res);
} catch (Exception e) {
e.printStackTrace();
}
} }
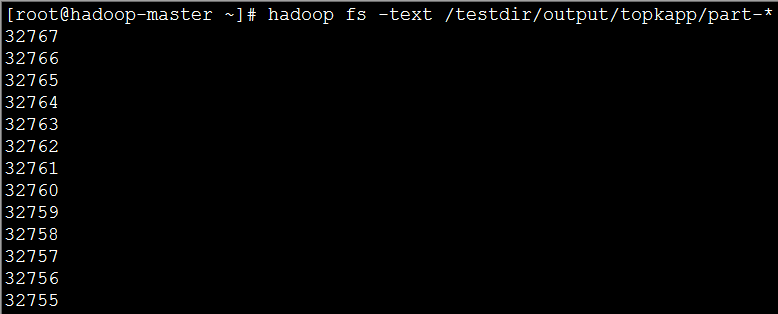
(4)实现效果:图片大小有限,这里只显示了前12个;
三、TopK特殊类型之最值问题
最值问题是一个典型的选择操作,从100万个数字中找到最大或最小的一个数字,在本次实验文件中,最大的数字时32767。现在,我们就来改写代码,找到32767。
3.1 改写map函数
public static class MyMapper extends
Mapper<LongWritable, Text, LongWritable, NullWritable> {
long max = Long.MIN_VALUE; protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, LongWritable, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
long temp = Long.parseLong(value.toString().trim());
if (temp > max) {
max = temp;
}
}; protected void cleanup(
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, LongWritable, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
context.write(new LongWritable(max), NullWritable.get());
};
}
是不是很熟悉?其实就是依次与假设的最大值进行比较。
3.2 改写reduce函数
public static class MyReducer extends
Reducer<LongWritable, NullWritable, LongWritable, NullWritable> {
long max = Long.MIN_VALUE; protected void reduce(
LongWritable key,
java.lang.Iterable<NullWritable> values,
Reducer<LongWritable, NullWritable, LongWritable, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
long temp = key.get();
if (temp > max) {
max = temp;
}
}; protected void cleanup(
org.apache.hadoop.mapreduce.Reducer<LongWritable, NullWritable, LongWritable, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
context.write(new LongWritable(max), NullWritable.get());
};
}
在reduce方法中,继续对各个map任务传入的数据进行比较,还是依次地与假设的最大值进行比较,最后所有reduce方法执行完成后通过cleanup方法对最大值进行输出。
最终的完整代码如下:
package algorithm; import java.net.URI; import mapreduce.MyWordCountJob.MyMapper;
import mapreduce.MyWordCountJob.MyReducer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class MyMaxNumJob extends Configured implements Tool { /**
* @author Edison Chou
* @version 1.0
*/
public static class MyMapper extends
Mapper<LongWritable, Text, LongWritable, NullWritable> {
long max = Long.MIN_VALUE; protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, LongWritable, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
long temp = Long.parseLong(value.toString().trim());
if (temp > max) {
max = temp;
}
}; protected void cleanup(
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, LongWritable, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
context.write(new LongWritable(max), NullWritable.get());
};
} /**
* @author Edison Chou
* @version 1.0
*/
public static class MyReducer extends
Reducer<LongWritable, NullWritable, LongWritable, NullWritable> {
long max = Long.MIN_VALUE; protected void reduce(
LongWritable key,
java.lang.Iterable<NullWritable> values,
Reducer<LongWritable, NullWritable, LongWritable, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
long temp = key.get();
if (temp > max) {
max = temp;
}
}; protected void cleanup(
org.apache.hadoop.mapreduce.Reducer<LongWritable, NullWritable, LongWritable, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
context.write(new LongWritable(max), NullWritable.get());
}; } // 输入文件路径
public static String INPUT_PATH = "hdfs://hadoop-master:9000/testdir/input/seq100w.txt";
// 输出文件路径
public static String OUTPUT_PATH = "hdfs://hadoop-master:9000/testdir/output/topkapp"; @Override
public int run(String[] args) throws Exception {
// 首先删除输出路径的已有生成文件
FileSystem fs = FileSystem.get(new URI(INPUT_PATH), getConf());
Path outPath = new Path(OUTPUT_PATH);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
} Job job = new Job(getConf(), "MaxNumberJob");
// 设置输入目录
FileInputFormat.setInputPaths(job, new Path(INPUT_PATH));
// 设置自定义Mapper
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(NullWritable.class);
// 设置自定义Reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(NullWritable.class);
// 设置输出目录
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); System.exit(job.waitForCompletion(true) ? 0 : 1);
return 0;
} public static void main(String[] args) {
Configuration conf = new Configuration();
// map端输出启用压缩
conf.setBoolean("mapred.compress.map.output", true);
// reduce端输出启用压缩
conf.setBoolean("mapred.output.compress", true);
// reduce端输出压缩使用的类
conf.setClass("mapred.output.compression.codec", GzipCodec.class,
CompressionCodec.class); try {
int res = ToolRunner.run(conf, new MyMaxNumJob(), args);
System.exit(res);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.3 查看实现效果

可以看出,我们的程序已经求出了最大值:32767。虽然例子很简单,业务也很简单,但是我们引入了分布式计算的思想,将MapReduce应用在了最值问题之中,就是一个进步了!
参考资料
(1)吴超,《深入浅出Hadoop》:http://www.superwu.cn/
(2)Suddenly,《Hadoop日记Day18-MapReduce排序和分组》:http://www.cnblogs.com/sunddenly/p/4009751.html
(3)chenssy,《Java提高篇(27)—TreeMap》:http://blog.csdn.net/chenssy/article/details/26668941
Hadoop学习笔记—12.MapReduce中的常见算法的更多相关文章
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop学习笔记: MapReduce Java编程简介
概述 本文主要基于Hadoop 1.0.0后推出的新Java API为例介绍MapReduce的Java编程模型.新旧API主要区别在于新API(org.apache.hadoop.mapreduce ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- hadoop 学习笔记:mapreduce框架详解(转)
原文:http://www.cnblogs.com/sharpxiajun/p/3151395.html(有删减) Mapreduce运行机制 下面我贴出几张图,这些图都是我在百度图片里找到的比较好的 ...
- Hadoop学习笔记: MapReduce二次排序
本文给出一个实现MapReduce二次排序的例子 package SortTest; import java.io.DataInput; import java.io.DataOutput; impo ...
- Linux学习笔记12——Unix中的进程
通过调用fork和exec函数都能创建新的进程,但两者有着本质的区别:fork函数拷贝了父进程的内存映像,而exec函数用用新的映像来覆盖调用进程的进程映像的功能. 一 fork函数 #includ ...
- OpenCV学习笔记(12)——OpenCV中的轮廓
什么是轮廓 找轮廓.绘制轮廓等 1.什么是轮廓 轮廓可看做将连续的点(连着边界)连在一起的曲线,具有相同的颜色和灰度.轮廓在形态分析和物体的检测和识别中很有用. 为了更加准确,要使用二值化图像.在寻找 ...
随机推荐
- 【DWR系列04】- DWR配置详解
table { margin-left: 30px; width: 90%; border: 1px; border-collapse: collapse } img { border: 1px so ...
- maven权威指南学习笔记(二)——安装、运行、获取帮助
这部分在网上很容易找到详细教程,这里就略写了. 基础:系统有配置好的jdk,通过 命令行 java -version,有类似下面的提示,表示java环境以配好 下载maven:官网 http://ma ...
- 安装openssl 扩展的时候出现Cannot find config.m4. Make sure that you run '/usr/local/php/bin/phpize' in the top level source directory of the module的解决方法
进入php源码包目录:cd /usr/local/php-5.6.25/ext/openssl 执行命令: cp ./config0.m4 ./config.m4 即可
- filefiter
1.写一个类继承与FileFilter package com.dream.musicplayer; import <a href="http://lib.csdn.net/base/ ...
- openswan-ipsec.conf配置说明
Name ipsec.conf - IPsec configuration and connections Description The optional ipsec.conf file speci ...
- Mac使用总结
显示隐藏文件 终端输入:defaults write com.apple.finder AppleShowAllFiles -bool true; KillAll Finder 添加SSHKey Ma ...
- 头显HTC Vive北美直降100美元,中国区降价活动今日公布
如果你现在想要购买一台VR头显,591ARVR资讯网www.591arvr.com的小编提醒大家可以等一等,在即将到来的年末促销中各种VR设备都将迎来大力度降价.目前北美市场的HTC Vive已经直降 ...
- centos中docker mongodb 配置
安装docker,对于Centos7,如下: $ sudo yum update$ sudo yum -y install docker$ sudo systemctl start docker 首先 ...
- Artifact Project3:war exploded: Error during artifact deployment. See server log for details.
第一次建Struts2 idea遇到了这个问题,很莫名其妙,搞了几天没解决,几乎要放弃idea了.最后解决的时候也很突然.回想解决的过程,大致如下. 第一种情况:File->Project St ...
- 创建Chrome启动器
今天清理垃圾时不知怎么把chrome启动器删除了,现在要重新创建一个 1.在桌面创建一个chrome.exe的快捷键方式,属性更改目标为: "C:\Program Files (x86)\G ...