Redis中7种集合类型应用场景&redis常用命令
Redis常用数据类型
Redis最为常用的数据类型主要有以下五种:
- String
- Hash
- List
- Set
- Sorted set
在具体描述这几种数据类型之前,我们先通过一张图了解下Redis内部内存管理中是如何描述这些不同数据类型的:
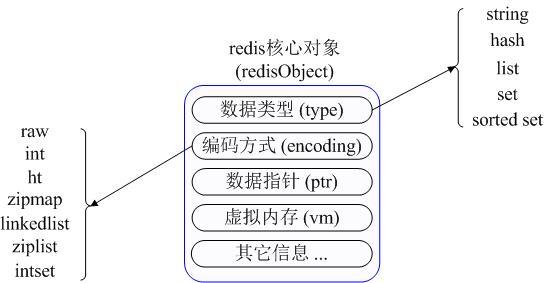
首先Redis内部使用一个redisObject对象来表示所有的key和value,redisObject最主要的信息如上图所示:type代表一个value对象具体是何种数据类型,encoding是不同数据类型在redis内部的存储方式,比如:type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如:"123" "456"这样的字符串。
这里需要特殊说明一下vm字段,只有打开了Redis的虚拟内存功能,此字段才会真正的分配内存,该功能默认是关闭状态的,该功能会在后面具体描述。通过上图我们可以发现Redis使用redisObject来表示所有的key/value数据是比较浪费内存的,当然这些内存管理成本的付出主要也是为了给Redis不同数据类型提供一个统一的管理接口,实际作者也提供了多种方法帮助我们尽量节省内存使用,我们随后会具体讨论。
Strings
Strings 数据结构是简单的key-value类型,value其实不仅是String,也可以是数字。使用Strings类型,你可以完全实现目前 Memcached 的功能,并且效率更高。还可以享受Redis的定时持久化,操作日志及 Replication等功能。除了提供与 Memcached 一样的get、set、incr、decr 等操作外,Redis还提供了下面一些操作:
获取字符串长度
往字符串append内容
设置和获取字符串的某一段内容
设置及获取字符串的某一位(bit)
批量设置一系列字符串的内容
常用命令:
set,get,decr,incr,mget 等
应用场景:
String是最常用的一种数据类型,普通的key/value存储都可以归为此类,这里就不所做解释了。
实现方式:
String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr,decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
Hashs
在Memcached中,我们经常将一些结构化的信息打包成hashmap,在客户端序列化后存储为一个字符串的值,比如用户的昵称、年龄、性别、积分等,这时候在需要修改其中某一项时,通常需要将所有值取出反序列化后,修改某一项的值,再序列化存储回去。这样不仅增大了开销,也不适用于一些可能并发操作的场合(比如两个并发的操作都需要修改积分)。而Redis的Hash结构可以使你像在数据库中Update一个属性一样只修改某一项属性值。
常用命令:
hget,hset,hgetall 等。
应用场景:
我们简单举个实例来描述下Hash的应用场景,比如我们要存储一个用户信息对象数据,包含以下信息:
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储,主要有以下2种存储方式:
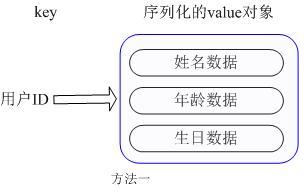
第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
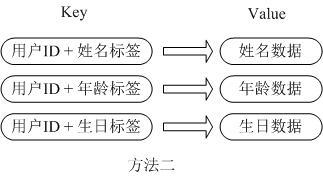
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对儿,用用户ID+对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户ID为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的。
那么Redis提供的Hash很好的解决了这个问题,Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口,如下图:

也就是说,Key仍然是用户ID, value是一个Map,这个Map的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。很好的解决了问题。
这里同时需要注意,Redis提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部Map的成员很多,那么涉及到遍历整个内部Map的操作,由于Redis单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应,这点需要格外注意。
实现方式:
上面已经说到Redis Hash对应Value内部实际就是一个HashMap,实际这里会有2种不同实现,这个Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,对应的value redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
Lists
Lists 就是链表,相信略有数据结构知识的人都应该能理解其结构。使用Lists结构,我们可以轻松地实现最新消息排行等功能。Lists的另一个应用就是消息队列,可以利用Lists的PUSH操作,将任务存在Lists中,然后工作线程再用POP操作将任务取出进行执行。Redis还提供了操作Lists中某一段的api,你可以直接查询,删除Lists中某一段的元素。
常用命令:
lpush,rpush,lpop,rpop,lrange等。
应用场景:
Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现,比较好理解,这里不再重复。
实现方式:
Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
Sets
Sets 就是一个集合,集合的概念就是一堆不重复值的组合。利用Redis提供的Sets数据结构,可以存储一些集合性的数据,比如在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
常用命令:
sadd,spop,smembers,sunion 等。
应用场景:
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
实现方式:
set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
Sorted Sets
和Sets相比,Sorted Sets增加了一个权重参数score,使得集合中的元素能够按score进行有序排列,比如一个存储全班同学成绩的Sorted Sets,其集合value可以是同学的学号,而score就可以是其考试得分,这样在数据插入集合的时候,就已经进行了天然的排序。另外还可以用Sorted Sets来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
常用命令:
zadd,zrange,zrem,zcard等
使用场景:
Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
实现方式:
Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
Pub/Sub
Pub/Sub 从字面上理解就是发布(Publish)与订阅(Subscribe),在Redis中,你可以设定对某一个key值进行消息发布及消息订阅,当一个key值上进行了消息发布后,所有订阅它的客户端都会收到相应的消息。这一功能最明显的用法就是用作实时消息系统,比如普通的即时聊天,群聊等功能。
Transactions
谁说NoSQL都不支持事务,虽然Redis的Transactions提供的并不是严格的ACID的事务(比如一串用EXEC提交执行的命令,在执行中服务器宕机,那么会有一部分命令执行了,剩下的没执行),但是这个Transactions还是提供了基本的命令打包执行的功能(在服务器不出问题的情况下,可以保证一连串的命令是顺序在一起执行的,中间有会有其它客户端命令插进来执行)。Redis还提供了一个Watch功能,你可以对一个key进行Watch,然后再执行Transactions,在这过程中,如果这个Watched的值进行了修改,那么这个Transactions会发现并拒绝执行。
连接操作相关的命令
quit:关闭连接(connection)
auth:简单密码认证
持久化
save:将数据同步保存到磁盘
bgsave:将数据异步保存到磁盘
lastsave:返回上次成功将数据保存到磁盘的Unix时戳
shundown:将数据同步保存到磁盘,然后关闭服务
远程服务控制
info:提供服务器的信息和统计
monitor:实时转储收到的请求
slaveof:改变复制策略设置
config:在运行时配置Redis服务器
对value操作的命令
exists(key):确认一个key是否存在
del(key):删除一个key
type(key):返回值的类型
keys(pattern):返回满足给定pattern的所有key
randomkey:随机返回key空间的一个
keyrename(oldname, newname):重命名key
dbsize:返回当前数据库中key的数目
expire:设定一个key的活动时间(s)
ttl:获得一个key的活动时间
select(index):按索引查询
move(key, dbindex):移动当前数据库中的key到dbindex数据库
flushdb:删除当前选择数据库中的所有key
flushall:删除所有数据库中的所有key
对String操作的命令
set(key, value):给数据库中名称为key的string赋予值value
get(key):返回数据库中名称为key的string的value
getset(key, value):给名称为key的string赋予上一次的value
mget(key1, key2,…, key N):返回库中多个string的value
setnx(key, value):添加string,名称为key,值为value
setex(key, time, value):向库中添加string,设定过期时间time
mset(key N, value N):批量设置多个string的值
msetnx(key N, value N):如果所有名称为key i的string都不存在
incr(key):名称为key的string增1操作
incrby(key, integer):名称为key的string增加integer
decr(key):名称为key的string减1操作
decrby(key, integer):名称为key的string减少integer
append(key, value):名称为key的string的值附加value
substr(key, start, end):返回名称为key的string的value的子串
对List操作的命令
rpush(key, value):在名称为key的list尾添加一个值为value的元素
lpush(key, value):在名称为key的list头添加一个值为value的 元素
llen(key):返回名称为key的list的长度
lrange(key, start, end):返回名称为key的list中start至end之间的元素
ltrim(key, start, end):截取名称为key的list
lindex(key, index):返回名称为key的list中index位置的元素
lset(key, index, value):给名称为key的list中index位置的元素赋值
lrem(key, count, value):删除count个key的list中值为value的元素
lpop(key):返回并删除名称为key的list中的首元素
rpop(key):返回并删除名称为key的list中的尾元素
blpop(key1, key2,… key N, timeout):lpop命令的block版本。
brpop(key1, key2,… key N, timeout):rpop的block版本。
rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
对Set操作的命令
sadd(key, member):向名称为key的set中添加元素member
srem(key, member) :删除名称为key的set中的元素member
spop(key) :随机返回并删除名称为key的set中一个元素
smove(srckey, dstkey, member) :移到集合元素
scard(key) :返回名称为key的set的基数
sismember(key, member) :member是否是名称为key的set的元素
sinter(key1, key2,…key N) :求交集
sinterstore(dstkey, (keys)) :求交集并将交集保存到dstkey的集合
sunion(key1, (keys)) :求并集
sunionstore(dstkey, (keys)) :求并集并将并集保存到dstkey的集合
sdiff(key1, (keys)) :求差集
sdiffstore(dstkey, (keys)) :求差集并将差集保存到dstkey的集合
smembers(key) :返回名称为key的set的所有元素
srandmember(key) :随机返回名称为key的set的一个元素
对Hash操作的命令
hset(key, field, value):向名称为key的hash中添加元素field
hget(key, field):返回名称为key的hash中field对应的value
hmget(key, (fields)):返回名称为key的hash中field i对应的value
hmset(key, (fields)):向名称为key的hash中添加元素field
hincrby(key, field, integer):将名称为key的hash中field的value增加integer
hexists(key, field):名称为key的hash中是否存在键为field的域
hdel(key, field):删除名称为key的hash中键为field的域
hlen(key):返回名称为key的hash中元素个数
hkeys(key):返回名称为key的hash中所有键
hvals(key):返回名称为key的hash中所有键对应的value
hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
Redis中7种集合类型应用场景&redis常用命令的更多相关文章
- Redis中7种集合类型应用场景
StringsStrings 数据结构是简单的key-value类型,value其实不仅是String,也可以是数字.使用Strings类型,你可以完全实现目前 Memcached 的功能,并且效率更 ...
- Redis 中 5 种数据结构的使用场景介绍
这篇文章主要介绍了Redis中5种数据结构的使用场景介绍,本文对Redis中的5种数据类型String.Hash.List.Set.Sorted Set做了讲解,需要的朋友可以参考下 一.redis ...
- Redis中5种数据结构的使用场景介绍
转载于:http://www.itxuexiwang.com/a/shujukujishu/redis/2016/0216/108.html?1455861435 一.redis 数据结构使用场景 原 ...
- Redis中5种数据结构的使用场景
一.redis 数据结构使用场景 原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的源码.目前目标是吃透 redis 的数据结构.我们都知道,在 ...
- Redis学习笔记之Redis中5种数据结构的使用场景介绍
原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的源码.目前目标是吃透 redis 的数据结构.我们都知道,在 redis 中一共有5种数据结构 ...
- redis的五种数据类型及应用场景
前言 redis是用键值对的形式来保存数据,键类型只能是String,但是值类型可以有String.List.Hash.Set.Sorted Set五种,来满足不同场景的特定需求. 本博客中的示例不是 ...
- c# 操作Redis的五种基本类型总结
在我们的项目中,通常会把数据存储到关系型数据库中,比如Oracle,SQL Server,Mysql等,但是关系型数据库对于并发的支持并不是很强大,这样就会造成系统的性能不佳,而且存储的数据多为结构化 ...
- 第二百九十九节,python操作redis缓存-SortSet有序集合类型,可以理解为有序列表
python操作redis缓存-SortSet有序集合类型,可以理解为有序列表 有序集合,在集合的基础上,为每元素排序:元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值, ...
- 从Redis中删除大集合对象的方法
Redis中的大集合对象,如set.zset等,如果有上千万个元素,一般是不能直接用del命令来删除的,因为del命令可能会耗时几秒钟,而redis本身是单线程的,在高并发的情况下会阻塞大量的请求,严 ...
随机推荐
- php安全的改进以及检测文件是否被篡改
可以使用svn的check for modifications//查看更改 至于缓存的php模板文件 可以查找以下执行命令的函数是否存在phpinfo,eval,exec,passthru,shell ...
- Oracle 12c RAC 搭建手册
1 共享设备配置 1.1 设备划分说明 冗余策略 卷划分及大小说明 OCRVOTING Ocrvoting01 8G Ocrvoting02 8G Ocrvoting03 8G ...
- HTML兼容性设置
今天碰到了兼容性问题,页面显示空白,打开调试界面,显示信息 “Compatibility View because 'Display intranet sites in Compatibility V ...
- Python_进程、线程及协程
一.Python进程 IO密集型----多线程 计算密集型----多进程 1.单进程 from multiprocessing import Process def foo(i): print('你好 ...
- mfs-管理员
http://www.moosefs.org/http://moosefs.com/download.html 两个手册于2015/03/05阅完 moosefs-installation moose ...
- cache与负载均衡
cache 客户端CACHE客户端CACHE,包括浏览器本身的缓存.FLASH存储等,用于存储一些临时的文件或者变化不大或无变化的数据:1.如浏览器自动将用户浏览的网页存储在用户的硬盘上,下次再浏览相 ...
- 【转】 CSS3阴影 box-shadow的使用和技巧总结
text-shadow是给文本添加阴影效果,box-shadow是给元素块添加周边阴影效果.随着html5和CSS3的普及,这一特殊效果使用越来越普遍. 基本语法是{box-shadow:[inset ...
- 运行ASP程序报错
错误提示: An error occurred on the server when processing the URL. Please contact the system administrat ...
- C# MDI 子窗体被父窗体控件挡住
using System.Runtime.InteropServices; [DllImport("user32")] public static extern int SetPa ...
- Servlet Filter 3
11.MD5加密 /** * 使用md5的算法进行加密 */ public static String md5(String plainText) { byte[] secretBytes = nul ...