TVM:使用自动调度优化算子
与基于模板的AutoTVM不同(会依赖手动模板定义搜索空间),自动调度器不需要任何模板。用户只需要编写计算声明,而不需要任何调度命令或模板。自动调度器可以自动生产一个大的搜索空间,并在空间中找到一个好的调度。
本节以矩阵乘法为例
导入依赖包
import os
import numpy as np
import tvm
from tvm import te, auto_scheduler
Defining the Matrix Multiplication
首先,定义一个带有偏置的矩阵乘法。(注意:这儿使用的是TVM张量表达式中的标准操作)。主要区别在于函数定义的开头使用了register_workload装饰器。该函数应该返回一个输入/输出张量的列表。从这些张量中,自动调度器可以得到整个计算图。
@auto_scheduler.register_workload # Note the auto_scheduler decorator
def matmul_add(N, L, M, dtype):
A = te.placeholder((N, L), name="A", dtype=dtype)
B = te.placeholder((L, M), name="B", dtype=dtype)
C = te.placeholder((N, M), name="C", dtype=dtype)
k = te.reduce_axis((0, L), name="k")
matmul = te.compute(
(N, M),
lambda i, j: te.sum(A[i, k] * B[k, j], axis=k),
name="matmul",
attrs={"layout_free_placeholders": [B]}, # enable automatic layout transform for tensor B
)
out = te.compute((N, M), lambda i, j: matmul[i, j] + C[i, j], name="out")
return [A, B, C, out]
Create the search task
函数定义过后,现在可以为auto_scheduler创建一个搜索任务来进行搜索。我们指定这个矩阵乘法的特殊参数,在这个例子中,是对 大小的正方形矩阵的乘法。然后我们使用 N=L=M=1024 and dtype="float32" 创建一个搜索任务
用自定义目标提高性能
为了使 TVM 能够充分利用特定的硬件平台,你需要手动指定你的 CPU 能力。例如:
- 用
llvm -mcpu=core-avx2替换下面的llvm,以启用 AVX2 - 用
llvm -mcpu=skylake-avx512替换下面的llvm,以启用 AVX-512
target = tvm.target.Target("llvm")
N = L = M = 1024
task = tvm.auto_scheduler.SearchTask(func=matmul_add, args=(N, L, M, "float32"), target=target)
# Inspect the computational graph
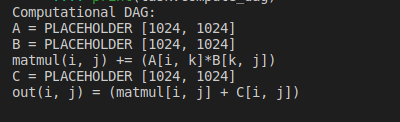
print("Computational DAG:")过一些测量试验后,我们可以从日志文件中加载最佳调度并加以应用。
print(task.compute_dag)
运行结果:
Set Parameters for Auto-Scheduler
下一步,为自动调度设置参数。
num_measure_trials是我们在搜索过程中可以使用的测量试验的数量。为了快速演示,我们在本教程中只做了 10 次试验。在实践中,1000 是一个很好的搜索收敛值。你可以根据你的时间预算做更多的试验。- 此外,我们使用
RecordToFile来 log 测量记录到matmul.json文件中。这些测量记录可以用来查询历史最好的,恢复搜索,并在以后做更多的分析。 - 查阅 TuningOptions了解参数的更多信息。
log_file = "matmul.json"
tune_option = auto_scheduler.TuningOptions(
num_measure_trials=10,
measure_callbacks=[auto_scheduler.RecordToFile(log_file)],
verbose=2,
)
Run the search
现在所有的输入都已经准备好了,可以启动搜索,让自动调度发挥下的它的魔力。经过一些测量试验后,我们可以从日志文件中加载最佳调度并加以应用。
# Run auto-tuning (search)
task.tune(tune_option)
# Apply the best schedule
sch, args = task.apply_best(log_file)
运行结果:
----------------------------------------------------------------------
------------------------------ [ Search ]
----------------------------------------------------------------------
Generate Sketches #s: 3
Sample Initial Population #s: 2015 fail_ct: 3 Time elapsed: 0.44
GA Iter: 0 Max score: 0.9999 Min score: 0.9216 #Pop: 128 #M+: 0 #M-: 0
GA Iter: 4 Max score: 0.9999 Min score: 0.9879 #Pop: 128 #M+: 1379 #M-: 67
EvolutionarySearch #s: 128 Time elapsed: 1.67
----------------------------------------------------------------------
------------------------------ [ Measure ]
----------------------------------------------------------------------
Get 10 programs to measure:
..........**********
==================================================
No: 1 GFLOPS: 216.46 / 216.46 results: MeasureResult(cost:[0.0099], error_no:0, all_cost:0.70, Tstamp:1658493558.70)
==================================================
Placeholder: A, B, C
parallel i.0@j.0@ (0,8)
matmul auto_unroll: 64
for i.1 (0,4)
for j.1 (0,32)
for k.0 (0,32)
for i.2 (0,8)
for j.2 (0,2)
for k.1 (0,32)
for i.3 (0,8)
vectorize j.3 (0,8)
matmul = ...
for i.1 (0,256)
for j.1 (0,512)
out = ...
==================================================
No: 2 GFLOPS: 122.79 / 216.46 results: MeasureResult(cost:[0.0175], error_no:0, all_cost:0.73, Tstamp:1658493559.09)
==================================================
Placeholder: A, B, C
matmul auto_unroll: 512
parallel i.0@j.0@i.1@j.1@ (0,1024)
for k.0 (0,256)
for j.2 (0,256)
for k.1 (0,4)
for i.3 (0,2)
vectorize j.3 (0,2)
matmul = ...
parallel i (0,1024)
for j (0,1024)
out = ...
==================================================
No: 3 GFLOPS: 111.42 / 216.46 results: MeasureResult(cost:[0.0193], error_no:0, all_cost:0.51, Tstamp:1658493559.38)
==================================================
Placeholder: A, B, C
parallel i.0@j.0@ (0,128)
matmul auto_unroll: 64
for j.1 (0,2)
for k.0 (0,16)
for i.2 (0,512)
for k.1 (0,64)
for i.3 (0,2)
vectorize j.3 (0,4)
matmul = ...
for i.1 (0,1024)
vectorize j.1 (0,8)
out = ...
==================================================
No: 4 GFLOPS: 34.44 / 216.46 results: MeasureResult(cost:[0.0624], error_no:0, all_cost:0.72, Tstamp:1658493559.74)
==================================================
Placeholder: A, B, C
parallel i.0@j.0@ (0,1024)
matmul auto_unroll: 64
for k.0 (0,32)
for i.2 (0,32)
for j.2 (0,2)
for k.1 (0,32)
for i.3 (0,16)
matmul = ...
for i.1 (0,512)
vectorize j.1 (0,2)
out = ...
==================================================
No: 5 GFLOPS: 22.98 / 216.46 results: MeasureResult(cost:[0.0935], error_no:0, all_cost:0.56, Tstamp:1658493560.21)
==================================================
Placeholder: A, B, C
parallel i.0@j.0@ (0,2048)
for i.1 (0,8)
for k.0 (0,1024)
for i.3 (0,64)
matmul = ...
for i.1 (0,512)
out = ...
==================================================
No: 6 GFLOPS: 11.09 / 216.46 results: MeasureResult(cost:[0.1938], error_no:0, all_cost:1.16, Tstamp:1658493561.09)
==================================================
Placeholder: A, B, C
parallel i.0@j.0@ (0,2)
matmul auto_unroll: 16
for i.1 (0,8)
for j.1 (0,256)
for k.0 (0,512)
for i.2 (0,8)
for j.2 (0,4)
for k.1 (0,2)
for i.3 (0,8)
matmul = ...
for i.1 (0,512)
for j.1 (0,1024)
out = ...
==================================================
No: 7 GFLOPS: 1.52 / 216.46 results: MeasureResult(cost:[1.4124], error_no:0, all_cost:5.96, Tstamp:1658493566.86)
==================================================
Placeholder: A, B, C
parallel i.0@j.0@ (0,2)
for i.1 (0,8)
for j.1 (0,32)
for k.0 (0,256)
for j.2 (0,32)
for k.1 (0,4)
for i.3 (0,64)
matmul = ...
for i.1 (0,512)
for j.1 (0,1024)
out = ...
==================================================
No: 8 GFLOPS: 64.39 / 216.46 results: MeasureResult(cost:[0.0334], error_no:0, all_cost:1.44, Tstamp:1658493567.09)
==================================================
Placeholder: A, B, C
parallel i.0@j.0@ (0,512)
matmul auto_unroll: 512
for i.1 (0,8)
for j.1 (0,8)
for k.0 (0,32)
for k.1 (0,32)
for i.3 (0,16)
vectorize j.3 (0,2)
matmul = ...
for i.1 (0,128)
vectorize j.1 (0,16)
out = ...
==================================================
No: 9 GFLOPS: 36.16 / 216.46 results: MeasureResult(cost:[0.0594], error_no:0, all_cost:1.23, Tstamp:1658493567.43)
==================================================
Placeholder: A, B, C
matmul auto_unroll: 64
parallel i.0@j.0@ (0,8)
for i.1 (0,4)
for j.1 (0,2)
for k.0 (0,16)
for i.2 (0,4)
for k.1 (0,64)
for i.3 (0,64)
for j.3 (0,64)
matmul = ...
parallel i (0,1024)
for j (0,1024)
out = ...
==================================================
No: 10 GFLOPS: 23.41 / 216.46 results: MeasureResult(cost:[0.0918], error_no:0, all_cost:1.98, Tstamp:1658493567.90)
==================================================
Placeholder: A, B, C
matmul auto_unroll: 512
parallel i.0@j.0@ (0,8192)
for i.1 (0,32)
for k.0 (0,16)
for i.2 (0,2)
for j.2 (0,2)
for k.1 (0,64)
matmul = ...
parallel i (0,1024)
for j (0,1024)
out = ...
Time elapsed for measurement: 12.25 s
----------------------------------------------------------------------
------------------------------ [ Done ]
----------------------------------------------------------------------
Inspecting the Optimized Schedule
我们可以 lower 调度,看看自动调度后的 IR。自动调度器正确地进行了优化,包括多级平铺(tiling)、布局转换(layout transformation)、并行化(parallelization)、矢量化(vectorization)、解卷(unrolling)和运算符融合(operator fusion)。
print("Lowered TIR:")
print(tvm.lower(sch, args, simple_mode=True))
输出结果:
Lowered TIR:
@main = primfn(A_1: handle, B_1: handle, C_1: handle, out_1: handle) -> ()
attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}
buffers = {A: Buffer(A_2: Pointer(float32), float32, [1048576], []),
B: Buffer(B_2: Pointer(float32), float32, [1048576], []),
C: Buffer(C_2: Pointer(float32), float32, [1048576], []),
out: Buffer(out_2: Pointer(float32), float32, [1048576], [])}
buffer_map = {A_1: A, B_1: B, C_1: C, out_1: out}
preflattened_buffer_map = {A_1: A_3: Buffer(A_2, float32, [1024, 1024], []), B_1: B_3: Buffer(B_2, float32, [1024, 1024], []), C_1: C_3: Buffer(C_2, float32, [1024, 1024], []), out_1: out_3: Buffer(out_2, float32, [1024, 1024], [])} {
allocate(auto_scheduler_layout_transform: Pointer(global float32), float32, [1048576]), storage_scope = global {
for (ax0.ax1.fused.ax2.fused: int32, 0, 64) "parallel" {
for (ax3: int32, 0, 32) {
for (ax4: int32, 0, 2) {
for (ax5: int32, 0, 32) {
for (ax6: int32, 0, 8) {
auto_scheduler_layout_transform_1: Buffer(auto_scheduler_layout_transform, float32, [1048576], [])[(((((ax0.ax1.fused.ax2.fused*16384) + (ax3*512)) + (ax4*256)) + (ax5*8)) + ax6)] = B[(((((ax3*32768) + (ax5*1024)) + (ax0.ax1.fused.ax2.fused*16)) + (ax4*8)) + ax6)]
}
}
}
}
}
for (i.outer.j.outer.fused: int32, 0, 8) "parallel" {
allocate(matmul: Pointer(global float32), float32, [131072]), storage_scope = global {
for (i.outer.outer.inner: int32, 0, 4) {
for (j.outer.outer.inner: int32, 0, 32) {
for (i.outer.inner.init: int32, 0, 8) {
let cse_var_1: int32 = (((i.outer.outer.inner*32768) + (i.outer.inner.init*4096)) + (j.outer.outer.inner*16))
{
matmul_1: Buffer(matmul, float32, [131072], [])[ramp(cse_var_1, 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 512), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 1024), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 1536), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 2048), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 2560), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 3072), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 3584), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 8), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 520), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 1032), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 1544), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 2056), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 2568), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 3080), 1, 8)] = broadcast(0f32, 8)
matmul_1[ramp((cse_var_1 + 3592), 1, 8)] = broadcast(0f32, 8)
}
}
for (k.outer: int32, 0, 32) {
for (i.outer.inner: int32, 0, 8) {
for (j.outer.inner: int32, 0, 2) {
for (k.inner: int32, 0, 32) {
let cse_var_11: int32 = ((((i.outer.outer.inner*32768) + (i.outer.inner*4096)) + (j.outer.outer.inner*16)) + (j.outer.inner*8))
let cse_var_10: int32 = (cse_var_11 + 512)
let cse_var_9: int32 = (cse_var_11 + 3584)
let cse_var_8: int32 = (cse_var_11 + 3072)
let cse_var_7: int32 = (cse_var_11 + 2560)
let cse_var_6: int32 = (cse_var_11 + 2048)
let cse_var_5: int32 = (cse_var_11 + 1536)
let cse_var_4: int32 = (cse_var_11 + 1024)
let cse_var_3: int32 = (((((floordiv(i.outer.j.outer.fused, 2)*262144) + (i.outer.outer.inner*65536)) + (i.outer.inner*8192)) + (k.outer*32)) + k.inner)
let cse_var_2: int32 = (((((floormod(i.outer.j.outer.fused, 2)*524288) + (j.outer.outer.inner*16384)) + (k.outer*512)) + (j.outer.inner*256)) + (k.inner*8))
{
matmul_1[ramp(cse_var_11, 1, 8)] = (matmul_1[ramp(cse_var_11, 1, 8)] + (broadcast(A[cse_var_3], 8)*auto_scheduler_layout_transform_1[ramp(cse_var_2, 1, 8)]))
matmul_1[ramp(cse_var_10, 1, 8)] = (matmul_1[ramp(cse_var_10, 1, 8)] + (broadcast(A[(cse_var_3 + 1024)], 8)*auto_scheduler_layout_transform_1[ramp(cse_var_2, 1, 8)]))
matmul_1[ramp(cse_var_4, 1, 8)] = (matmul_1[ramp(cse_var_4, 1, 8)] + (broadcast(A[(cse_var_3 + 2048)], 8)*auto_scheduler_layout_transform_1[ramp(cse_var_2, 1, 8)]))
matmul_1[ramp(cse_var_5, 1, 8)] = (matmul_1[ramp(cse_var_5, 1, 8)] + (broadcast(A[(cse_var_3 + 3072)], 8)*auto_scheduler_layout_transform_1[ramp(cse_var_2, 1, 8)]))
matmul_1[ramp(cse_var_6, 1, 8)] = (matmul_1[ramp(cse_var_6, 1, 8)] + (broadcast(A[(cse_var_3 + 4096)], 8)*auto_scheduler_layout_transform_1[ramp(cse_var_2, 1, 8)]))
matmul_1[ramp(cse_var_7, 1, 8)] = (matmul_1[ramp(cse_var_7, 1, 8)] + (broadcast(A[(cse_var_3 + 5120)], 8)*auto_scheduler_layout_transform_1[ramp(cse_var_2, 1, 8)]))
matmul_1[ramp(cse_var_8, 1, 8)] = (matmul_1[ramp(cse_var_8, 1, 8)] + (broadcast(A[(cse_var_3 + 6144)], 8)*auto_scheduler_layout_transform_1[ramp(cse_var_2, 1, 8)]))
matmul_1[ramp(cse_var_9, 1, 8)] = (matmul_1[ramp(cse_var_9, 1, 8)] + (broadcast(A[(cse_var_3 + 7168)], 8)*auto_scheduler_layout_transform_1[ramp(cse_var_2, 1, 8)]))
}
}
}
}
}
}
}
for (i.inner: int32, 0, 256) {
for (j.inner: int32, 0, 512) {
let cse_var_12: int32 = ((((floordiv(i.outer.j.outer.fused, 2)*262144) + (i.inner*1024)) + (floormod(i.outer.j.outer.fused, 2)*512)) + j.inner)
out[cse_var_12] = (matmul_1[((i.inner*512) + j.inner)] + C[cse_var_12])
}
}
}
}
}
}
Check correctness and evaluate performance
建立二进制文件,并检查其正确性(correctness)和性能(performance)
func = tvm.build(sch, args, target)
a_np = np.random.uniform(size=(N, L)).astype(np.float32)
b_np = np.random.uniform(size=(L, M)).astype(np.float32)
c_np = np.random.uniform(size=(N, M)).astype(np.float32)
out_np = a_np.dot(b_np) + c_np
dev = tvm.cpu()
a_tvm = tvm.nd.array(a_np, device=dev)
b_tvm = tvm.nd.array(b_np, device=dev)
c_tvm = tvm.nd.array(c_np, device=dev)
out_tvm = tvm.nd.empty(out_np.shape, device=dev)
func(a_tvm, b_tvm, c_tvm, out_tvm)
# Check results
np.testing.assert_allclose(out_np, out_tvm.numpy(), rtol=1e-3)
# Evaluate execution time.
evaluator = func.time_evaluator(func.entry_name, dev, min_repeat_ms=500)
print(
"Execution time of this operator: %.3f ms"
% (np.median(evaluator(a_tvm, b_tvm, c_tvm, out_tvm).results) * 1000)
)
运行结果:
Execution time of this operator: 10.171 ms
Using the record file
在搜索过程中,所有的测量记录都被 log 到记录文件 matmul.json。这些测量记录可以用来重新应用搜索结果,恢复搜索,并进行其他分析。
这里有一个例子,我们从一个文件中加载最佳调度,并打印出等效的 python 调度 API。这可以用于调试和学习自动调度的行为。
print("Equivalent python schedule:")
print(task.print_best(log_file))
输出结果:
Equivalent python schedule:
matmul_i, matmul_j, matmul_k = tuple(matmul.op.axis) + tuple(matmul.op.reduce_axis)
out_i, out_j = tuple(out.op.axis) + tuple(out.op.reduce_axis)
matmul_i_o_i, matmul_i_i = s[matmul].split(matmul_i, factor=8)
matmul_i_o_o_i, matmul_i_o_i = s[matmul].split(matmul_i_o_i, factor=8)
matmul_i_o_o_o, matmul_i_o_o_i = s[matmul].split(matmul_i_o_o_i, factor=4)
matmul_j_o_i, matmul_j_i = s[matmul].split(matmul_j, factor=8)
matmul_j_o_o_i, matmul_j_o_i = s[matmul].split(matmul_j_o_i, factor=2)
matmul_j_o_o_o, matmul_j_o_o_i = s[matmul].split(matmul_j_o_o_i, factor=32)
matmul_k_o, matmul_k_i = s[matmul].split(matmul_k, factor=32)
s[matmul].reorder(matmul_i_o_o_o, matmul_j_o_o_o, matmul_i_o_o_i, matmul_j_o_o_i, matmul_k_o, matmul_i_o_i, matmul_j_o_i, matmul_k_i, matmul_i_i, matmul_j_i)
out_i_o, out_i_i = s[out].split(out_i, factor=256)
out_j_o, out_j_i = s[out].split(out_j, factor=512)
s[out].reorder(out_i_o, out_j_o, out_i_i, out_j_i)
s[matmul].compute_at(s[out], out_j_o)
out_i_o_j_o_fused = s[out].fuse(out_i_o, out_j_o)
s[out].parallel(out_i_o_j_o_fused)
s[matmul].pragma(matmul_i_o_o_o, "auto_unroll_max_step", 64)
s[matmul].pragma(matmul_i_o_o_o, "unroll_explicit", True)
s[matmul].vectorize(matmul_j_i)
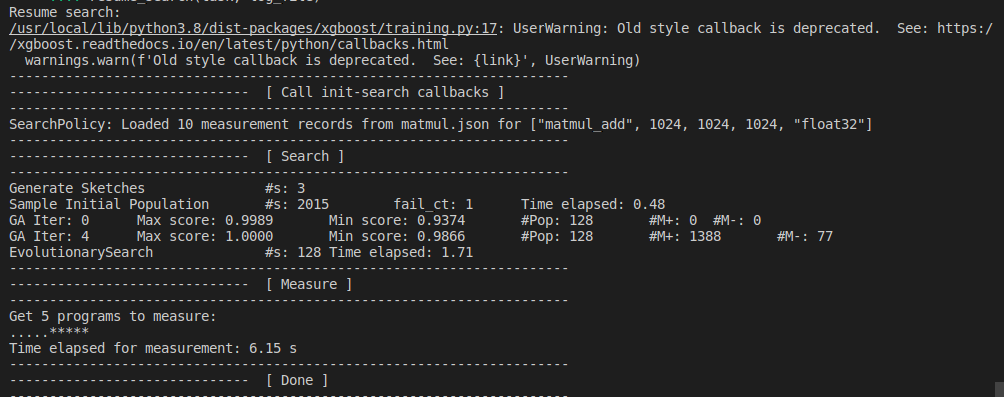
一个更复杂的例子是恢复搜索。在这种情况下,我们需要自己创建搜索策略和成本模型,并通过日志文件恢复搜索策略和成本模型(cost model)的状态。在下面的例子中,我们恢复了状态并做了更多的 5 次试验。
def resume_search(task, log_file):
print("Resume search:")
cost_model = auto_scheduler.XGBModel()
cost_model.update_from_file(log_file)
search_policy = auto_scheduler.SketchPolicy(
task, cost_model, init_search_callbacks=[auto_scheduler.PreloadMeasuredStates(log_file)]
)
tune_option = auto_scheduler.TuningOptions(
num_measure_trials=5, measure_callbacks=[auto_scheduler.RecordToFile(log_file)]
)
task.tune(tune_option, search_policy=search_policy)
resume_search(task, log_file)
输出结果如下:
TVM:使用自动调度优化算子的更多相关文章
- TVM自动调度器
TVM自动调度器 随着模型大小,算子多样性和硬件异构性的不断增长,优化深度神经网络的执行速度非常困难.从计算的角度来看,深度神经网络只是张量计算的一层又一层.这些张量计算(例如matmul和conv2 ...
- GPU自动调度卷积层
GPU自动调度卷积层 本文对GPU使用自动调度程序. 与依靠手动模板定义搜索空间的基于模板的autotvm不同,自动调度程序不需要任何模板.用户只需要编写计算声明,无需任何调度命令或模板.自动调度程序 ...
- 自动调度GPU的卷积层
自动调度GPU的卷积层 这是有关如何对GPU使用自动调度程序的文档. 与依靠手动模板定义搜索空间的基于模板的autotvm不同,自动调度程序不需要任何模板.用户只需要编写计算声明,而无需任何调度命令或 ...
- ARM CPU自动调度神经网络
ARM CPU自动调度神经网络 对特定设备和工作负载进行自动调度,对于获得最佳性能至关重要.通过RPC使用自动调度器为ARM CPU调度整个神经网络. 为了自动调度神经网络,将网络划分为小的子图,进行 ...
- NVIDIA GPU自动调度神经网络
NVIDIA GPU自动调度神经网络 对特定设备和工作负载进行自动调整对于获得最佳性能至关重要.这是有关如何使用自动调度器为NVIDIA GPU调整整个神经网络. 为了自动调整神经网络,将网络划分为小 ...
- CPU的自动调度矩阵乘法
CPU的自动调度矩阵乘法 这是一个有关如何对CPU使用自动调度程序的文档. 与依靠手动模板定义搜索空间的基于模板的autotvm不同,自动调度程序不需要任何模板.用户只需要编写计算声明,而无需任何调度 ...
- 为x86 CPU自动调度神经网络
为x86 CPU自动调度神经网络 对特定设备和工作负载进行自动调试对于获得最佳性能至关重要.这是有关如何使用自动调度器为x86 CPU调试整个神经网络的文档. 为了自动调试神经网络,将网络划分为小的子 ...
- NVIDIA GPU的神经网络自动调度
NVIDIA GPU的神经网络自动调度 针对特定设备和工作负载的自动调整对于获得最佳性能至关重要.这是一个关于如何使用自动调度器为NVIDIA GPU调整整个神经网络的资料. 为了自动调整一个神经网络 ...
- SystemML大规模机器学习,优化算子融合方案的研究
SystemML大规模机器学习,优化算子融合方案的研究 摘要 许多大规模机器学习(ML)系统允许通过线性代数程序指定定制的ML算法,然后自动生成有效的执行计划.在这种情况下,优化的机会融合基本算子的熔 ...
- Oracle12c中SQL性能优化(SQL TUNING)新特性之自动重优化(automatic reoptimization)
Oracle12c中的自动重优化 Oracle12c中的自适应查询优化有一系列不同特点组成.像自适应计划(AdaptivePlans)功能可以在运行时修改执行计划,但并不允许计划中连接顺序的改变.自动 ...
随机推荐
- 使用VS Code开发微信小程序
.MathJax, .MathJax_Message, .MathJax_Preview { display: none } 使用VS Code开发微信小程序 微信开发工具 结构 缺点 VS Code ...
- 不到24小时,AOne让全员用上DeepSeek的秘诀是……
DeepSeek引发新一轮AI浪潮,面对企业数字化智能升级与数据安全红线的急迫需求,IT负责人的压力山大!如何在24小时内实现全员AI落地,同时为后续安全部署铺平道路? Step1:一键开启全员智能时 ...
- 软件工程: SDLC V模型
V型 V-model 代表一个开发过程,可以被认为是瀑布模型的扩展,是更通用的 V-model 的一个例子.不是以线性方式向下移动,而是在编码阶段之后向上弯曲工艺步骤,以形成典型的 V 形.V 模型展 ...
- Typecho 如何开启外链转内链
把博客中的外部链接转换为网站内链,据说有利于搜索引擎收录.该插件主要由 benzBrake 大佬 编写,同时支持转换文章和评论中的链接. 上传插件 下载 Master Branch Code 后上传到 ...
- windows设置定时任务
- DeepSeek 开源周回顾「GitHub 热点速览」
上周,DeepSeek 发布的开源项目用一个词形容就是:榨干性能!由于篇幅有限,这里仅列出项目名称和简介,感兴趣的同学可以前往 DeepSeek 的开源组织页面,深入探索每个项目的精彩之处! 第一天 ...
- Git pull(拉取),push(上传)命令整理(详细)
转自:https://www.cnblogs.com/wbl001/p/11495110.html (文档较长,请大家耐心阅读,很有帮助) git比较本地仓库和远程仓库的差异 更新本地的远程分支 gi ...
- python 二级 函数与代码复用
- 启动本地node服务器报错: Access denied for user ‘root‘@‘localhost‘ (using password: YES)
背景:今天启动node服务时直接报错,顿时一激灵,之前(几个月前哈哈)明明好好的.主要问题就是在连接数据库上,我登上mysql瞅瞅有没有问题,当要输入密码时,emmm, 很好, 忘记root密码了,于 ...
- docker pause 命令使用
暂停正在运行的镜像容器 用途是在启动的容器的过程又的容器启动快了 有的还没有就绪 调试过程使用 a3: 正在运行的镜像容器简称 暂停: docker pause a3 解除暂停: docker unp ...