字节大模型应用开发框架 Eino 全解(一)|结合 RAG 知识库案例分析框架生态
前言
大家好,这里是白泽,Eino 是字节开源的 Golang 大模型应用开发框架,诸如豆包、扣子等 Agent 应用或工作流都是借助这个框架进行开发。
我将通过《字节大模型应用开发框架 Eino 全解》系列,从框架结构、组件生态、以及项目案例、mcp集成等维度,带你全方面掌握 Golang 大模型应用开发。
本章介绍
- Eino 框架生态介绍,以及相关仓库地址。
- 借助白泽上一期开源的 Eino 编写的 基于 Redis 文档向量检索系统,梳理 Eino 框架的各个组件模块,以及交互、编排方式。
Eino 框架生态
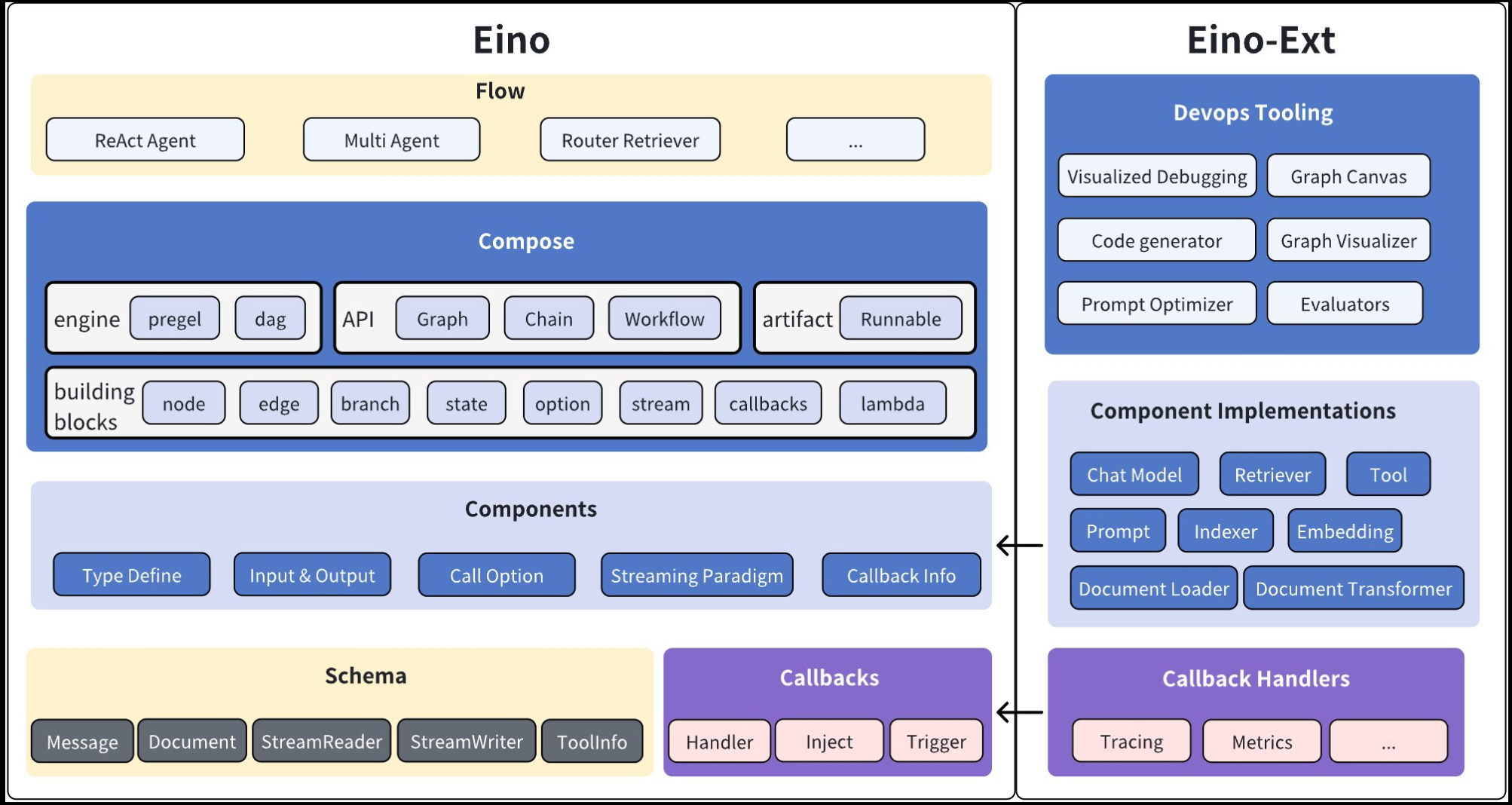
- Eino(主代码仓库):包含类型定义、流处理机制、组件抽象、编排功能、切面机制等。
- EinoExt:组件实现、回调处理程序实现、组件使用示例,以及各种工具,如评估器、提示优化器等。
- Eino Devops:可视化开发、可视化调试等。
- EinoExamples:是包含示例应用程序和最佳实践的代码仓库。
- Eino 用户手册:快速理解 Eino 中的概念,掌握基于 Eino 开发设计 AI 应用的技能。(Eino 开源不满一年,文档仍在完善)
Redis 文档向量检索系统(RAG)
接下来将通过这个案例,介绍一下 Eino 框架的各个组件,以及如何使用组件进行编排构建 Agent,同时带你熟悉一下 Eino 本身的代码结构。
项目地址:https://github.com/BaiZe1998/go-learning/tree/main/eino_assistant
项目架构图:
subgraph 索引构建阶段
MD[Markdown文件] --> FL[文件加载器]
FL --> SP[文档分割器]
SP --> EM1[嵌入模型]
EM1 --> VEC1[文档向量]
VEC1 --> RDB[(Redis向量数据库)]
end
subgraph 查询检索阶段
Q[用户问题] --> EM2[嵌入模型]
EM2 --> VEC2[查询向量]
VEC2 --> KNN{KNN向量搜索}
RDB --> KNN
KNN --> TOP[TopK相关文档]
end
subgraph 回答生成阶段
TOP --> PC[提示构建]
Q --> PC
PC --> PROMPT[增强提示]
PROMPT --> LLM[大语言模型]
LLM --> ANS[生成回答]
end
subgraph 系统架构
direction LR
RET[检索器\nRetriever] --> RAG_SYS[RAG系统]
GEN[生成器\nGenerator] --> RAG_SYS
OPT[参数配置\ntopK等] --> RAG_SYS
end
Q --> RAG_SYS
RAG_SYS --> ANS
classDef phase fill:#f9f,stroke:#333,stroke-width:2px;
class 索引构建阶段,查询检索阶段,回答生成阶段 phase;
整个项目包含三个阶段,索引构建、检查索引、回答生成、接下来以索引构建阶段为例,介绍一下用上了 Eino 哪些组件,以及组件之间的关系,完整的项目讲解可以看往期的文章。
整个过程中我们的项目中会同时引入 Eino库 和 Eino-Ext 库的内容,希望你能体会 Eino 生态将稳定的类型定义、组件抽象、编排逻辑放置在 Eino 主库中,而将可扩展的组件、工具实现拆分到 Eino-Ext 库中的好处。
一、组件初始化
Eino 组件大全
- tool: 对接外部工具,提供了常用工具集。
- chatmodel:对接各家大模型的调用接口。
- callbacks:一些工具的 hook 能力的实现。
- chattemplate:提示词工程相关,处理和格式化提示模板的组件。
- indexer:Indexer 为把文本进行索引存储,一般使用 Embedding 做语义化索引,也可做分词索引等,以便于 Retriever 中召回使用。
- retriver:Retriever 用于把 Indexer 构建索引之后的内容进行召回,在 AI 应用中,一般使用 Embedding 进行语义相似性召回。
- document:对接各家的文档切分和过滤。
- embeding:对接各家文档向量化模型。
索引构建本质上也是一个局部完整的工作流,可以借助编辑器插件 Eino Dev 完成可视化的编辑工作流,在可视化的编辑窗口,编排工作流。
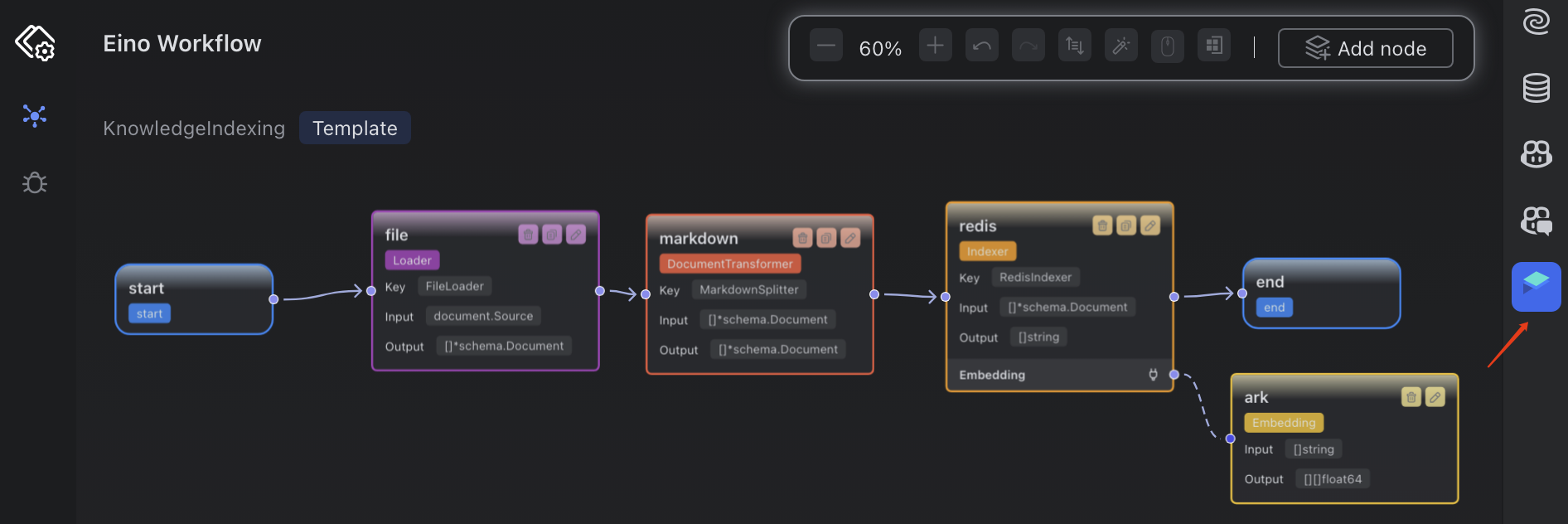
点击 generate 直接生成如下5个文件,然后手动替换内部的业务逻辑。
Eino Dev 插件的使用将在组件讲解篇完成后,单出一期讲解。
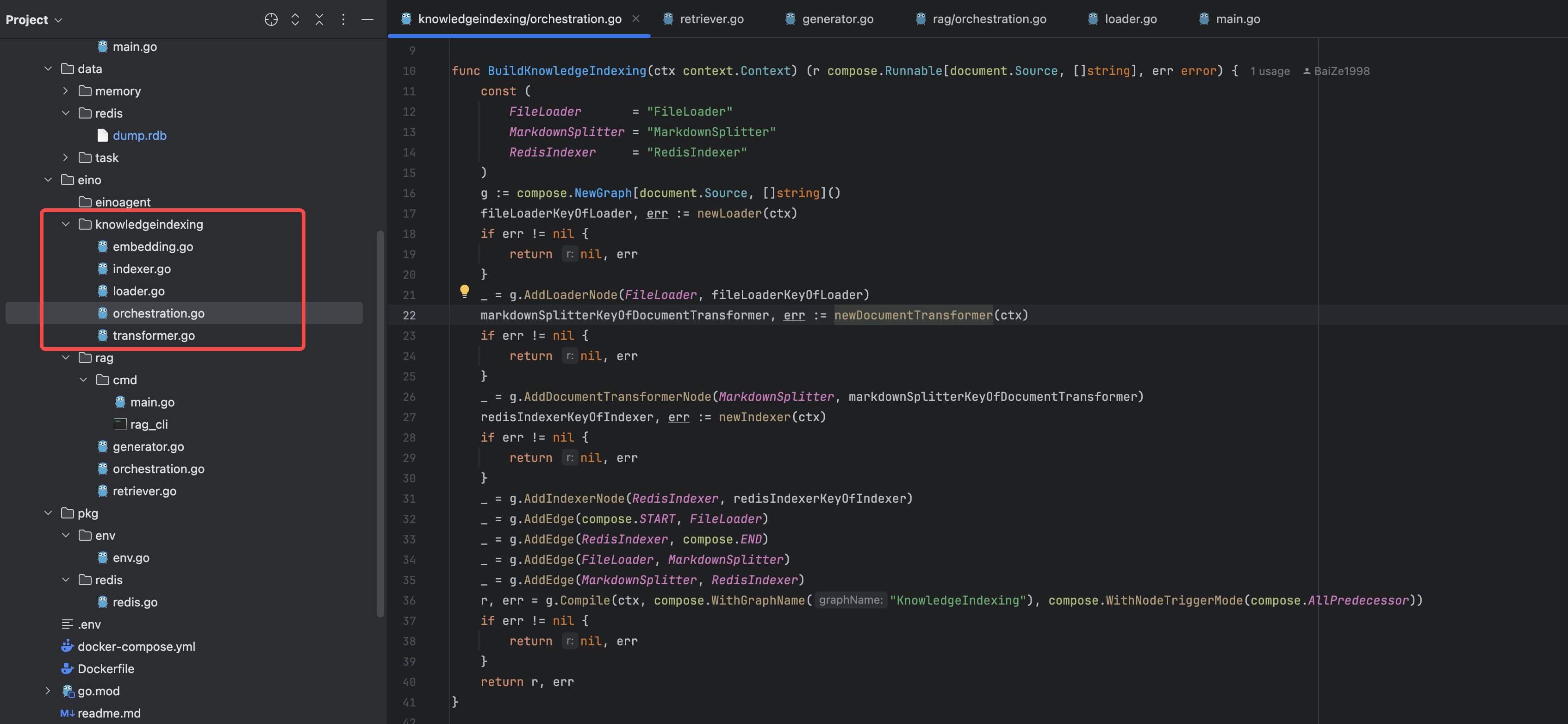
接下来我们看一下五个文件的内容,特别是关注 import 的库的来源。
- loader.go 创建文件加载组件
package knowledgeindexing
import (
"context"
"github.com/cloudwego/eino-ext/components/document/loader/file"
"github.com/cloudwego/eino/components/document"
)
// newLoader component initialization function of node 'FileLoader' in graph 'KnowledgeIndexing'
func newLoader(ctx context.Context) (ldr document.Loader, err error) {
// TODO Modify component configuration here.
config := &file.FileLoaderConfig{}
ldr, err = file.NewFileLoader(ctx, config)
if err != nil {
return nil, err
}
return ldr, nil
}
document.Loader:
返回值类型是一个接口,定义在 Eino 主库的 components/document 目录下。
type Loader interface {
Load(ctx context.Context, src Source, opts ...LoaderOption) ([]*schema.Document, error)
}
file.NewFileLoader:
返回一个具体的文件加载的实现,定义在 Eino-Ext 库的 components/document 目录下,是对应关系。
unc NewFileLoader(ctx context.Context, config *FileLoaderConfig) (*FileLoader, error) {
if config == nil {
config = &FileLoaderConfig{}
}
if config.Parser == nil {
parser, err := parser.NewExtParser(ctx,
&parser.ExtParserConfig{
FallbackParser: parser.TextParser{},
},
)
if err != nil {
return nil, fmt.Errorf("new file parser fail: %w", err)
}
config.Parser = parser
}
return &FileLoader{FileLoaderConfig: *config}, nil
}
- transformer.go 创建 markdown 文件分割组件
import (
"context"
"github.com/cloudwego/eino-ext/components/document/transformer/splitter/markdown"
"github.com/cloudwego/eino/components/document"
)
// newDocumentTransformer component initialization function of node 'MarkdownSplitter' in graph 'KnowledgeIndexing'
func newDocumentTransformer(ctx context.Context) (tfr document.Transformer, err error) {
// TODO Modify component configuration here.
config := &markdown.HeaderConfig{
Headers: map[string]string{
"#": "title",
},
TrimHeaders: false}
tfr, err = markdown.NewHeaderSplitter(ctx, config)
if err != nil {
return nil, err
}
return tfr, nil
}
document.Transformer:
返回值类型是一个接口,定义在 Eino 主库的 components/document 目录下,定义文档的过滤和分割。
// Transformer is to convert documents, such as split or filter.
type Transformer interface {
Transform(ctx context.Context, src []*schema.Document, opts ...TransformerOption) ([]*schema.Document, error)
}
markdown.NewHeaderSplitter:
创建一个基于 # 标签进行分割的 markdown 组件,定义在 Eino-Ext 扩展库的 components/document/transformer/splitter/markdown 目录下。
func NewHeaderSplitter(ctx context.Context, config *HeaderConfig) (document.Transformer, error) {
if len(config.Headers) == 0 {
return nil, fmt.Errorf("no headers specified")
}
for k := range config.Headers {
for _, c := range k {
if c != '#' {
return nil, fmt.Errorf("header can only consist of '#': %s", k)
}
}
}
return &headerSplitter{
headers: config.Headers,
trimHeaders: config.TrimHeaders,
}, nil
}
到这一步你应该有了大致的感受,Eino 和 Eino-Ext 是相辅相成的。
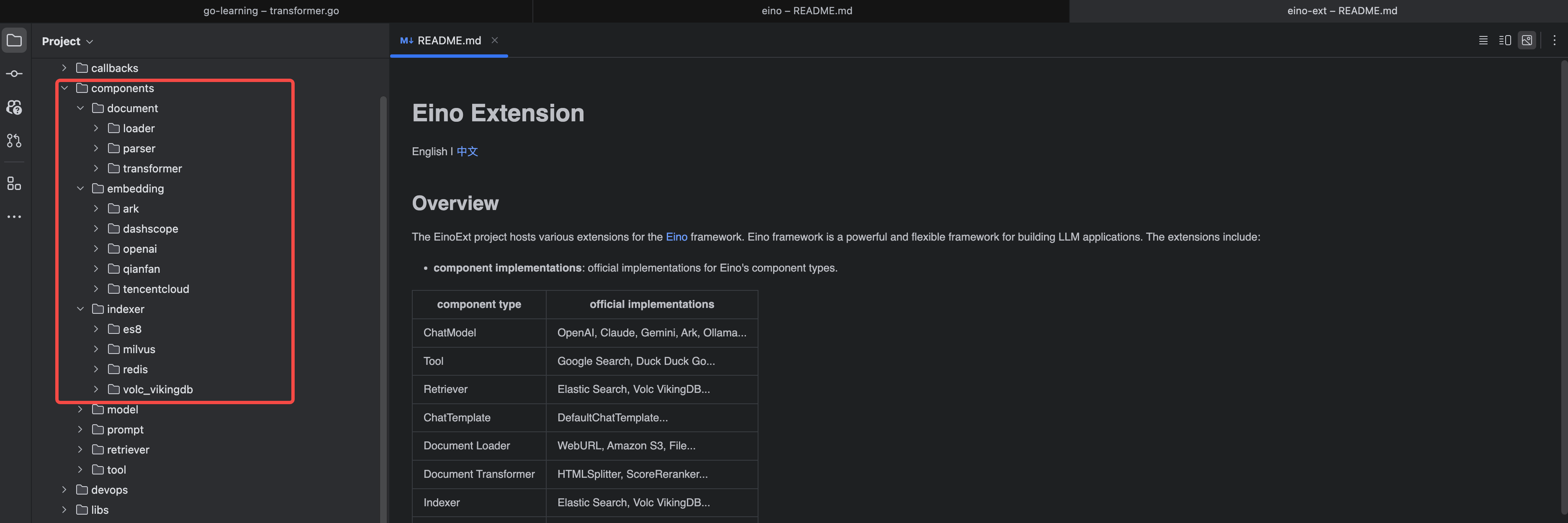
看一下 Eino 库的组件目录结构。

看一下 Eino-Ext 的组件目录结构。
- embedding.go
文档向量化,需要在初始化的时候,指定一个向量化的模型,用于将文档数据向量化之后,存入 Redis 向量索引中(也可以使用其他向量数据库),这里使用了字节的 doubao-embedding-large-text-240915 模型。
package knowledgeindexing
import (
"context"
"os"
"github.com/cloudwego/eino-ext/components/embedding/ark"
"github.com/cloudwego/eino/components/embedding"
)
func newEmbedding(ctx context.Context) (eb embedding.Embedder, err error) {
// TODO Modify component configuration here.
config := &ark.EmbeddingConfig{
BaseURL: "https://ark.cn-beijing.volces.com/api/v3",
APIKey: os.Getenv("ARK_API_KEY"),
Model: os.Getenv("ARK_EMBEDDING_MODEL"),
}
eb, err = ark.NewEmbedder(ctx, config)
if err != nil {
return nil, err
}
return eb, nil
}
- indexer.go(这一步需要你本地通过启动一个 redis)
Redis向量索引(通过RediSearch模块实现)是一种高性能的向量数据库功能,它允许:
向量存储: 在Redis中存储高维向量数据
语义搜索: 基于向量相似度进行搜索(而非简单的关键词匹配)
KNN查询: 使用K-Nearest Neighbors算法找到最接近的向量
Redis向量索引的核心概念:
哈希结构: 使用Redis Hash存储文档内容、元数据和向量
向量字段: 特殊字段类型,支持高效的向量操作
相似度计算: 支持多种距离度量方式(如余弦相似度、欧氏距离)
import (
"context"
"encoding/json"
"fmt"
"log"
"os"
"github.com/cloudwego/eino-ext/components/indexer/redis"
"github.com/cloudwego/eino/components/indexer"
"github.com/cloudwego/eino/schema"
"github.com/google/uuid"
redisCli "github.com/redis/go-redis/v9"
redispkg "eino_assistant/pkg/redis"
)
func init() {
// 初始化索引
err := redispkg.Init()
if err != nil {
log.Fatalf("failed to init redis index: %v", err)
}
}
// newIndexer component initialization function of node 'RedisIndexer' in graph 'KnowledgeIndexing'
func newIndexer(ctx context.Context) (idr indexer.Indexer, err error) {
// TODO Modify component configuration here.
redisAddr := os.Getenv("REDIS_ADDR")
redisClient := redisCli.NewClient(&redisCli.Options{
Addr: redisAddr,
Protocol: 2,
})
// 文档向量转换配置
config := &redis.IndexerConfig{
Client: redisClient,
KeyPrefix: redispkg.RedisPrefix,
BatchSize: 1,
// 文档到 hash 的逻辑转换
DocumentToHashes: func(ctx context.Context, doc *schema.Document) (*redis.Hashes, error) {
if doc.ID == "" {
doc.ID = uuid.New().String()
}
key := doc.ID
metadataBytes, err := json.Marshal(doc.MetaData)
if err != nil {
return nil, fmt.Errorf("failed to marshal metadata: %w", err)
}
return &redis.Hashes{
Key: key,
Field2Value: map[string]redis.FieldValue{
redispkg.ContentField: {Value: doc.Content, EmbedKey: redispkg.VectorField},
redispkg.MetadataField: {Value: metadataBytes},
},
}, nil
},
}
// 配置 doubao 嵌入模型(文档向量化)
embeddingIns11, err := newEmbedding(ctx)
if err != nil {
return nil, err
}
config.Embedding = embeddingIns11
idr, err = redis.NewIndexer(ctx, config)
if err != nil {
return nil, err
}
return idr, nil
}
二、组件编排
orchestration.go
文档索引构建阶段,上文的代码文件连同 orchestration.go 都是通过插件生成的,编排完 ui 工作流,就会为你生成组件之间的流式代码。
import (
"context"
"github.com/cloudwego/eino/components/document"
"github.com/cloudwego/eino/compose"
)
func BuildKnowledgeIndexing(ctx context.Context) (r compose.Runnable[document.Source, []string], err error) {
const (
FileLoader = "FileLoader"
MarkdownSplitter = "MarkdownSplitter"
RedisIndexer = "RedisIndexer"
)
g := compose.NewGraph[document.Source, []string]()
fileLoaderKeyOfLoader, err := newLoader(ctx)
if err != nil {
return nil, err
}
_ = g.AddLoaderNode(FileLoader, fileLoaderKeyOfLoader)
markdownSplitterKeyOfDocumentTransformer, err := newDocumentTransformer(ctx)
if err != nil {
return nil, err
}
_ = g.AddDocumentTransformerNode(MarkdownSplitter, markdownSplitterKeyOfDocumentTransformer)
redisIndexerKeyOfIndexer, err := newIndexer(ctx)
if err != nil {
return nil, err
}
// 编排的核心:通过点和边的概念,顺序处理数据
_ = g.AddIndexerNode(RedisIndexer, redisIndexerKeyOfIndexer)
_ = g.AddEdge(compose.START, FileLoader)
_ = g.AddEdge(RedisIndexer, compose.END)
_ = g.AddEdge(FileLoader, MarkdownSplitter)
_ = g.AddEdge(MarkdownSplitter, RedisIndexer)
r, err = g.Compile(ctx, compose.WithGraphName("KnowledgeIndexing"), compose.WithNodeTriggerMode(compose.AllPredecessor))
if err != nil {
return nil, err
}
return r, err
}
通过 import 的库可以看到,编排的流程抽象和数据传输类型,都是定义在 Eino 主库当中的,这里使用了范型来动态定义输入和输出类型,此外 Eino 允许上下游之间通过流式或者非流失的形式交换数据,这都是框架的能力。
// Runnable is the interface for an executable object. Graph, Chain can be compiled into Runnable.
// runnable is the core conception of eino, we do downgrade compatibility for four data flow patterns,
// and can automatically connect components that only implement one or more methods.
// eg, if a component only implements Stream() method, you can still call Invoke() to convert stream output to invoke output.
type Runnable[I, O any] interface {
Invoke(ctx context.Context, input I, opts ...Option) (output O, err error)
Stream(ctx context.Context, input I, opts ...Option) (output *schema.StreamReader[O], err error)
Collect(ctx context.Context, input *schema.StreamReader[I], opts ...Option) (output O, err error)
Transform(ctx context.Context, input *schema.StreamReader[I], opts ...Option) (output *schema.StreamReader[O], err error)
}
Eino 提供了两组用于编排的 API:
| API | 特性和使用场景 |
|---|---|
| Chain | 简单的链式有向图,只能向前推进。 |
| Graph | 循环或非循环有向图。功能强大且灵活。 |
我们来创建一个简单的 chain: 一个模版(ChatTemplate)接一个大模型(ChatModel)。

chain, _ := NewChain[map[string]any, *Message]().
AppendChatTemplate(prompt).
AppendChatModel(model).
Compile(ctx)
chain.Invoke(ctx, map[string]any{"query": "what's your name?"})
现在,我们来创建一个 Graph,先用一个 ChatModel 生成回复或者 Tool 调用指令,如生成了 Tool 调用指令,就用一个 ToolsNode 执行这些 Tool。
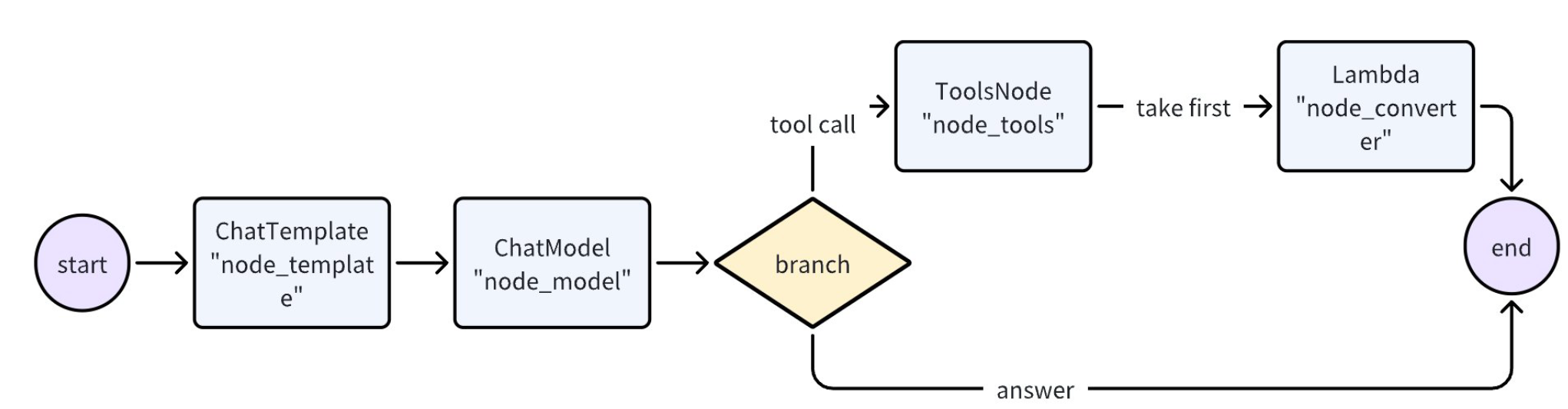
graph := NewGraph[map[string]any, *schema.Message]()
_ = graph.AddChatTemplateNode("node_template", chatTpl)
_ = graph.AddChatModelNode("node_model", chatModel)
_ = graph.AddToolsNode("node_tools", toolsNode)
_ = graph.AddLambdaNode("node_converter", takeOne)
_ = graph.AddEdge(START, "node_template")
_ = graph.AddEdge("node_template", "node_model")
_ = graph.AddBranch("node_model", branch)
_ = graph.AddEdge("node_tools", "node_converter")
_ = graph.AddEdge("node_converter", END)
compiledGraph, err := graph.Compile(ctx)
if err != nil {
return err
}
out, err := r.Invoke(ctx, map[string]any{"query":"Beijing's weather this weekend"})
小节
下一章讲解如何通过 Eino 集成 MCP,敬请期待。
公众号【白泽talk】,Golang|AI 大模型应用开发相关知识星球:白泽说 ,添加: baize_talk02 咨询加入~
字节大模型应用开发框架 Eino 全解(一)|结合 RAG 知识库案例分析框架生态的更多相关文章
- 九度oj题目&吉大考研11年机试题全解
九度oj题目(吉大考研11年机试题全解) 吉大考研机试2011年题目: 题目一(jobdu1105:字符串的反码). http://ac.jobdu.com/problem.php?pid=11 ...
- MySQL复制异常大扫盲:快速溯源与排查错误全解
MySQL复制异常大扫盲:快速溯源与排查错误全解https://mp.weixin.qq.com/s/0Ic8BnUokyOj7m1YOrk1tA 作者介绍王松磊,现任职于UCloud,从事MySQL ...
- Mybatis系列全解(八):Mybatis的9大动态SQL标签你知道几个?提前致女神!
封面:洛小汐 作者:潘潘 2021年,仰望天空,脚踏实地. 这算是春节后首篇 Mybatis 文了~ 跨了个年感觉写了有半个世纪 ... 借着女神节 ヾ(◍°∇°◍)ノ゙ 提前祝男神女神们越靓越富越嗨 ...
- Java IO编程全解(三)——伪异步IO编程
转载请注明出处:http://www.cnblogs.com/Joanna-Yan/p/7723174.html 前面讲到:Java IO编程全解(二)--传统的BIO编程 为了解决同步阻塞I/O面临 ...
- Java IO编程全解(四)——NIO编程
转载请注明出处:http://www.cnblogs.com/Joanna-Yan/p/7793964.html 前面讲到:Java IO编程全解(三)——伪异步IO编程 NIO,即New I/O,这 ...
- TCP协议要点和难点全解
转载自http://www.cnblogs.com/leetieniu2014/p/5771324.html TCP协议要点和难点全解 说明: 1).本文以TCP的发展历程解析容易引起混淆,误会的方方 ...
- RAID技术全解图解-RAID0、RAID1、RAID5、RAID100【转】
图文并茂 RAID 技术全解 – RAID0.RAID1.RAID5.RAID100…… RAID 技术相信大家都有接触过,尤其是服务器运维人员,RAID 概念很多,有时候会概念混淆.这篇文章为网络转 ...
- RAID 技术全解
图文并茂 RAID 技术全解 – RAID0.RAID1.RAID5.RAID100-- RAID 技术相信大家都有接触过,尤其是服务器运维人员,RAID 概念很多,有时候会概念混淆.这篇文章为网络转 ...
- redis全解
Redis全解 1.什么是Redis? Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到 ...
- Java IO编程全解(六)——4种I/O的对比与选型
转载请注明出处:http://www.cnblogs.com/Joanna-Yan/p/7804185.html 前面讲到:Java IO编程全解(五)--AIO编程 为了防止由于对一些技术概念和术语 ...
随机推荐
- 福尼斯焊机TPS320i/TPS400i/TPS500i的焊接特性
福尼斯焊机设备原理 TPS320i.TPS400i.TPS500i和TPS 600iMIG/MAG电源由微处理器控制,机器人驱动器维修,是完全数字化的逆变器电源. 模块化设计和系统的扩展潜力使其具有高 ...
- Math.atan2求角度解析
我们求角度的时候, 第一反应应该是Math.tan(x/y)就得到角度了 但是这样求的是和y轴的夹角,如果以y轴正方向为0度,顺时针为正,则第三象限和第一象限的tan值一致,需要判断x,y和0的关系, ...
- 项目愿景 (Product Vision)、产品目标 (Product Goal) 、Sprint目标 (Sprint Goal) 及 示例
愿景(Vision) 是制定业务目标(Business Goal)的基础,后者为确定正确的产品目标 (Product Goal) 创造了环境.同样,每个产品目标作为识别有用的冲刺目标的基础.换句话说, ...
- Azure Databricks - [02] 常用SQL
查看当前所在catalog:select current_catalog(); 创建catalog:create catalog if not exists harley_test; 创建表 crea ...
- 入口函数与包初始化:Go程序的执行次序
前言 我们可能经常会遇到这样一个问题:一个 Go 项目中有数十个 Go 包,每个包中又有若干常量.变量.各种函数和方法,那 Go 代码究竟是从哪里开始执行的呢?后续的执行顺序又是什么样的呢? 事实上, ...
- markdown设置目录、锚点
目录 在编辑时正确使用标题,在段首输入[toc]即可 锚点 创建到命名锚记的链接的过程分为两步: 首先是建立一个跳转的连接: [说明文字](#jump) 然后标记要跳转到什么位置,注意id要与之前(# ...
- SpringBoot原理分析-1
SpringBoot原理分析 作为一个javaer,和boot打交道是很常见的吧.熟悉boot的人都会知道,启动一个springboot应用,就是用鼠标点一下启动main方法,然后等着就行了.我们来看 ...
- 冒泡排序(LOW)
博客地址:https://www.cnblogs.com/zylyehuo/ # _*_coding:utf-8_*_ import random def bubble_sort(li): for i ...
- linux 查看jdk安装路径
[root@iz2ze9ufq5ehrayz6j88saz bin]# java -version java version "1.8.0_191" Java(TM) SE Run ...
- 启动oracle 服务
-- 参考(https://blog.csdn.net/loongshawn/article/details/51162196) 1.启动oracle的步骤 Linux下启动oracle分为以下两步: ...